9. 分散式系統的麻煩
意外這東西挺有意思:你沒碰上之前,它就從來不會發生。
A.A. 米爾恩,《小熊維尼和老灰驢的家》(1928)
正如 “可靠性與容錯” 中所討論的,讓系統可靠意味著確保系統作為一個整體繼續工作,即使出了問題(即出現故障)。然而,預料所有可能的故障並處理它們並不是那麼容易。作為開發者,我們很容易主要關注正常路徑(畢竟,大多數時候事情都執行良好!)而忽略故障,因為故障會引入大量邊界情況。
如果你希望系統在故障存在的情況下仍然可靠,你必須從根本上改變你的思維方式,並專注於可能出錯的事情,即使它們可能性很低。一件事情出錯的機率是否只有百萬分之一並不重要:在一個足夠大的系統中,百萬分之一的事件每天都在發生。經驗豐富的系統操作員會告訴你,任何 可能 出錯的事情 都會 出錯。
此外,使用分散式系統與在單臺計算機上編寫軟體有著根本的不同 —— 主要區別在於有許多新的、令人興奮的出錯方式 1 2。在本章中,你將體驗實踐中出現的問題,並理解你可以依賴和不能依賴的事物。
為了理解我們面臨的挑戰,我們現在將把悲觀情緒發揮到極致,探索分散式系統中可能出錯的事情。我們將研究網路問題(“不可靠的網路”)以及時鐘和時序問題(“不可靠的時鐘”)。所有這些問題的後果令人迷惑,因此我們將探索如何思考分散式系統的狀態以及如何推理已經發生的事情(“知識、真相與謊言”)。稍後,在 第 10 章 中,我們將看一些面對這些故障時如何實現容錯的例子。
故障與部分失效
當你在單臺計算機上編寫程式時,它通常以相當可預測的方式執行:要麼工作,要麼不工作。有缺陷的軟體可能會給人一種計算機有時 “狀態不佳” 的印象(這個問題通常透過重啟來解決),但這主要只是編寫不良的軟體的後果。
軟體在單臺計算機上不應該是不穩定的,這沒有根本原因:當硬體正常工作時,相同的操作總是產生相同的結果(它是 確定性的)。如果存在硬體問題(例如,記憶體損壞或聯結器鬆動),後果通常是整個系統故障(例如,核心恐慌、“藍色畫面宕機”、無法啟動)。一臺執行良好軟體的單獨計算機通常要麼完全正常執行,要麼完全故障,而不是介於兩者之間。
這是計算機設計中的一個刻意選擇:如果發生內部故障,我們寧願計算機完全崩潰而不是返回錯誤的結果,因為錯誤的結果很難處理且令人困惑。因此,計算機隱藏了它們所實現的模糊物理現實,並呈現一個以數學完美執行的理想化系統模型。CPU 指令總是做同樣的事情;如果你將一些資料寫入記憶體或磁碟,該資料保持完整,不會被隨機損壞。正如 “硬體與軟體故障” 中所討論的,這實際上並不是真的 —— 實際上,資料確實會被靜默損壞,CPU 有時會靜默返回錯誤的結果 —— 但這種情況發生得足夠少,以至於我們可以忽略它。
當你編寫在多臺計算機上執行的軟體,透過網路連線時,情況就根本不同了。在分散式系統中,故障發生得更加頻繁,因此我們不能再忽略它們 —— 我們別無選擇,只能直面物理世界的混亂現實。在物理世界中,可能出錯的事情範圍非常廣泛,正如這個軼事所說明的 3:
在我有限的經驗中,我處理過單個數據中心(DC)中的長期網路分割槽、PDU [配電單元] 故障、交換機故障、整個機架的意外斷電、整個 DC 骨幹網故障、整個 DC 電源故障,以及一個低血糖的司機將他的福特皮卡撞進 DC 的 HVAC [供暖、通風和空調] 系統。而我甚至不是運維人員。
—— Coda Hale
在分散式系統中,系統的某些部分可能以某種不可預測的方式出現故障,即使系統的其他部分工作正常。這被稱為 部分失效。困難在於部分失效是 非確定性的:如果你嘗試做任何涉及多個節點和網路的事情,它有時可能工作,有時可能不可預測地失敗。正如我們將看到的,你甚至可能不 知道 某事是否成功!
這種非確定性和部分失效的可能性使分散式系統難以使用 4。另一方面,如果分散式系統可以容忍部分失效,這將開啟強大的可能性:例如,它允許你執行滾動升級,一次重啟一個節點以安裝軟體更新,而系統作為一個整體繼續不間斷地工作。因此,容錯使我們能夠從不可靠的元件構建比單節點系統更可靠的分散式系統。
但在我們實現容錯之前,我們需要更多地瞭解我們應該容忍的故障。重要的是要考慮各種可能的故障 —— 即使是相當不太可能的故障 —— 並在你的測試環境中人為地建立這種情況以檢視會發生什麼。在分散式系統中,懷疑、悲觀和偏執是有回報的。
不可靠的網路
正如 “共享記憶體、共享磁碟和無共享架構” 中所討論的,我們在本書中關注的分散式系統主要是 無共享系統:即透過網路連線的一組機器。網路是這些機器進行通訊的唯一方式 —— 我們假設每臺機器都有自己的記憶體和磁碟,一臺機器不能訪問另一臺機器的記憶體或磁碟(除非透過網路向服務發出請求)。即使儲存是共享的,例如亞馬遜的 S3,機器也是透過網路與共享儲存服務通訊。
網際網路和資料中心中的大多數內部網路(通常是乙太網)都是 非同步分組網路。在這種網路中,一個節點可以向另一個節點發送訊息(資料包),但網路不保證它何時到達,或者是否會到達。如果你傳送請求並期望響應,許多事情可能會出錯(其中一些如 圖 9-1 所示):
- 你的請求可能已經丟失(也許有人拔掉了網線)。
- 你的請求可能在佇列中等待,稍後將被交付(也許網路或接收方過載)。
- 遠端節點可能已經失效(也許它崩潰了或被關閉了)。
- 遠端節點可能暫時停止響應(也許它正在經歷長時間的垃圾回收暫停;見 “程序暫停”),但稍後會再次開始響應。
- 遠端節點可能已經處理了你的請求,但響應在網路上丟失了(也許網路交換機配置錯誤)。
- 遠端節點可能已經處理了你的請求,但響應被延遲了,稍後將被交付(也許網路或你自己的機器過載)。
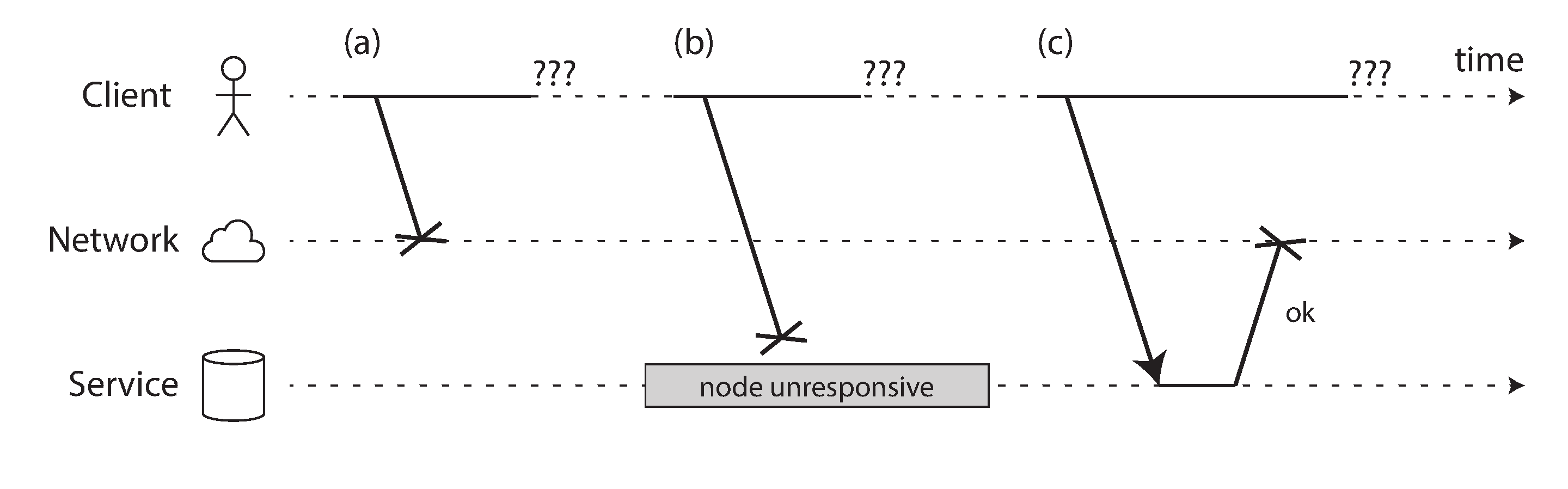
傳送方甚至無法判斷資料包是否已交付:唯一的選擇是讓接收方傳送響應訊息,而響應訊息本身也可能丟失或延遲。在非同步網路中,這些問題是無法區分的:你擁有的唯一資訊是你還沒有收到響應。如果你向另一個節點發送請求但沒有收到響應,不可能 判斷原因。
處理這個問題的常用方法是 超時:在一段時間後,你放棄等待並假設響應不會到達。然而,當超時發生時,你仍然不知道遠端節點是否收到了你的請求(如果請求仍在某處排隊,即使傳送方已經放棄了它,它仍可能被交付給接收方)。
TCP 的侷限性
網路資料包有最大大小(通常為幾千位元組),但許多應用程式需要傳送太大而無法裝入一個數據包的訊息(請求、響應)。這些應用程式最常使用 TCP(傳輸控制協議)來建立一個 連線,將大型資料流分解為單個數據包,並在接收端將它們重新組合起來。
Note
我們關於 TCP 的大部分內容也適用於其更新的替代方案 QUIC,以及 WebRTC 中使用的流控制傳輸協議(SCTP)、BitTorrent uTP 協議和其他傳輸協議。有關與 UDP 的比較,請參見 “TCP 與 UDP”。
TCP 通常被描述為提供 “可靠” 的交付,從某種意義上說,它檢測並重傳丟棄的資料包,檢測重新排序的資料包並將它們恢復到正確的順序,並使用簡單的校驗和檢測資料包損壞。它還計算出可以傳送資料的速度,以便儘快傳輸資料,但不會使網路或接收節點過載;這被稱為 擁塞控制、流量控制 或 背壓 5。
當你透過將資料寫入套接字來 “傳送” 一些資料時,它實際上不會立即傳送,而只是放置在由作業系統管理的緩衝區中。當擁塞控制演算法決定它有能力傳送資料包時,它會從該緩衝區中獲取下一個資料包的資料並將其傳遞給網路介面。資料包通過幾個交換機和路由器,最終接收節點的作業系統將資料包的資料放置在接收緩衝區中並向傳送方傳送確認資料包。只有這樣,接收作業系統才會通知應用程式有更多資料到達 6。
那麼,如果 TCP 提供 “可靠性”,這是否意味著我們不再需要擔心網路不可靠?不幸的是不是。如果在某個超時時間內沒有收到確認,它會認為資料包一定已經丟失,但 TCP 也無法判斷是出站資料包還是確認丟失了。儘管 TCP 可以重新發送資料包,但它不能保證新資料包也會透過。如果網線被拔掉,TCP 不能為你重新插上它。最終,在可配置的超時後,TCP 放棄並嚮應用程式發出錯誤訊號。
如果 TCP 連線因錯誤而關閉 —— 也許是因為遠端節點崩潰了,或者是因為網路被中斷了 —— 你不幸地無法知道遠端節點實際處理了多少資料 6。即使 TCP 確認資料包已交付,這也僅意味著遠端節點上的作業系統核心收到了它,但應用程式可能在處理該資料之前就崩潰了。如果你想確保請求成功,你需要應用層返回明確的成功響應 7。
儘管如此,TCP 非常有用,因為它提供了一種方便的方式來發送和接收太大而無法裝入一個數據包的訊息。一旦建立了 TCP 連線,你還可以使用它來發送多個請求和響應。這通常是透過首先發送一個標頭來完成的,該標頭以位元組為單位指示後續訊息的長度,然後是實際訊息。HTTP 和許多 RPC 協議(見 “透過服務的資料流:REST 和 RPC”)就是這樣工作的。
實踐中的網路故障
我們已經建立計算機網路幾十年了 —— 人們可能希望到現在我們已經弄清楚如何使它們可靠。不幸的是,我們還沒有成功。有一些系統研究和大量軼事證據表明,網路問題可能出人意料地常見,即使在由一家公司運營的受控環境(如資料中心)中也是如此 8:
- 一項在中型資料中心的研究發現,每月約有 12 次網路故障,其中一半斷開了單臺機器,一半斷開了整個機架 9。
- 另一項研究測量了元件(如機架頂部交換機、匯聚交換機和負載均衡器)的故障率 10。它發現,新增冗餘網路裝置並不能像你希望的那樣減少故障,因為它不能防範人為錯誤(例如,配置錯誤的交換機),這是停機的主要原因。
- 廣域光纖鏈路的中斷被歸咎於奶牛 11、海狸 12 和鯊魚 13(儘管由於海底電纜遮蔽更好,鯊魚咬傷已經變得更加罕見 14)。人類也有過錯,無論是由於意外配置錯誤 15、拾荒 16 還是破壞 17。
- 在不同的雲區域之間,已經觀察到高百分位數下長達幾 分鐘 的往返時間 18。即使在單個數據中心內,在網路拓撲重新配置期間(由交換機軟體升級期間的問題觸發),也可能發生超過一分鐘的資料包延遲 19。因此,我們必須假設訊息可能被任意延遲。
- 有時通訊部分中斷,這取決於你在和誰交談:例如,A 和 B 可以通訊,B 和 C 可以通訊,但 A 和 C 不能 20 21。其他令人驚訝的故障包括網路介面有時會丟棄所有入站資料包但成功傳送出站資料包 22:僅僅因為網路鏈路在一個方向上工作並不能保證它在相反方向上也工作。
- 即使是短暫的網路中斷也可能產生比原始問題持續時間更長的影響 8 20 23。
網路分割槽
當網路的一部分由於網路故障而與其餘部分隔離時,有時稱為 網路分割槽 或 網路分裂,但它與其他型別的網路中斷沒有根本區別。網路分割槽與儲存系統的分片無關,後者有時也稱為 分割槽(見 第 7 章)。
即使網路故障在你的環境中很少見,故障 可能 發生的事實意味著你的軟體需要能夠處理它們。每當透過網路進行任何通訊時,它都可能失敗 —— 這是無法避免的。
如果網路故障的錯誤處理沒有定義和測試,可能會發生任意糟糕的事情:例如,叢集可能會陷入死鎖並永久無法提供請求,即使網路恢復 24,或者它甚至可能刪除你的所有資料 25。如果軟體處於意料之外的情況,它可能會做任意意外的事情。
處理網路故障不一定意味著 容忍 它們:如果你的網路通常相當可靠,一個有效的方法可能是在網路出現問題時簡單地向用戶顯示錯誤訊息。但是,你確實需要知道你的軟體如何對網路問題做出反應,並確保系統可以從中恢復。故意觸發網路問題並測試系統的響應可能是有意義的(這被稱為 故障注入;見 “故障注入”)。
檢測故障
許多系統需要自動檢測故障節點。例如:
- 負載均衡器需要停止向已死亡的節點發送請求(即,將其 從輪詢池中摘除)。
- 在具有單主複製的分散式資料庫中,如果主節點失效,其中一個從節點需要被提升為新的主節點(見 “處理節點中斷”)。
不幸的是,網路的不確定性使得很難判斷節點是否正常工作。在某些特定情況下,你可能會得到一些明確告訴你某事不工作的反饋:
- 如果你可以訪問節點應該執行的機器,但沒有程序監聽目標埠(例如,因為程序崩潰了),作業系統將透過傳送
RST或FIN資料包來幫助關閉或拒絕 TCP 連線。 - 如果節點程序崩潰(或被管理員殺死)但節點的作業系統仍在執行,指令碼可以通知其他節點有關崩潰的資訊,以便另一個節點可以快速接管而無需等待超時到期。例如,HBase 就是這樣做的 26。
- 如果你可以訪問資料中心中網路交換機的管理介面,你可以查詢它們以在硬體級別檢測鏈路故障(例如,如果遠端機器已關閉電源)。如果你透過網際網路連線,或者你在共享資料中心中無法訪問交換機本身,或者由於網路問題無法訪問管理介面,則此選項被排除。
- 如果路由器確定你嘗試連線的 IP 地址不可達,它可能會向你回覆 ICMP 目標不可達資料包。然而,路由器也沒有神奇的故障檢測能力 —— 它受到與網路其他參與者相同的限制。
關於遠端節點宕機的快速反饋很有用,但你不能指望它。如果出了問題,你可能會在堆疊的某個級別收到錯誤響應,但通常你必須假設你根本不會收到任何響應。你可以重試幾次,等待超時過去,如果在超時內沒有收到回覆,最終宣佈節點死亡。
超時和無界延遲
如果超時是檢測故障的唯一可靠方法,那麼超時應該多長?不幸的是,沒有簡單的答案。
長超時意味著在節點被宣佈死亡之前需要長時間等待(在此期間,使用者可能不得不等待或看到錯誤訊息)。短超時可以更快地檢測故障,但當節點實際上只是遭受暫時的減速(例如,由於節點或網路上的負載峰值)時,錯誤地宣佈節點死亡的風險更高。
過早地宣佈節點死亡是有問題的:如果節點實際上是活著的並且正在執行某些操作(例如,傳送電子郵件),而另一個節點接管,該操作可能最終被執行兩次。我們將在 “知識、真相與謊言” 以及第 10 章和後續章節中更詳細地討論這個問題。
當節點被宣佈死亡時,其職責需要轉移到其他節點,這會給其他節點和網路帶來額外的負載。如果系統已經在高負載下掙扎,過早地宣佈節點死亡可能會使問題變得更糟。特別是,可能發生的情況是,節點實際上並沒有死亡,只是由於過載而響應緩慢;將其負載轉移到其他節點可能會導致級聯故障(在極端情況下,所有節點互相宣佈對方死亡,一切都停止工作 —— 見 “當過載系統無法恢復時”)。
想象一個虛構的系統,其網路保證資料包的最大延遲 —— 每個資料包要麼在某個時間 d 內交付,要麼丟失,但交付從不會超過 d。此外,假設你可以保證未失效的節點總是在某個時間 r 內處理請求。在這種情況下,你可以保證每個成功的請求在時間 2d + r 內收到響應 —— 如果你在該時間內沒有收到響應,你就知道網路或遠端節點不工作。如果這是真的,2d + r 將是一個合理的超時時間。
不幸的是,我們使用的大多數系統都沒有這些保證:非同步網路具有 無界延遲(即,它們嘗試儘快交付資料包,但資料包到達所需的時間沒有上限),大多數伺服器實現無法保證它們可以在某個最大時間內處理請求(見 “響應時間保證”)。對於故障檢測,系統大部分時間快速執行是不夠的:如果你的超時很低,往返時間的瞬時峰值就足以使系統失去平衡。
網路擁塞和排隊
開車時,道路網路上的行駛時間通常因交通擁堵而變化最大。同樣,計算機網路上資料包延遲的可變性最常是由於排隊 27:
- 如果幾個不同的節點同時嘗試向同一目的地傳送資料包,網路交換機必須將它們排隊並逐個送入目標網路鏈路(如 圖 9-2 所示)。在繁忙的網路鏈路上,資料包可能需要等待一段時間才能獲得一個插槽(這稱為 網路擁塞)。如果有太多的傳入資料以至於交換機佇列滿了,資料包將被丟棄,因此需要重新發送 —— 即使網路執行正常。
- 當資料包到達目標機器時,如果所有 CPU 核心當前都很忙,來自網路的傳入請求會被作業系統排隊,直到應用程式準備處理它。根據機器上的負載,這可能需要任意長的時間 28。
- 在虛擬化環境中,正在執行的作業系統經常會暫停幾十毫秒,而另一個虛擬機器使用 CPU 核心。在此期間,VM 無法消耗來自網路的任何資料,因此傳入資料由虛擬機器監視器排隊(緩衝)29,進一步增加了網路延遲的可變性。
- 如前所述,為了避免網路過載,TCP 限制傳送資料的速率。這意味著在資料甚至進入網路之前,傳送方就有額外的排隊。
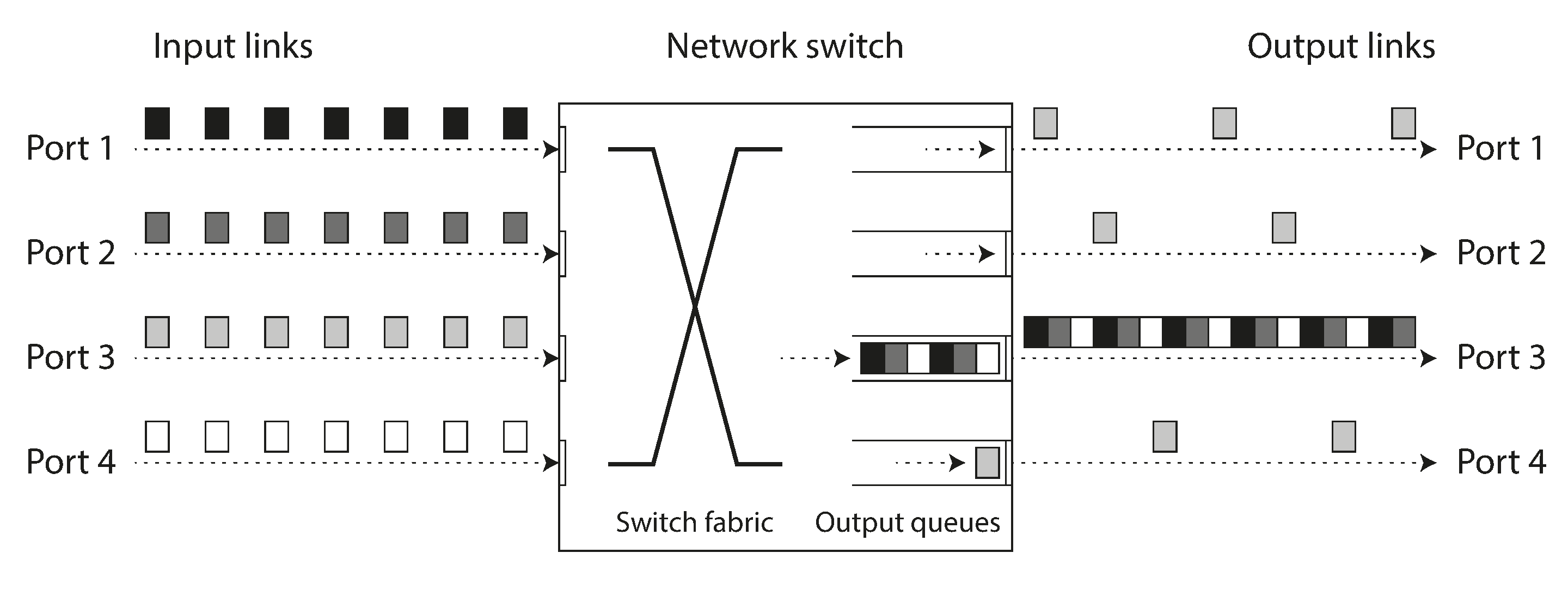
此外,當 TCP 檢測到並自動重傳丟失的資料包時,儘管應用程式不會直接看到資料包丟失,但它確實會看到由此產生的延遲(等待超時到期,然後等待重傳的資料包被確認)。
TCP 與 UDP
一些對延遲敏感的應用程式,如視訊會議和 IP 語音(VoIP),使用 UDP 而不是 TCP。這是可靠性和延遲可變性之間的權衡:由於 UDP 不執行流量控制並且不重傳丟失的資料包,它避免了網路延遲可變的一些原因(儘管它仍然容易受到交換機佇列和排程延遲的影響)。
UDP 是延遲資料無價值的情況下的好選擇。例如,在 VoIP 電話通話中,在資料應該透過揚聲器播放之前,可能沒有足夠的時間重傳丟失的資料包。在這種情況下,重傳資料包沒有意義 —— 應用程式必須用靜音填充缺失資料包的時間槽(導致聲音短暫中斷)並繼續流。重試發生在人類層面。(“你能重複一下嗎?聲音剛剛中斷了一會兒。")
所有這些因素都導致了網路延遲的可變性。當系統接近其最大容量時,排隊延遲的範圍特別大:具有充足備用容量的系統可以輕鬆排空佇列,而在高度利用的系統中,長佇列可以很快建立起來。
在公共雲和多租戶資料中心中,資源在許多客戶之間共享:網路鏈路和交換機,甚至每臺機器的網路介面和 CPU(在虛擬機器上執行時)都是共享的。處理大量資料可以使用網路鏈路的全部容量(飽和 它們)。由於你無法控制或瞭解其他客戶對共享資源的使用情況,如果你附近的某人(吵鬧的鄰居)正在使用大量資源,網路延遲可能會高度可變 30 31。
在這種環境中,你只能透過實驗選擇超時:在較長時間內和許多機器上測量網路往返時間的分佈,以確定延遲的預期可變性。然後,考慮到你的應用程式的特徵,你可以在故障檢測延遲和過早超時風險之間確定適當的權衡。
更好的是,系統可以持續測量響應時間及其可變性(抖動),並根據觀察到的響應時間分佈自動調整超時,而不是使用配置的常量超時。Phi 累積故障檢測器 32(例如在 Akka 和 Cassandra 中使用 33)就是這樣做的一種方法。TCP 重傳超時也以類似的方式工作 5。
同步與非同步網路
如果我們可以依靠網路以某個固定的最大延遲交付資料包,並且不丟棄資料包,分散式系統將會簡單得多。為什麼我們不能在硬體級別解決這個問題,使網路可靠,這樣軟體就不需要擔心它了?
要回答這個問題,比較資料中心網路與傳統的固定電話網路(非蜂窩、非 VoIP)很有趣,後者極其可靠:延遲的音訊幀和掉線非常罕見。電話通話需要持續的低端到端延遲和足夠的頻寬來傳輸你聲音的音訊樣本。在計算機網路中擁有類似的可靠性和可預測性不是很好嗎?
當你透過電話網路撥打電話時,它會建立一個 電路:在兩個呼叫者之間的整個路線上分配固定、有保證的頻寬量。該電路一直保持到通話結束 34。例如,ISDN 網路以每秒 4,000 幀的固定速率執行。建立呼叫時,它在每幀內(在每個方向上)分配 16 位空間。因此,在通話期間,每一方都保證能夠每 250 微秒準確傳送 16 位音訊資料 35。
這種網路是 同步的:即使資料通過幾個路由器,它也不會遭受排隊,因為呼叫的 16 位空間已經在網路的下一跳中預留了。由於沒有排隊,網路的最大端到端延遲是固定的。我們稱之為 有界延遲。
我們不能簡單地使網路延遲可預測嗎?
請注意,電話網路中的電路與 TCP 連線非常不同:電路是固定數量的預留頻寬,在電路建立期間其他人無法使用,而 TCP 連線的資料包則機會主義地使用任何可用的網路頻寬。你可以給 TCP 一個可變大小的資料塊(例如,電子郵件或網頁),它會嘗試在儘可能短的時間內傳輸它。當 TCP 連線空閒時,它不使用任何頻寬(除了偶爾的保活資料包)。
如果資料中心網路和網際網路是電路交換網路,那麼在建立電路時就可以建立有保證的最大往返時間。然而,它們不是:乙太網和 IP 是分組交換協議,會遭受排隊,因此在網路中有無界延遲。這些協議沒有電路的概念。
為什麼資料中心網路和網際網路使用分組交換?答案是它們針對 突發流量 進行了最佳化。電路適合音訊或視訊通話,需要在通話期間傳輸相當恆定的每秒位數。另一方面,請求網頁、傳送電子郵件或傳輸檔案沒有任何特定的頻寬要求 —— 我們只希望它儘快完成。
如果你想透過電路傳輸檔案,你必須猜測頻寬分配。如果你猜得太低,傳輸會不必要地慢,使網路容量未被使用。如果你猜得太高,電路無法建立(因為如果無法保證其頻寬分配,網路無法允許建立電路)。因此,使用電路進行突發資料傳輸會浪費網路容量並使傳輸不必要地緩慢。相比之下,TCP 動態調整資料傳輸速率以適應可用的網路容量。
曾經有一些嘗試構建既支援電路交換又支援分組交換的混合網路。非同步傳輸模式(ATM)在 1980 年代是乙太網的競爭對手,但除了電話網路核心交換機外,它沒有獲得太多采用。InfiniBand 有一些相似之處 36:它在鏈路層實現端到端流量控制,減少了網路中排隊的需要,儘管它仍然可能因鏈路擁塞而遭受延遲 37。透過仔細使用 服務質量(QoS,資料包的優先順序和排程)和 准入控制(對傳送者的速率限制),可以在分組網路上類比電路交換,或提供統計上有界的延遲 27 34。新的網路演算法,如低延遲、低損耗和可擴充套件吞吐量(L4S)試圖在客戶端和路由器級別緩解一些排隊和擁塞控制問題。Linux 的流量控制器(TC)也允許應用程式為 QoS 目的重新優先排序資料包。
延遲和資源利用率
更一般地說,你可以將可變延遲視為動態資源分割槽的結果。
假設你在兩個電話交換機之間有一條可以承載多達 10,000 個同時呼叫的線路。透過此線路交換的每個電路都佔用其中一個呼叫插槽。因此,你可以將該線路視為最多可由 10,000 個同時使用者共享的資源。資源以 靜態 方式劃分:即使你現在是線路上唯一的呼叫,並且所有其他 9,999 個插槽都未使用,你的電路仍然分配與線路完全利用時相同的固定頻寬量。
相比之下,網際網路 動態 共享網路頻寬。傳送者互相推擠,儘可能快地透過線路傳送資料包,網路交換機決定在每個時刻傳送哪個資料包(即頻寬分配)。這種方法的缺點是排隊,但優點是它最大化了線路的利用率。線路有固定成本,所以如果你更好地利用它,你透過線路傳送的每個位元組都更便宜。
CPU 也會出現類似的情況:如果你在幾個執行緒之間動態共享每個 CPU 核心,一個執行緒有時必須在作業系統的執行佇列中等待,而另一個執行緒正在執行,因此執行緒可能會暫停不同的時間長度 38。然而,這比為每個執行緒分配靜態數量的 CPU 週期更好地利用硬體(見 “響應時間保證”)。更好的硬體利用率也是雲平臺在同一物理機器上執行來自不同客戶的多個虛擬機器的原因。
如果資源是靜態分割槽的(例如,專用硬體和獨佔頻寬分配),則在某些環境中可以實現延遲保證。然而,這是以降低利用率為代價的 —— 換句話說,它更昂貴。另一方面,具有動態資源分割槽的多租戶提供了更好的利用率,因此更便宜,但它有可變延遲的缺點。
網路中的可變延遲不是自然法則,而只是成本/收益權衡的結果。
然而,這種服務質量目前在多租戶資料中心和公共雲中未啟用,或者在透過網際網路通訊時未啟用。當前部署的技術不允許我們對網路的延遲或可靠性做出任何保證:我們必須假設網路擁塞、排隊和無界延遲會發生。因此,超時沒有 “正確” 的值 —— 它們需要透過實驗確定。
網際網路服務提供商之間的對等協議和透過邊界閘道器協議(BGP)建立路由,比 IP 本身更接近電路交換。在這個級別,可以購買專用頻寬。然而,網際網路路由在網路級別而不是主機之間的單個連線上執行,並且時間尺度要長得多。
不可靠的時鐘
時鐘和時間很重要。應用程式以各種方式依賴時鐘來回答如下問題:
- 這個請求超時了嗎?
- 這項服務的第 99 百分位響應時間是多少?
- 這項服務在過去五分鐘內平均每秒處理了多少查詢?
- 使用者在我們的網站上花了多長時間?
- 這篇文章是什麼時候發表的?
- 提醒郵件應該在什麼日期和時間傳送?
- 這個快取條目何時過期?
- 日誌檔案中此錯誤訊息的時間戳是什麼?
示例 1-4 測量 持續時間(例如,傳送請求和接收響應之間的時間間隔),而示例 5-8 描述 時間點(在特定日期、特定時間發生的事件)。
在分散式系統中,時間是一件棘手的事情,因為通訊不是瞬時的:訊息從一臺機器透過網路傳輸到另一臺機器需要時間。接收訊息的時間總是晚於傳送訊息的時間,但由於網路中的可變延遲,我們不知道晚了多少。當涉及多臺機器時,這個事實有時會使確定事情發生的順序變得困難。
此外,網路上的每臺機器都有自己的時鐘,這是一個實際的硬體裝置:通常是石英晶體振盪器。這些裝置並不完全準確,因此每臺機器都有自己的時間概念,可能比其他機器稍快或稍慢。可以在某種程度上同步時鐘:最常用的機制是網路時間協議(NTP),它允許根據一組伺服器報告的時間調整計算機時鐘 39。伺服器反過來從更準確的時間源(如 GPS 接收器)獲取時間。
單調時鐘與日曆時鐘
現代計算機至少有兩種不同型別的時鐘:日曆時鐘 和 單調時鐘。儘管它們都測量時間,但區分兩者很重要,因為它們服務於不同的目的。
日曆時鐘
日曆時鐘做你直觀期望時鐘做的事情:它根據某個日曆返回當前日期和時間(也稱為 牆上時鐘時間)。例如,Linux 上的 clock_gettime(CLOCK_REALTIME) 和 Java 中的 System.currentTimeMillis() 返回自 紀元 以來的秒數(或毫秒數):根據格里高利曆,1970 年 1 月 1 日午夜 UTC,不計算閏秒。一些系統使用其他日期作為參考點。(儘管 Linux 時鐘被稱為 即時,但它與即時作業系統無關,如 “響應時間保證” 中所討論的。)
日曆時鐘通常與 NTP 同步,這意味著來自一臺機器的時間戳(理想情況下)與另一臺機器上的時間戳意思相同。然而,日曆時鐘也有各種奇怪之處,如下一節所述。特別是,如果本地時鐘遠遠超前於 NTP 伺服器,它可能會被強制重置並顯示跳回到以前的時間點。這些跳躍,以及閏秒引起的類似跳躍,使日曆時鐘不適合測量經過的時間 40。
日曆時鐘可能會因夏令時(DST)的開始和結束而經歷跳躍;這些可以透過始終使用 UTC 作為時區來避免,UTC 沒有 DST。日曆時鐘在歷史上也具有相當粗粒度的解析度,例如,在較舊的 Windows 系統上以 10 毫秒的步長前進 41。在最近的系統上,這不再是一個問題。
單調時鐘
單調時鐘適用於測量持續時間(時間間隔),例如超時或服務的響應時間:例如,Linux 上的 clock_gettime(CLOCK_MONOTONIC) 或 clock_gettime(CLOCK_BOOTTIME) 42 和 Java 中的 System.nanoTime() 是單調時鐘。這個名字來源於它們保證始終向前移動的事實(而日曆時鐘可能會在時間上向後跳躍)。
你可以在某個時間點檢查單調時鐘的值,做一些事情,然後在稍後的時間再次檢查時鐘。兩個值之間的 差值 告訴你兩次檢查之間經過了多少時間 —— 更像秒錶而不是掛鐘。然而,時鐘的 絕對 值是沒有意義的:它可能是自計算機啟動以來的納秒數,或類似的任意值。特別是,比較來自兩臺不同計算機的單調時鐘值是沒有意義的,因為它們不代表同樣的東西。
在具有多個 CPU 插槽的伺服器上,每個 CPU 可能有一個單獨的計時器,它不一定與其他 CPU 同步 43。作業系統會補償任何差異,並嘗試嚮應用程式執行緒呈現時鐘的單調檢視,即使它們被排程到不同的 CPU 上。然而,明智的做法是對這種單調性保證持保留態度 44。
如果 NTP 檢測到計算機的本地石英晶體比 NTP 伺服器執行得更快或更慢,它可能會調整單調時鐘前進的頻率(這被稱為 調整 時鐘)。預設情況下,NTP 允許時鐘速率加速或減速高達 0.05%,但 NTP 不能導致單調時鐘向前或向後跳躍。單調時鐘的解析度通常相當好:在大多數系統上,它們可以測量微秒或更短的時間間隔。
在分散式系統中,使用單調時鐘測量經過的時間(例如,超時)通常是可以的,因為它不假設不同節點的時鐘之間有任何同步,並且對測量的輕微不準確不敏感。
時鐘同步和準確性
單調時鐘不需要同步,但日曆時鐘需要根據 NTP 伺服器或其他外部時間源設定才能有用。不幸的是,我們讓時鐘顯示正確時間的方法遠不如你希望的那樣可靠或準確 —— 硬體時鐘和 NTP 可能是反覆無常的野獸。僅舉幾個例子:
- 計算機中的石英時鐘不是很準確:它會 漂移(比應該的執行得更快或更慢)。時鐘漂移因機器的溫度而異。Google 假設其伺服器的時鐘漂移高達 200 ppm(百萬分之一)45,這相當於每 30 秒與伺服器重新同步的時鐘有 6 毫秒漂移,或每天重新同步一次的時鐘有 17 秒漂移。即使一切正常工作,這種漂移也限制了你可以達到的最佳精度。
- 如果計算機的時鐘與 NTP 伺服器相差太多,它可能會拒絕同步,或者本地時鐘將被強制重置 39。任何在重置前後觀察時間的應用程式都可能看到時間倒退或突然向前跳躍。
- 如果節點意外地被防火牆與 NTP 伺服器隔離,配置錯誤可能會在一段時間內未被注意到,在此期間漂移可能會累積成不同節點時鐘之間的巨大差異。軼事證據表明,這在實踐中確實會發生。
- NTP 同步只能與網路延遲一樣好,因此當你在具有可變資料包延遲的擁塞網路上時,其準確性有限。一項實驗表明,透過網際網路同步時可以達到 35 毫秒的最小誤差 46,儘管網路延遲的偶爾峰值會導致大約一秒的誤差。根據配置,大的網路延遲可能導致 NTP 客戶端完全放棄。
- 一些 NTP 伺服器是錯誤的或配置錯誤的,報告的時間相差數小時 47 48。NTP 客戶端透過查詢多個伺服器並忽略異常值來減輕此類錯誤。儘管如此,將系統的正確性押注在網際網路上陌生人告訴你的時間上還是有些令人擔憂的。
- 閏秒導致一分鐘有 59 秒或 61 秒長,這會搞亂在設計時沒有考慮閏秒的系統中的時序假設 49。閏秒已經導致許多大型系統崩潰的事實 40 50 表明,關於時鐘的錯誤假設是多麼容易潛入系統。處理閏秒的最佳方法可能是讓 NTP 伺服器 “撒謊”,透過在一天的過程中逐漸執行閏秒調整(這被稱為 平滑)51 52,儘管實際的 NTP 伺服器行為在實踐中有所不同 53。從 2035 年起將不再使用閏秒,所以這個問題幸運地將會消失。
- 在虛擬機器中,硬體時鐘是虛擬化的,這為需要準確計時的應用程式帶來了額外的挑戰 54。當 CPU 核心在虛擬機器之間共享時,每個 VM 在另一個 VM 執行時會暫停數十毫秒。從應用程式的角度來看,這種暫停表現為時鐘突然向前跳躍 29。如果 VM 暫停幾秒鐘,時鐘可能會比實際時間落後幾秒鐘,但 NTP 可能會繼續報告時鐘幾乎完全同步 55。
- 如果你在不完全控制的裝置上執行軟體(例如,移動或嵌入式裝置),你可能根本無法信任裝置的硬體時鐘。一些使用者故意將他們的硬體時鐘設定為不正確的日期和時間,例如在遊戲中作弊 56。因此,時鐘可能被設定為遙遠的過去或未來的時間。
如果你足夠關心時鐘精度並願意投入大量資源,就可以實現非常好的時鐘精度。例如,歐洲金融機構的 MiFID II 法規要求所有高頻交易基金將其時鐘同步到 UTC 的 100 微秒以內,以幫助除錯市場異常(如 “閃崩”)並幫助檢測市場操縱 57。
這種精度可以透過一些特殊硬體(GPS 接收器和/或原子鐘)、精確時間協議(PTP)以及仔細的部署和監控來實現 58 59。僅依賴 GPS 可能有風險,因為 GPS 訊號很容易被幹擾。在某些地方,這種情況經常發生,例如靠近軍事設施 60。一些雲提供商已經開始為其虛擬機器提供高精度時鐘同步 61。然而,時鐘同步仍然需要很多注意。如果你的 NTP 守護程序配置錯誤,或者防火牆阻止了 NTP 流量,由於漂移導致的時鐘誤差可能會迅速變大。
對同步時鐘的依賴
時鐘的問題在於,雖然它們看起來簡單易用,但它們有驚人數量的陷阱:一天可能沒有正好 86,400 秒,日曆時鐘可能會在時間上向後移動,根據一個節點的時鐘的時間可能與另一個節點的時鐘相差很大。
本章前面我們討論了網路丟棄和任意延遲資料包。即使網路大部分時間表現良好,軟體也必須設計成假設網路偶爾會出現故障,軟體必須優雅地處理此類故障。時鐘也是如此:儘管它們大部分時間工作得很好,但強健的軟體需要準備好處理不正確的時鐘。
問題的一部分是不正確的時鐘很容易被忽視。如果機器的 CPU 有缺陷或其網路配置錯誤,它很可能根本無法工作,因此會很快被注意到並修復。另一方面,如果它的石英時鐘有缺陷或其 NTP 客戶端配置錯誤,大多數事情看起來會正常工作,即使它的時鐘逐漸偏離現實越來越遠。如果某些軟體依賴於準確同步的時鐘,結果更可能是靜默和微妙的資料丟失,而不是戲劇性的崩潰 62 63。
因此,如果你使用需要同步時鐘的軟體,你還必須仔細監控所有機器之間的時鐘偏移。任何時鐘偏離其他節點太遠的節點都應該被宣佈死亡並從叢集中移除。這種監控確保你在損壞的時鐘造成太多損害之前注意到它們。
用於事件排序的時間戳
讓我們考慮一個特定的情況,其中依賴時鐘是誘人但危險的:跨多個節點的事件排序 64。例如,如果兩個客戶端寫入分散式資料庫,誰先到達?哪個寫入是更新的?
圖 9-3 說明了在具有多主複製的資料庫中日曆時鐘的危險使用(該示例類似於 圖 6-8)。客戶端 A 在節點 1 上寫入 x = 1;寫入被複制到節點 3;客戶端 B 在節點 3 上遞增 x(我們現在有 x = 2);最後,兩個寫入都被複制到節點 2。
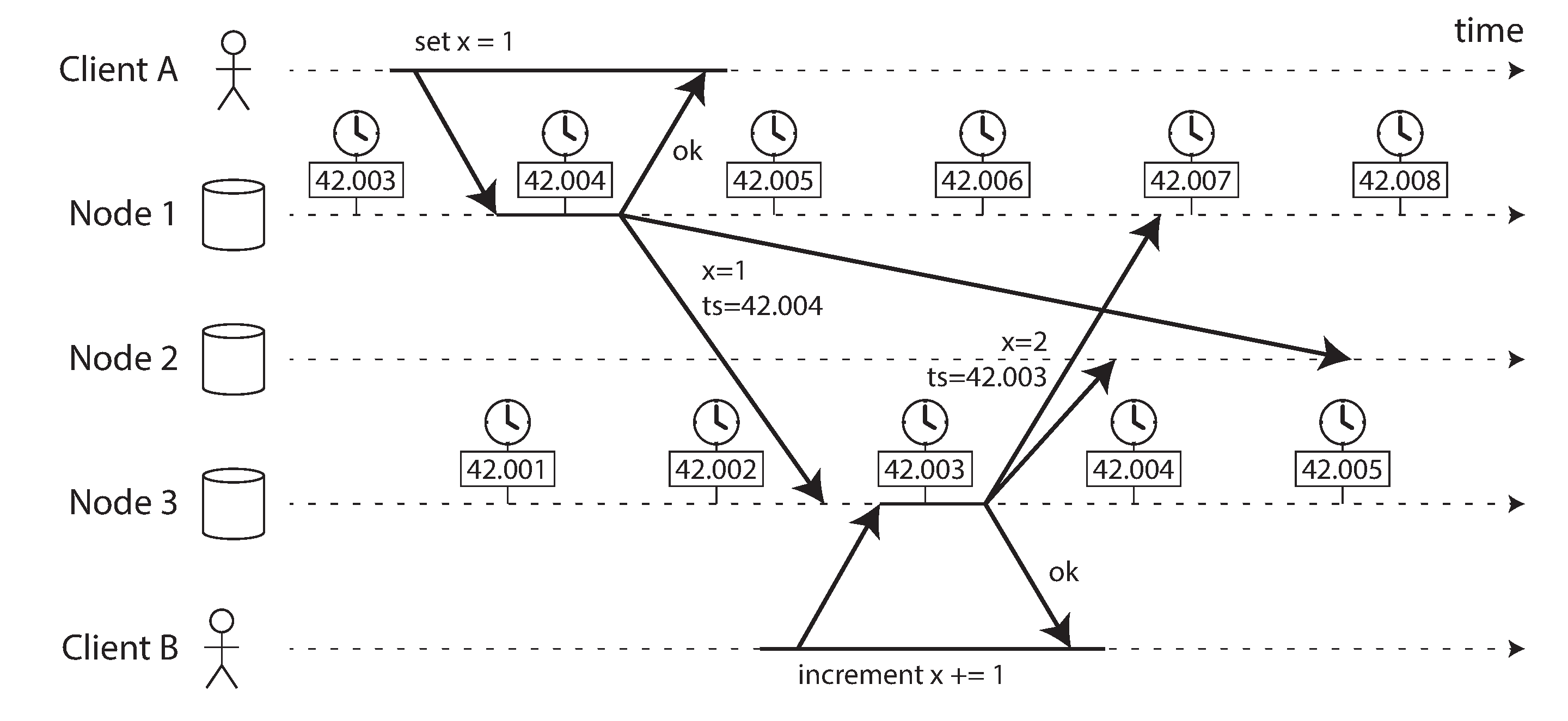
在 圖 9-3 中,當寫入被複制到其他節點時,它會根據寫入起源節點上的日曆時鐘標記時間戳。此示例中的時鐘同步非常好:節點 1 和節點 3 之間的偏差小於 3 毫秒,這可能比你在實踐中可以期望的要好。
由於遞增建立在 x = 1 的早期寫入之上,我們可能期望 x = 2 的寫入應該具有兩者中更大的時間戳。不幸的是,圖 9-3 中發生的並非如此:寫入 x = 1 的時間戳為 42.004 秒,但寫入 x = 2 的時間戳為 42.003 秒。
如 “最後寫入勝利(丟棄併發寫入)” 中所討論的,解決不同節點上併發寫入值之間衝突的一種方法是 最後寫入勝利(LWW),這意味著保留給定鍵的具有最大時間戳的寫入,並丟棄所有具有較舊時間戳的寫入。在 圖 9-3 的示例中,當節點 2 接收這兩個事件時,它將錯誤地得出結論,認為 x = 1 是更新的值並丟棄寫入 x = 2,因此遞增丟失了。
可以透過確保當值被覆蓋時,新值總是具有比被覆蓋值更高的時間戳來防止這個問題,即使該時間戳超前於寫入者的本地時鐘。然而,這會產生額外的讀取成本來查詢最大的現有時間戳。一些系統,包括 Cassandra 和 ScyllaDB,希望在單次往返中寫入所有副本,因此它們只是使用客戶端時鐘的時間戳以及最後寫入勝利策略 62。這種方法有一些嚴重的問題:
- 資料庫寫入可能會神秘地消失:具有滯後時鐘的節點無法覆蓋先前由具有快速時鐘的節點寫入的值,直到節點之間的時鐘偏差時間過去 63 65。這種情況可能導致任意數量的資料被靜默丟棄,而不會嚮應用程式報告任何錯誤。
- LWW 無法區分快速連續發生的順序寫入(在 圖 9-3 中,客戶端 B 的遞增肯定發生在客戶端 A 的寫入 之後)和真正併發的寫入(兩個寫入者都不知道對方)。需要額外的因果關係跟蹤機制,如版本向量,以防止違反因果關係(見 “檢測併發寫入”)。
- 兩個節點可能獨立生成具有相同時間戳的寫入,特別是當時鍾只有毫秒解析度時。需要額外的決勝值(可以簡單地是一個大的隨機數)來解決此類衝突,但這種方法也可能導致違反因果關係 62。
因此,即使透過保留最 “新” 的值並丟棄其他值來解決衝突很誘人,但重要的是要意識到 “新” 的定義取決於本地日曆時鐘,它很可能是不正確的。即使使用緊密 NTP 同步的時鐘,你也可能在時間戳 100 毫秒(根據傳送者的時鐘)傳送資料包,並讓它在時間戳 99 毫秒(根據接收者的時鐘)到達 —— 因此看起來資料包在傳送之前就到達了,這是不可能的。
NTP 同步能否足夠準確以至於不會發生此類錯誤排序?可能不行,因為除了石英漂移等其他誤差源之外,NTP 的同步精度本身受到網路往返時間的限制。要保證正確的排序,你需要時鐘誤差顯著低於網路延遲,這是不可能的。
所謂的 邏輯時鐘 66,基於遞增計數器而不是振盪石英晶體,是排序事件的更安全替代方案(見 “檢測併發寫入”)。邏輯時鐘不測量一天中的時間或經過的秒數,只測量事件的相對順序(一個事件是在另一個事件之前還是之後發生)。相比之下,日曆時鐘和單調時鐘測量實際經過的時間,也稱為 物理時鐘。我們將在 “ID 生成器和邏輯時鐘” 中更詳細地研究邏輯時鐘。
帶置信區間的時鐘讀數
你可能能夠以微秒甚至納秒解析度讀取機器的日曆時鐘。但即使你能獲得如此細粒度的測量,也不意味著該值實際上精確到如此精度。事實上,它很可能不是 —— 如前所述,即使你每分鐘與本地網路上的 NTP 伺服器同步,不精確的石英時鐘的漂移也很容易達到幾毫秒。使用公共網際網路上的 NTP 伺服器,最佳可能精度可能是幾十毫秒,當存在網路擁塞時,誤差很容易超過 100 毫秒。
因此,將時鐘讀數視為時間點是沒有意義的 —— 它更像是一個時間範圍,在置信區間內:例如,系統可能有 95% 的信心認為現在的時間在分鐘後的 10.3 到 10.5 秒之間,但它不知道比這更精確的時間 67。如果我們只知道時間 +/- 100 毫秒,時間戳中的微秒數字基本上是沒有意義的。
不確定性邊界可以根據你的時間源計算。如果你有直接連線到計算機的 GPS 接收器或原子鐘,預期誤差範圍由裝置決定,對於 GPS,由來自衛星的訊號質量決定。如果你從伺服器獲取時間,不確定性基於自上次與伺服器同步以來的預期石英漂移,加上 NTP 伺服器的不確定性,加上到伺服器的網路往返時間(作為第一近似,並假設你信任伺服器)。
不幸的是,大多數系統不暴露這種不確定性:例如,當你呼叫 clock_gettime() 時,返回值不會告訴你時間戳的預期誤差,所以你不知道它的置信區間是五毫秒還是五年。
有例外:Google Spanner 中的 TrueTime API 45 和亞馬遜的 ClockBound 明確報告本地時鐘的置信區間。當你詢問當前時間時,你會得到兩個值:[earliest, latest],它們是 最早可能 和 最晚可能 的時間戳。基於其不確定性計算,時鐘知道實際當前時間在該區間內的某處。區間的寬度取決於多種因素,包括本地石英時鐘上次與更準確的時鐘源同步以來已經過去了多長時間。
用於全域性快照的同步時鐘
在 “快照隔離和可重複讀” 中,我們討論了 多版本併發控制(MVCC),這是資料庫中非常有用的功能,需要支援小型、快速的讀寫事務和大型、長時間執行的只讀事務(例如,用於備份或分析)。它允許只讀事務看到資料庫的 快照,即特定時間點的一致狀態,而不會鎖定和干擾讀寫事務。
通常,MVCC 需要單調遞增的事務 ID。如果寫入發生在快照之後(即,寫入的事務 ID 大於快照),則該寫入對快照事務不可見。在單節點資料庫上,簡單的計數器就足以生成事務 ID。
然而,當資料庫分佈在許多機器上,可能在多個數據中心時,全域性單調遞增的事務 ID(跨所有分片)很難生成,因為它需要協調。事務 ID 必須反映因果關係:如果事務 B 讀取或覆蓋先前由事務 A 寫入的值,則 B 必須具有比 A 更高的事務 ID —— 否則,快照將不一致。對於大量小型、快速的事務,在分散式系統中建立事務 ID 成為難以承受的瓶頸。(我們將在 “ID 生成器和邏輯時鐘” 中討論此類 ID 生成器。)
我們能否使用同步日曆時鐘的時間戳作為事務 ID?如果我們能夠獲得足夠好的同步,它們將具有正確的屬性:較晚的事務具有更高的時間戳。當然,問題是時鐘精度的不確定性。
Spanner 以這種方式跨資料中心實現快照隔離 68 69。它使用 TrueTime API 報告的時鐘置信區間,並基於以下觀察:如果你有兩個置信區間,每個都由最早和最晚可能的時間戳組成(A = [A最早, A最晚] 和 B = [B最早, B最晚]),並且這兩個區間不重疊(即,A最早 < A最晚 < B最早 < B最晚),那麼 B 肯定發生在 A 之後 —— 毫無疑問。只有當區間重疊時,我們才不確定 A 和 B 發生的順序。
為了確保事務時間戳反映因果關係,Spanner 在提交讀寫事務之前故意等待置信區間的長度。透過這樣做,它確保任何可能讀取資料的事務都在足夠晚的時間,因此它們的置信區間不會重疊。為了使等待時間儘可能短,Spanner 需要使時鐘不確定性儘可能小;為此,Google 在每個資料中心部署 GPS 接收器或原子鐘,使時鐘能夠同步到大約 7 毫秒以內 45。
原子鐘和 GPS 接收器在 Spanner 中並不是嚴格必要的:重要的是要有一個置信區間,準確的時鐘源只是幫助保持該區間較小。其他系統開始採用類似的方法:例如,YugabyteDB 在 AWS 上執行時可以利用 ClockBound 70,其他幾個系統現在也在不同程度上依賴時鐘同步 71 72。
程序暫停
讓我們考慮分散式系統中危險使用時鐘的另一個例子。假設你有一個每個分片都有單個主節點的資料庫。只有主節點被允許接受寫入。節點如何知道它仍然是主節點(它沒有被其他節點宣佈死亡),並且它可以安全地接受寫入?
一種選擇是讓主節點從其他節點獲取 租約,這類似於帶有超時的鎖 73。任何時候只有一個節點可以持有租約 —— 因此,當節點獲得租約時,它知道在租約到期之前的一段時間內它是主節點。為了保持主節點身份,節點必須在租約到期之前定期續訂租約。如果節點失效,它會停止續訂租約,因此另一個節點可以在租約到期時接管。
你可以想象請求處理迴圈看起來像這樣:
while (true) {
request = getIncomingRequest();
// 確保租約始終至少有 10 秒的剩餘時間
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000) {
lease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
}這段程式碼有什麼問題?首先,它依賴於同步時鐘:租約的到期時間由不同的機器設定(到期時間可能計算為當前時間加 30 秒,例如),並且它與本地系統時鐘進行比較。如果時鐘相差超過幾秒鐘,這段程式碼將開始做奇怪的事情。
其次,即使我們更改協議以僅使用本地單調時鐘,還有另一個問題:程式碼假設在檢查時間(System.currentTimeMillis())和處理請求(process(request))之間經過的時間非常少。通常這段程式碼執行得非常快,所以 10 秒的緩衝時間足以確保租約不會在處理請求的過程中到期。
然而,如果程式執行中出現意外暫停會怎樣?例如,想象執行緒在 lease.isValid() 行周圍停止了 15 秒,然後才最終繼續。在這種情況下,處理請求時租約很可能已經到期,另一個節點已經接管了主節點身份。然而,沒有任何東西告訴這個執行緒它暫停了這麼長時間,所以這段程式碼不會注意到租約已經到期,直到迴圈的下一次迭代 —— 到那時它可能已經透過處理請求做了一些不安全的事情。
假設執行緒可能暫停這麼長時間是合理的嗎?不幸的是,是的。有各種原因可能導致這種情況發生:
- 執行緒訪問共享資源(如鎖或佇列)時的爭用可能導致執行緒花費大量時間等待。轉移到具有更多 CPU 核心的機器可能會使此類問題變得更糟,並且爭用問題可能難以診斷 74。
- 許多程式語言執行時(如 Java 虛擬機器)有 垃圾回收器(GC),偶爾需要停止所有正在執行的執行緒。過去,這種 “全域性暫停” GC 暫停 有時會持續幾分鐘 75!使用現代 GC 演算法,這不再是一個大問題,但 GC 暫停仍然可能很明顯(見 “限制垃圾回收的影響”)。
- 在虛擬化環境中,虛擬機器可以被 掛起(暫停所有程序的執行並將記憶體內容儲存到磁碟)和 恢復(恢復記憶體內容並繼續執行)。這種暫停可能發生在程序執行的任何時間,並且可能持續任意長的時間。這個功能有時用於虛擬機器從一臺主機到另一臺主機的 即時遷移,無需重啟,在這種情況下,暫停的長度取決於程序寫入記憶體的速率 76。
- 在筆記型電腦和手機等終端使用者裝置上,執行也可能被任意掛起和恢復,例如,當用戶合上筆記型電腦蓋時。
- 當作業系統上下文切換到另一個執行緒時,或者當虛擬機器管理程式切換到不同的虛擬機器時(在虛擬機器中執行時),當前執行的執行緒可能在程式碼的任何任意點暫停。在虛擬機器的情況下,在其他虛擬機器中花費的 CPU 時間稱為 竊取時間。如果機器負載很重 —— 即,如果有長佇列的執行緒等待執行 —— 暫停的執行緒可能需要一些時間才能再次執行。
- 如果應用程式執行同步磁碟訪問,執行緒可能會暫停等待緩慢的磁碟 I/O 操作完成 77。在許多語言中,磁碟訪問可能會令人驚訝地發生,即使程式碼沒有明確提到檔案訪問 —— 例如,Java 類載入器在首次使用時會延遲載入類檔案,這可能發生在程式執行的任何時間。I/O 暫停和 GC 暫停甚至可能共謀結合它們的延遲 78。如果磁碟實際上是網路檔案系統或網路塊裝置(如亞馬遜的 EBS),I/O 延遲還會受到網路延遲可變性的影響 31。
- 如果作業系統配置為允許 交換到磁碟(分頁),簡單的記憶體訪問可能會導致頁面錯誤,需要從磁碟載入頁面到記憶體。執行緒在此緩慢的 I/O 操作進行時暫停。如果記憶體壓力很高,這可能反過來需要將不同的頁面交換到磁碟。在極端情況下,作業系統可能會花費大部分時間在記憶體中交換頁面進出,而實際完成的工作很少(這被稱為 抖動)。為了避免這個問題,伺服器機器上通常停用分頁(如果你寧願殺死程序以釋放記憶體而不是冒抖動的風險)。
- Unix 程序可以透過向其傳送
SIGSTOP訊號來暫停,例如透過在 shell 中按 Ctrl-Z。此訊號立即停止程序獲取更多 CPU 週期,直到使用SIGCONT恢復它,此時它從停止的地方繼續執行。即使你的環境通常不使用SIGSTOP,它也可能被運維工程師意外發送。
所有這些情況都可以在任何時候 搶佔 正在執行的執行緒,並在稍後的某個時間恢復它,而執行緒甚至沒有注意到。這個問題類似於在單臺機器上使多執行緒程式碼執行緒安全:你不能對時序做任何假設,因為可能會發生任意的上下文切換和並行性。
在單臺機器上編寫多執行緒程式碼時,我們有相當好的工具來使其執行緒安全:互斥鎖、訊號量、原子計數器、無鎖資料結構、阻塞佇列等。不幸的是,這些工具不能直接轉換到分散式系統,因為分散式系統沒有共享記憶體 —— 只有透過不可靠網路傳送的訊息。
分散式系統中的節點必須假設其執行可以在任何時候暫停相當長的時間,即使在函式的中間。在暫停期間,世界的其餘部分繼續執行,甚至可能因為暫停的節點沒有響應而宣佈它死亡。最終,暫停的節點可能會繼續執行,甚至沒有注意到它在睡覺,直到它稍後某個時候檢查其時鐘。
響應時間保證
在許多程式語言和作業系統中,如所討論的,執行緒和程序可能會暫停無限長的時間。如果你足夠努力,這些暫停的原因 可以 被消除。
某些軟體在環境中執行,如果未能在指定時間內響應可能會造成嚴重損害:控制飛機、火箭、機器人、汽車和其他物理物件的計算機必須快速且可預測地響應其感測器輸入。在這些系統中,有一個指定的 截止時間,軟體必須在此之前響應;如果它沒有達到截止時間,可能會導致整個系統的故障。這些被稱為 硬即時 系統。
Note
在嵌入式系統中,即時 意味著系統經過精心設計和測試,以在所有情況下滿足指定的時序保證。這個含義與網路上更模糊的 即時 術語使用形成對比,後者描述伺服器向客戶端推送資料和流處理,沒有硬響應時間約束(見後續章節)。
例如,如果你的汽車的車載感測器檢測到你當前正在經歷碰撞,你不希望安全氣囊的釋放因為安全氣囊釋放系統中不合時宜的 GC 暫停而延遲。
在系統中提供即時保證需要軟體棧所有級別的支援:需要 即時作業系統(RTOS),它允許程序在指定的時間間隔內以有保證的 CPU 時間分配進行排程;庫函式必須記錄其最壞情況執行時間;動態記憶體分配可能受到限制或完全禁止(即時垃圾回收器存在,但應用程式仍必須確保它不會給 GC 太多工作);必須進行大量的測試和測量以確保滿足保證。
所有這些都需要大量的額外工作,並嚴重限制了可以使用的程式語言、庫和工具的範圍(因為大多數語言和工具不提供即時保證)。由於這些原因,開發即時系統非常昂貴,它們最常用於安全關鍵的嵌入式裝置。此外,“即時” 不同於 “高效能” —— 事實上,即時系統可能具有較低的吞吐量,因為它們必須優先考慮及時響應高於一切(另見 “延遲和資源利用率”)。
對於大多數伺服器端資料處理系統,即時保證根本不經濟或不合適。因此,這些系統必須承受在非即時環境中執行帶來的暫停和時鐘不穩定性。
限制垃圾回收的影響
垃圾回收曾經是程序暫停的最大原因之一 79,但幸運的是 GC 演算法已經改進了很多:經過適當調整的回收器現在通常只會暫停幾毫秒。Java 執行時提供了併發標記清除(CMS)、G1、Z 垃圾回收器(ZGC)、Epsilon 和 Shenandoah 等回收器。每個都針對不同的記憶體配置檔案進行了最佳化,如高頻物件建立、大堆等。相比之下,Go 提供了一個更簡單的併發標記清除垃圾回收器,試圖自我最佳化。
如果你需要完全避免 GC 暫停,一個選擇是使用根本沒有垃圾回收器的語言。例如,Swift 使用自動引用計數來確定何時可以釋放記憶體;Rust 和 Mojo 使用型別系統跟蹤物件的生命週期,以便編譯器可以確定必須分配記憶體多長時間。
也可以使用垃圾回收語言,同時減輕暫停的影響。一種方法是將 GC 暫停視為節點的短暫計劃中斷,並讓其他節點在一個節點收集垃圾時處理來自客戶端的請求。如果執行時可以警告應用程式節點很快需要 GC 暫停,應用程式可以停止向該節點發送新請求,等待它完成處理未完成的請求,然後在沒有請求進行時執行 GC。這個技巧從客戶端隱藏了 GC 暫停,並減少了響應時間的高百分位數 80 81。
這個想法的一個變體是僅對短期物件使用垃圾回收器(快速收集),並定期重啟程序,在它們積累足夠的長期物件需要長期物件的完整 GC 之前 79 82。可以一次重啟一個節點,並且可以在計劃重啟之前將流量從節點轉移,就像滾動升級一樣(見 第 5 章)。
這些措施不能完全防止垃圾回收暫停,但它們可以有效地減少對應用程式的影響。
知識、真相與謊言
到目前為止,在本章中,我們已經探討了分散式系統與在單臺計算機上執行的程式的不同之處:沒有共享記憶體,只有透過不可靠的網路進行訊息傳遞,具有可變延遲,系統可能會遭受部分失效、不可靠的時鐘和處理暫停。
如果你不習慣分散式系統,這些問題的後果會令人深感迷惑。網路中的節點不能 確切地知道 關於其他節點的任何事情 —— 它只能根據它接收(或未接收)的訊息進行猜測。節點只能透過與另一個節點交換訊息來了解它處於什麼狀態(它儲存了什麼資料,它是否正常執行等)。如果遠端節點沒有響應,就無法知道它處於什麼狀態,因為網路中的問題無法與節點的問題可靠地區分開來。
這些系統的討論接近哲學:在我們的系統中,我們知道什麼是真或假?如果感知和測量的機制不可靠,我們對這些知識有多確定 83?軟體系統是否應該遵守我們對物理世界的期望法則,如因果關係?
幸運的是,我們不需要走到弄清生命意義的程度。在分散式系統中,我們可以陳述我們對行為(系統模型)的假設,並以這樣的方式設計實際系統,使其滿足這些假設。演算法可以被證明在某個系統模型內正確執行。這意味著即使底層系統模型提供的保證很少,也可以實現可靠的行為。
然而,儘管可以在不可靠的系統模型中使軟體表現良好,但這樣做並不簡單。在本章的其餘部分,我們將進一步探討分散式系統中知識和真相的概念,這將幫助我們思考我們可以做出的假設型別和我們可能希望提供的保證。在 第 10 章 中,我們將繼續檢視在特定假設下提供特定保證的分散式演算法的一些示例。
多數派原則
想象一個具有不對稱故障的網路:一個節點能夠接收發送給它的所有訊息,但該節點的任何傳出訊息都被丟棄或延遲 22。即使該節點執行得非常好,並且正在接收來自其他節點的請求,其他節點也無法聽到它的響應。在一些超時之後,其他節點宣佈它死亡,因為它們沒有收到該節點的訊息。情況展開就像一場噩夢:半斷開的節點被拖到墓地,踢腿尖叫著 “我沒死!” —— 但由於沒人能聽到它的尖叫,葬禮隊伍以堅忍的決心繼續前進。
在稍微不那麼可怕的情況下,半斷開的節點可能會注意到它傳送的訊息沒有被其他節點確認,因此意識到網路中一定有故障。儘管如此,該節點被其他節點錯誤地宣佈死亡,半斷開的節點對此無能為力。
作為第三種情況,想象一個節點暫停執行一分鐘。在此期間,沒有請求被處理,也沒有響應被傳送。其他節點等待、重試、變得不耐煩,最終宣佈該節點死亡並將其裝上靈車。最後,暫停結束,節點的執行緒繼續執行,就好像什麼都沒發生過。其他節點驚訝地看到據稱已死的節點突然從棺材裡抬起頭來,健康狀況良好,開始愉快地與旁觀者聊天。起初,暫停的節點甚至沒有意識到整整一分鐘已經過去,它被宣佈死亡 —— 從它的角度來看,自從它上次與其他節點交談以來,幾乎沒有時間過去。
這些故事的寓意是,節點不一定能信任自己對情況的判斷。分散式系統不能完全依賴單個節點,因為節點可能隨時失效,可能使系統陷入困境並無法恢復。相反,許多分散式演算法依賴於 仲裁,即節點之間的投票(見 “讀寫仲裁”):決策需要來自幾個節點的最少票數,以減少對任何一個特定節點的依賴。
這包括關於宣佈節點死亡的決定。如果節點的仲裁宣佈另一個節點死亡,那麼它必須被認為是死亡的,即使該節點仍然感覺自己非常活著。個別節點必須遵守仲裁決定並退出。
最常見的是,仲裁是超過半數節點的絕對多數(儘管其他型別的仲裁也是可能的)。多數仲裁允許系統在少數節點故障時繼續工作(三個節點可以容忍一個故障節點;五個節點可以容忍兩個故障節點)。然而,它仍然是安全的,因為系統中只能有一個多數 —— 不能同時有兩個具有衝突決策的多數。當我們在 第 10 章 討論 共識演算法 時,我們將更詳細地討論仲裁的使用。
分散式鎖和租約
分散式應用程式中的鎖和租約容易被誤用,並且是錯誤的常見來源 84。讓我們看看它們如何出錯的一個特定案例。
在 “程序暫停” 中,我們看到租約是一種超時的鎖,如果舊所有者停止響應(可能是因為它崩潰了、暫停太久或與網路斷開連線),可以分配給新所有者。你可以在系統需要只有一個某種東西的情況下使用租約。例如:
- 只允許一個節點成為資料庫分片的主節點,以避免腦裂(見 “處理節點中斷”)。
- 只允許一個事務或客戶端更新特定資源或物件,以防止併發寫入損壞它。
- 只有一個節點應該處理大型處理作業的給定輸入檔案,以避免由於多個節點冗餘地執行相同工作而浪費精力。
值得仔細思考如果幾個節點同時認為它們持有租約會發生什麼,可能是由於程序暫停。在第三個例子中,後果只是一些浪費的計算資源,這不是什麼大問題。但在前兩種情況下,後果可能是資料丟失或損壞,這要嚴重得多。
例如,圖 9-4 顯示了由於鎖的錯誤實現導致的資料損壞錯誤。(該錯誤不是理論上的:HBase 曾經有這個問題 85 86。)假設你想確保儲存服務中的檔案一次只能由一個客戶端訪問,因為如果多個客戶端試圖寫入它,檔案將被損壞。你嘗試透過要求客戶端在訪問檔案之前從鎖服務獲取租約來實現這一點。這種鎖服務通常使用共識演算法實現;我們將在 第 10 章 中進一步討論這一點。
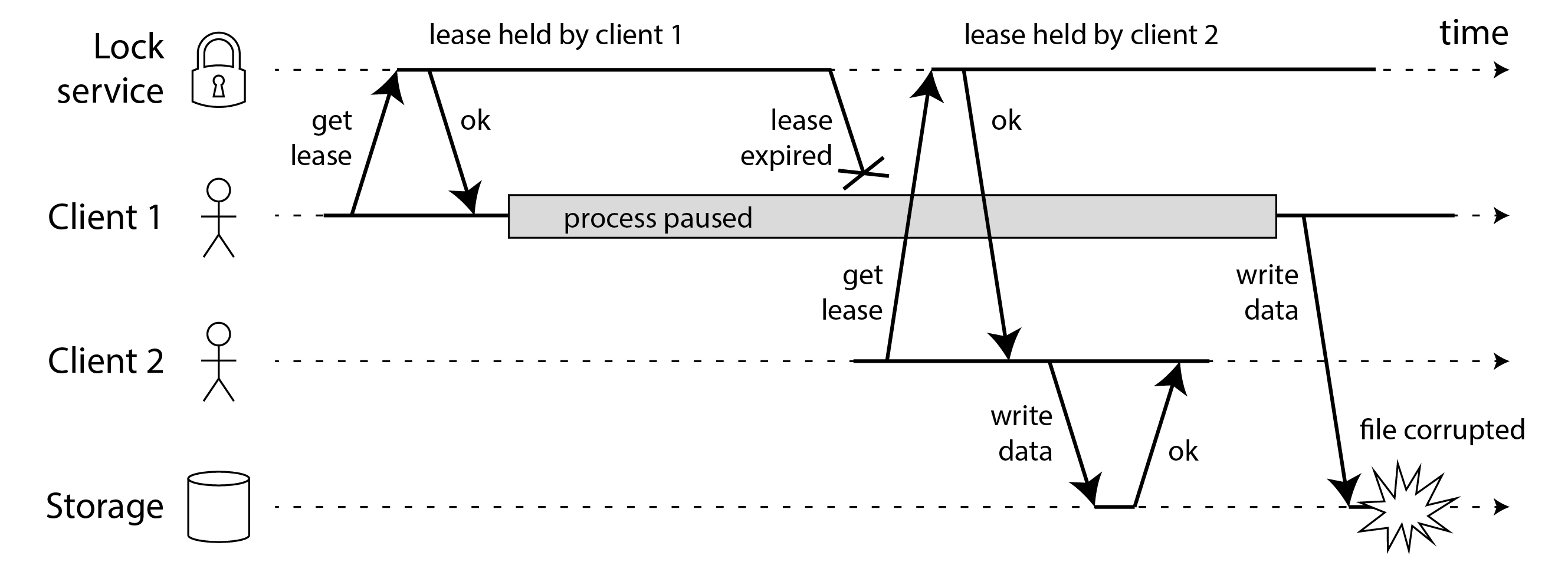
問題是我們在 “程序暫停” 中討論的一個例子:如果持有租約的客戶端暫停太久,其租約就會過期。另一個客戶端可以獲得同一檔案的租約,並開始寫入檔案。當暫停的客戶端回來時,它(錯誤地)認為它仍然有有效的租約,並繼續寫入檔案。我們現在有了腦裂情況:客戶端的寫入衝突並損壞了檔案。
圖 9-5 顯示了具有類似後果的另一個問題。在這個例子中沒有程序暫停,只有客戶端 1 的崩潰。就在客戶端 1 崩潰之前,它向儲存服務傳送了一個寫請求,但這個請求在網路中被延遲了很長時間。(請記住 “實踐中的網路故障”,資料包有時可能會延遲一分鐘或更長時間。)當寫請求到達儲存服務時,租約已經超時,允許客戶端 2 獲取它併發出自己的寫入。結果是類似於 圖 9-4 的損壞。
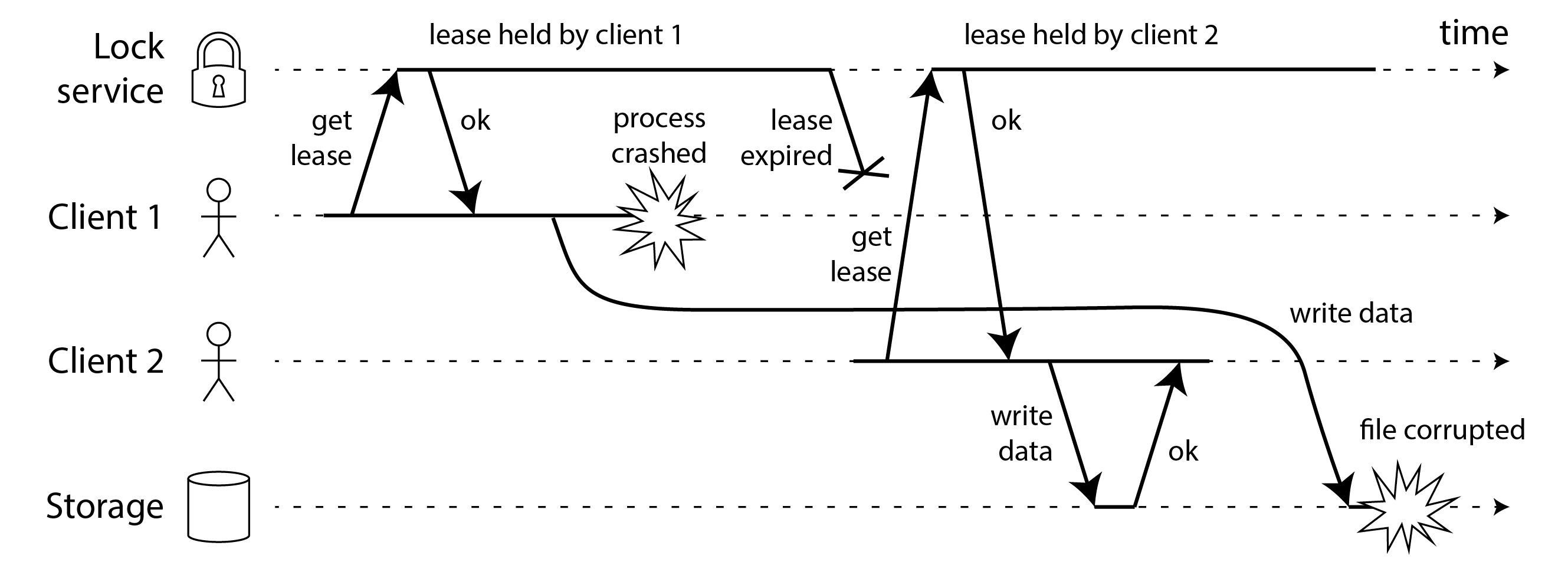
隔離殭屍程序和延遲請求
術語 殭屍 有時用於描述尚未發現失去租約的前租約持有者,並且仍在充當當前租約持有者。由於我們不能完全排除殭屍,我們必須確保它們不能以腦裂的形式造成任何損害。這被稱為 隔離 殭屍。
一些系統試圖透過關閉殭屍來隔離它們,例如透過斷開它們與網路的連線 9、透過雲提供商的管理介面關閉 VM,甚至物理關閉機器 87。這種方法被稱為 對端節點爆頭(STONITH)。不幸的是,它存在一些問題:它不能防範像 圖 9-5 中那樣的大網路延遲;可能會發生所有節點相互關閉的情況 19;到檢測到殭屍並關閉它時,可能已經太晚了,資料可能已經被損壞。
一個更強大的隔離解決方案,可以防範殭屍和延遲請求,如 圖 9-6 所示。
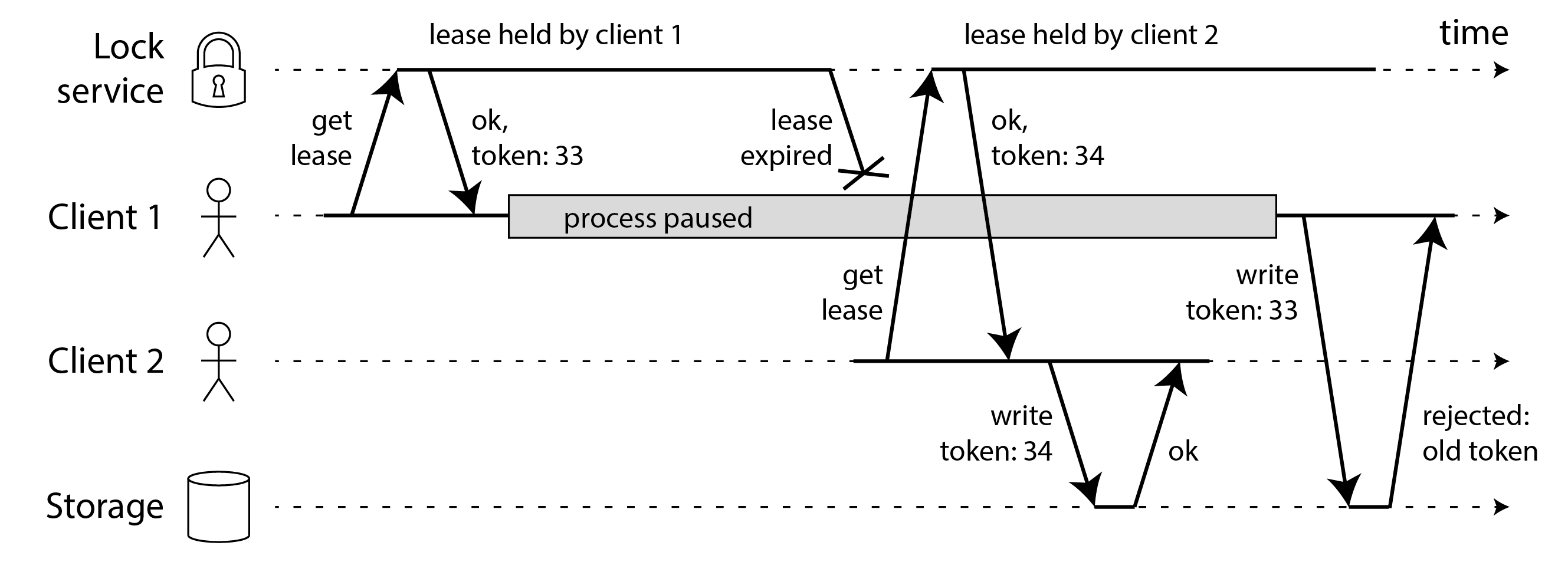
假設每次鎖服務授予鎖或租約時,它還返回一個 隔離令牌,這是一個每次授予鎖時都會增加的數字(例如,由鎖服務遞增)。然後我們可以要求客戶端每次向儲存服務傳送寫請求時,都必須包含其當前的隔離令牌。
Note
在 圖 9-6 中,客戶端 1 獲得帶有令牌 33 的租約,但隨後進入長時間暫停,租約過期。客戶端 2 獲得帶有令牌 34 的租約(數字總是增加),然後將其寫請求傳送到儲存服務,包括令牌 34。稍後,客戶端 1 恢復執行並將其寫入傳送到儲存服務,包括其令牌值 33。然而,儲存服務記得它已經處理了具有更高令牌編號(34)的寫入,因此它拒絕帶有令牌 33 的請求。剛剛獲得租約的客戶端必須立即向儲存服務進行寫入,一旦該寫入完成,任何殭屍都被隔離了。
如果 ZooKeeper 是你的鎖服務,你可以使用事務 ID zxid 或節點版本 cversion 作為隔離令牌 85。使用 etcd,修訂號與租約 ID 一起起著類似的作用 89。Hazelcast 中的 FencedLock API 明確生成隔離令牌 90。
這種機制要求儲存服務有某種方法來檢查寫入是否基於過時的令牌。或者,服務支援僅在物件自當前客戶端上次讀取以來未被另一個客戶端寫入時才成功的寫入就足夠了,類似於原子比較並設定(CAS)操作。例如,物件儲存服務支援這種檢查:Amazon S3 稱之為 條件寫入,Azure Blob Storage 稱之為 條件標頭,Google Cloud Storage 稱之為 請求前提條件。
多副本隔離
如果你的客戶端只需要寫入一個支援此類條件寫入的儲存服務,鎖服務在某種程度上是多餘的 91 92,因為租約分配本可以直接基於該儲存服務實現 93。然而,一旦你有了隔離令牌,你也可以將其用於多個服務或副本,並確保舊的租約持有者在所有這些服務上都被隔離。
例如,想象儲存服務是一個具有最後寫入勝利衝突解決的無主複製鍵值儲存(見 “無主複製”)。在這樣的系統中,客戶端直接向每個副本傳送寫入,每個副本根據客戶端分配的時間戳獨立決定是否接受寫入。
如 圖 9-7 所示,你可以將寫入者的隔離令牌放在時間戳的最高有效位或數字中。然後你可以確保新租約持有者生成的任何時間戳都將大於舊租約持有者的任何時間戳,即使舊租約持有者的寫入發生得更晚。
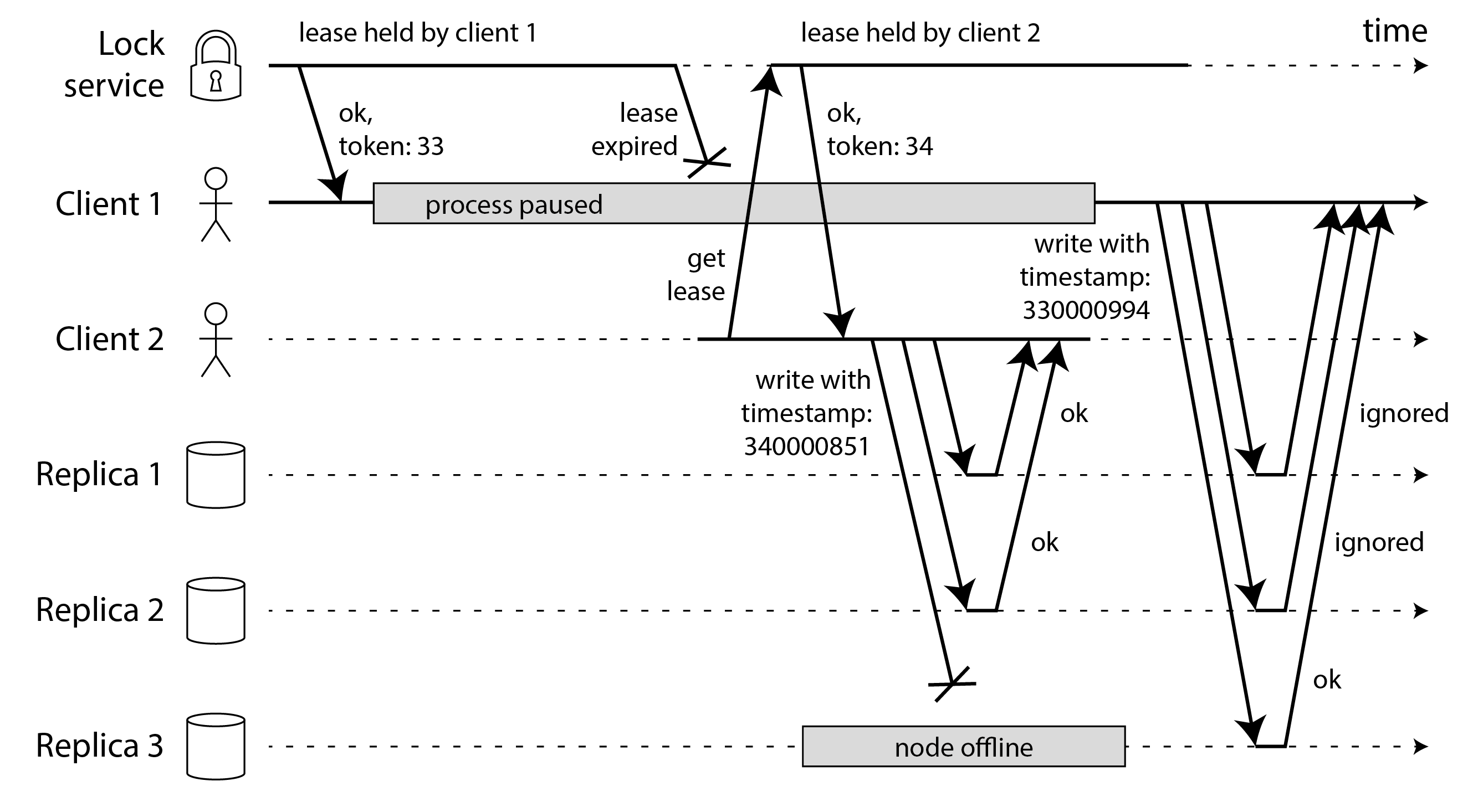
在 圖 9-7 中,客戶端 2 有隔離令牌 34,因此它所有以 34… 開頭的時間戳都大於客戶端 1 生成的任何以 33… 開頭的時間戳。客戶端 2 寫入副本的仲裁,但它無法到達副本 3。這意味著當殭屍客戶端 1 稍後嘗試寫入時,它的寫入可能在副本 3 上成功,即使它被副本 1 和 2 忽略。這不是問題,因為後續的仲裁讀取將更喜歡具有更大時間戳的客戶端 2 的寫入,讀修復或反熵最終將覆蓋客戶端 1 寫入的值。
從這些例子可以看出,假設任何時候只有一個節點持有租約是不安全的。幸運的是,透過一點小心,你可以使用隔離令牌來防止殭屍和延遲請求造成任何損害。
拜占庭故障
隔離令牌可以檢測並阻止 無意中 出錯的節點(例如,因為它尚未發現其租約已過期)。然而,如果節點故意想要破壞系統的保證,它可以透過傳送帶有虛假隔離令牌的訊息輕鬆做到。
在本書中,我們假設節點是不可靠但誠實的:它們可能很慢或從不響應(由於故障),它們的狀態可能已過時(由於 GC 暫停或網路延遲),但我們假設如果節點 確實 響應,它就是在說 “真話”:據它所知,它正在按協議規則行事。
如果節點可能 “撒謊”(傳送任意錯誤或損壞的響應)的風險存在,分散式系統問題會變得更加困難 —— 例如,它可能在同一次選舉中投出多個相互矛盾的票。這種行為被稱為 拜占庭故障,在這種不信任環境中達成共識的問題被稱為 拜占庭將軍問題 94。
拜占庭將軍問題
拜占庭將軍問題是所謂 兩將軍問題 95 的推廣,它想象了兩個軍隊將軍需要就戰鬥計劃達成一致的情況。由於他們在兩個不同的地點扎營,他們只能透過信使進行通訊,信使有時會延遲或丟失(就像網路中的資料包)。我們將在 第 10 章 中討論這個 共識 問題。
在問題的拜占庭版本中,有 n 個需要達成一致的將軍,他們的努力受到他們中間有一些叛徒的阻礙。大多數將軍是忠誠的,因此傳送真實的訊息,但叛徒可能試圖透過傳送虛假或不真實的訊息來欺騙和混淆其他人。事先不知道誰是叛徒。
拜占庭是一個古希臘城市,後來成為君士坦丁堡,位於現在土耳其的伊斯坦布林。沒有任何歷史證據表明拜占庭的將軍比其他地方的將軍更容易搞陰謀和密謀。相反,這個名字源自 拜占庭 一詞在 過於複雜、官僚、狡猾 的意義上的使用,這個詞在計算機出現之前很久就在政治中使用了 96。Lamport 想選擇一個不會冒犯任何讀者的國籍,他被建議稱之為 阿爾巴尼亞將軍問題 不是個好主意 97。
如果即使某些節點發生故障並且不遵守協議,或者惡意攻擊者干擾網路,系統仍能繼續正確執行,則該系統是 拜占庭容錯 的。這種擔憂在某些特定情況下是相關的。例如:
- 在航空航天環境中,計算機記憶體或 CPU 暫存器中的資料可能因輻射而損壞,導致它以任意不可預測的方式響應其他節點。由於系統故障的成本非常高昂(例如,飛機墜毀並殺宕機上所有人,或火箭與國際空間站相撞),飛行控制系統必須容忍拜占庭故障 98 99。
- 在有多個參與方的系統中,一些參與者可能試圖欺騙或欺詐其他人。在這種情況下,節點簡單地信任另一個節點的訊息是不安全的,因為它們可能是惡意傳送的。例如,比特幣等加密貨幣和其他區塊鏈可以被認為是讓相互不信任的各方就交易是否發生達成一致的一種方式,而無需依賴中央權威 100。
然而,在我們在本書中討論的系統型別中,我們通常可以安全地假設沒有拜占庭故障。在資料中心中,所有節點都由你的組織控制(因此它們有望被信任),輻射水平足夠低,記憶體損壞不是主要問題(儘管正在考慮軌道資料中心 101)。多租戶系統有相互不信任的租戶,但它們使用防火牆、虛擬化和訪問控制策略相互隔離,而不是使用拜占庭容錯。使系統拜占庭容錯的協議相當昂貴 102,容錯嵌入式系統依賴於硬體級別的支援 98。在大多數伺服器端資料系統中,部署拜占庭容錯解決方案的成本使它們不切實際。
Web 應用程式確實需要預期客戶端在終端使用者控制下的任意和惡意行為,例如 Web 瀏覽器。這就是輸入驗證、清理和輸出轉義如此重要的原因:例如,防止 SQL 注入和跨站指令碼攻擊。然而,我們通常不在這裡使用拜占庭容錯協議,而只是讓伺服器成為決定什麼客戶端行為被允許和不被允許的權威。在沒有這種中央權威的點對點網路中,拜占庭容錯更相關 103 104。
軟體中的錯誤可以被視為拜占庭故障,但如果你將相同的軟體部署到所有節點,那麼拜占庭容錯演算法無法拯救你。大多數拜占庭容錯演算法需要超過三分之二的節點的絕對多數才能正常執行(例如,如果你有四個節點,最多一個可能發生故障)。要使用這種方法對付錯誤,你必須有四個相同軟體的獨立實現,並希望錯誤只出現在四個實現中的一個。
同樣,如果協議可以保護我們免受漏洞、安全妥協和惡意攻擊,那將是很有吸引力的。不幸的是,這也不現實:在大多數系統中,如果攻擊者可以破壞一個節點,他們可能可以破壞所有節點,因為它們可能執行相同的軟體。因此,傳統機制(身份驗證、訪問控制、加密、防火牆等)仍然是防範攻擊者的主要保護。
弱形式的謊言
儘管我們假設節點通常是誠實的,但向軟體新增防範弱形式 “謊言” 的機制可能是值得的 —— 例如,由於硬體問題、軟體錯誤和配置錯誤導致的無效訊息。這種保護機制不是完全的拜占庭容錯,因為它們無法抵禦堅定的對手,但它們仍然是朝著更好可靠性邁出的簡單而務實的步驟。例如:
- 由於硬體問題或作業系統、驅動程式、路由器等中的錯誤,網路資料包有時確實會損壞。通常,損壞的資料包會被內置於 TCP 和 UDP 中的校驗和捕獲,但有時它們會逃避檢測 105 106 107。簡單的措施通常足以防範此類損壞,例如應用程式級協議中的校驗和。TLS 加密連線也提供防損壞保護。
- 公開可訪問的應用程式必須仔細清理來自使用者的任何輸入,例如檢查值是否在合理範圍內,並限制字串的大小以防止透過大記憶體分配進行拒絕服務。防火牆後面的內部服務可能能夠在輸入上進行較少嚴格的檢查,但協議解析器中的基本檢查仍然是個好主意 105。
- NTP 客戶端可以配置多個伺服器地址。同步時,客戶端聯絡所有伺服器,估計它們的錯誤,並檢查大多數伺服器是否在某個時間範圍內達成一致。只要大多數伺服器都正常,報告不正確時間的配置錯誤的 NTP 伺服器就會被檢測為異常值並從同步中排除 39。使用多個伺服器使 NTP 比僅使用單個伺服器更強大。
系統模型與現實
許多演算法被設計來解決分散式系統問題 —— 例如,我們將在 第 10 章 中研究共識問題的解決方案。為了有用,這些演算法需要容忍我們在本章中討論的分散式系統的各種故障。
演算法需要以不過度依賴於它們執行的硬體和軟體配置細節的方式編寫。這反過來又要求我們以某種方式形式化我們期望在系統中發生的故障型別。我們透過定義 系統模型 來做到這一點,這是一個描述演算法可能假設什麼事情的抽象。
關於時序假設,三種系統模型常用:
- 同步模型
- 同步模型假設有界的網路延遲、有界的程序暫停和有界的時鐘誤差。這並不意味著精確同步的時鐘或零網路延遲;它只是意味著你知道網路延遲、暫停和時鐘漂移永遠不會超過某個固定的上限 108。同步模型不是大多數實際系統的現實模型,因為(如本章所討論的)無界延遲和暫停確實會發生。
- 部分同步模型
- 部分同步意味著系統 大部分時間 表現得像同步系統,但有時會超過網路延遲、程序暫停和時鐘漂移的界限 108。這是許多系統的現實模型:大部分時間,網路和程序表現相當良好 —— 否則我們永遠無法完成任何事情 —— 但我們必須考慮到任何時序假設偶爾可能會被打破的事實。發生這種情況時,網路延遲、暫停和時鐘誤差可能會變得任意大。
- 非同步模型
- 在這個模型中,演算法不允許做出任何時序假設 —— 事實上,它甚至沒有時鐘(因此它不能使用超時)。一些演算法可以為非同步模型設計,但它非常有限。
此外,除了時序問題,我們還必須考慮節點故障。節點的一些常見系統模型是:
- 崩潰停止故障
- 在 崩潰停止(或 故障停止)模型中,演算法可以假設節點只能以一種方式失效,即崩潰 109。這意味著節點可能在任何時刻突然停止響應,此後該節點永遠消失 —— 它永遠不會回來。
- 崩潰恢復故障
- 我們假設節點可能在任何時刻崩潰,並且可能在某個未知時間後再次開始響應。在崩潰恢復模型中,假設節點具有跨崩潰保留的穩定儲存(即非易失性磁碟儲存),而記憶體中的狀態假設丟失。
- 效能下降和部分功能
- 除了崩潰和重啟之外,節點可能變慢:它們可能仍然能夠響應健康檢查請求,但速度太慢而無法完成任何實際工作。例如,千兆網路介面可能由於驅動程式錯誤突然降至 1 Kb/s 吞吐量 110;處於記憶體壓力下的程序可能會花費大部分時間執行垃圾回收 111;磨損的 SSD 可能具有不穩定的效能;硬體可能受到高溫、鬆動的聯結器、機械振動、電源問題、韌體錯誤等的影響 112。這種情況被稱為 跛行節點、灰色故障 或 慢速故障 113,它可能比干淨失效的節點更難處理。一個相關的問題是當程序停止執行它應該做的某些事情,而其他方面繼續工作時,例如因為後臺執行緒崩潰或死鎖 114。
- 拜占庭(任意)故障
- 節點可能做任何事情,包括試圖欺騙和欺騙其他節點,如上一節所述。
對於建模真實系統,具有崩潰恢復故障的部分同步模型通常是最有用的模型。它允許無界的網路延遲、程序暫停和慢節點。但是分散式演算法如何應對該模型?
定義演算法的正確性
為了定義演算法 正確 的含義,我們可以描述它的 屬性。例如,排序演算法的輸出具有這樣的屬性:對於輸出列表的任何兩個不同元素,左邊的元素小於右邊的元素。這只是定義列表排序含義的正式方式。
同樣,我們可以寫下我們希望分散式演算法具有的屬性,以定義正確的含義。例如,如果我們為鎖生成隔離令牌(見 “隔離殭屍程序和延遲請求”),我們可能要求演算法具有以下屬性:
- 唯一性
- 沒有兩個隔離令牌請求返回相同的值。
- 單調序列
- 如果請求 x 返回令牌 t**x,請求 y 返回令牌 t**y,並且 x 在 y 開始之前完成,則 t**x < t**y。
- 可用性
- 請求隔離令牌且不崩潰的節點最終會收到響應。
如果演算法在我們假設該系統模型中可能發生的所有情況下始終滿足其屬性,則該演算法在某個系統模型中是正確的。然而,如果所有節點崩潰,或者所有網路延遲突然變得無限長,那麼沒有演算法能夠完成任何事情。即使在允許完全失效的系統模型中,我們如何仍然做出有用的保證?
安全性與活性
為了澄清情況,值得區分兩種不同型別的屬性:安全性 和 活性 屬性。在剛才給出的例子中,唯一性 和 單調序列 是安全屬性,但 可用性 是活性屬性。
什麼區分這兩種屬性?一個跡象是活性屬性通常在其定義中包含 “最終” 一詞。(是的,你猜對了 —— 最終一致性 是一個活性屬性 115。)
安全性通常被非正式地定義為 沒有壞事發生,活性被定義為 好事最終會發生。然而,最好不要過多地解讀這些非正式定義,因為 “好” 和 “壞” 是價值判斷,不能很好地應用於演算法。安全性和活性的實際定義更精確 116:
- 如果違反了安全屬性,我們可以指出它被破壞的特定時間點(例如,如果違反了唯一性屬性,我們可以識別返回重複隔離令牌的特定操作)。在違反安全屬性之後,違規無法撤消 —— 損害已經造成。
- 活性屬性以相反的方式工作:它可能在某個時間點不成立(例如,節點可能已傳送請求但尚未收到響應),但總有希望它將來可能得到滿足(即透過接收響應)。
區分安全性和活性屬性的一個優點是它有助於我們處理困難的系統模型。對於分散式演算法,通常要求安全屬性在系統模型的所有可能情況下 始終 成立 108。也就是說,即使所有節點崩潰,或整個網路失效,演算法也必須確保它不會返回錯誤的結果(即,安全屬性保持滿足)。
然而,對於活性屬性,我們可以做出警告:例如,我們可以說請求只有在大多數節點沒有崩潰時才需要收到響應,並且只有在網路最終從中斷中恢復時才需要響應。部分同步模型的定義要求系統最終返回到同步狀態 —— 也就是說,任何網路中斷期只持續有限的時間,然後被修復。
將系統模型對映到現實世界
安全性和活性屬性以及系統模型對於推理分散式演算法的正確性非常有用。然而,在實踐中實現演算法時,現實的混亂事實又會回來咬你一口,很明顯系統模型是現實的簡化抽象。
例如,崩潰恢復模型中的演算法通常假設穩定儲存中的資料在崩潰後倖存。然而,如果磁碟上的資料損壞了,或者由於硬體錯誤或配置錯誤而擦除了資料,會發生什麼 117?如果伺服器有韌體錯誤並且在重啟時無法識別其硬碟驅動器,即使驅動器正確連線到伺服器,會發生什麼 118?
仲裁演算法(見 “讀寫仲裁”)依賴於節點記住它聲稱已儲存的資料。如果節點可能患有健忘症並忘記先前儲存的資料,那會破壞仲裁條件,從而破壞演算法的正確性。也許需要一個新的系統模型,其中我們假設穩定儲存大多在崩潰後倖存,但有時可能會丟失。但該模型隨後變得更難推理。
演算法的理論描述可以宣告某些事情被簡單地假設不會發生 —— 在非拜占庭系統中,我們確實必須對可能和不可能發生的故障做出一些假設。然而,真正的實現可能仍然必須包含程式碼來處理被假設為不可能的事情發生的情況,即使該處理歸結為 printf("Sucks to be you") 和 exit(666) —— 即,讓人類操作員清理爛攤子 119。(這是計算機科學和軟體工程之間的一個區別。)
這並不是說理論上的、抽象的系統模型是無用的 —— 恰恰相反。它們非常有助於將真實系統的複雜性提煉為我們可以推理的可管理的故障集,以便我們可以理解問題並嘗試系統地解決它。
形式化方法和隨機測試
我們如何知道演算法滿足所需的屬性?由於併發性、部分失效和網路延遲,存在大量潛在狀態。我們需要保證屬性在每個可能的狀態下都成立,並確保我們沒有忘記任何邊界情況。
一種方法是透過數學描述演算法來形式驗證它,並使用證明技術來表明它在系統模型允許的所有情況下都滿足所需的屬性。證明演算法正確並不意味著它在真實系統上的 實現 必然總是正確執行。但這是一個非常好的第一步,因為理論分析可以發現演算法中的問題,這些問題可能在真實系統中長時間隱藏,並且只有當你的假設(例如,關於時序)由於不尋常的情況而失敗時才會咬你一口。
將理論分析與經驗測試相結合以驗證實現按預期執行是明智的。基於屬性的測試、模糊測試和確定性模擬測試(DST)等技術使用隨機化來在各種情況下測試系統。亞馬遜網路服務等公司已成功地在其許多產品上使用了這些技術的組合 120 121。
模型檢查與規範語言
模型檢查器 是幫助驗證演算法或系統按預期執行的工具。演算法規範是用專門構建的語言編寫的,如 TLA+、Gallina 或 FizzBee。這些語言使得更容易專注於演算法的行為,而不必擔心程式碼實現細節。然後,模型檢查器使用這些模型透過系統地嘗試所有可能發生的事情來驗證不變數在演算法的所有狀態中都成立。
模型檢查實際上不能證明演算法的不變數對每個可能的狀態都成立,因為大多數現實世界的演算法都有無限的狀態空間。對所有狀態的真正驗證需要形式證明,這是可以做到的,但通常比執行模型檢查器更困難。相反,模型檢查器鼓勵你將演算法的模型減少到可以完全驗證的近似值,或者將執行限制到某個上限(例如,透過設定可以傳送的最大訊息數)。任何只在更長執行時發生的錯誤將不會被發現。
儘管如此,模型檢查器在易用性和查詢非顯而易見錯誤的能力之間取得了很好的平衡。CockroachDB、TiDB、Kafka 和許多其他分散式系統使用模型規範來查詢和修復錯誤 122 123 124。例如,使用 TLA+,研究人員能夠證明由演算法的散文描述中的歧義引起的檢視戳複製(VR)中資料丟失的可能性 125。
按設計,模型檢查器不執行你的實際程式碼,而是執行一個簡化的模型,該模型僅指定你的協議的核心思想。這使得系統地探索狀態空間更易處理,但有風險是你的規範和你的實現彼此不同步 126。可以檢查模型和真實實現是否具有等效行為,但這需要在真實實現中進行儀器化 127。
故障注入
許多錯誤是在機器和網路故障發生時觸發的。故障注入是一種有效(有時令人恐懼)的技術,用於驗證系統的實現在出錯時是否按預期工作。這個想法很簡單:將故障注入到正在執行的系統環境中,看看它如何表現。故障可以是網路故障、機器崩潰、磁碟損壞、暫停的程序 —— 你能想象到的計算機出錯的任何事情。
故障注入測試通常在與系統將執行的生產環境非常相似的環境中執行。有些甚至直接將故障注入到他們的生產環境中。Netflix 透過他們的 Chaos Monkey 工具推廣了這種方法 128。生產故障注入通常被稱為 混沌工程,我們在 “可靠性與容錯” 中討論過。
要執行故障注入測試,首先部署被測系統以及故障注入協調器和指令碼。協調器負責決定執行什麼故障以及何時執行它們。本地或遠端指令碼負責將故障注入到單個節點或程序中。注入指令碼使用許多不同的工具來觸發故障。可以使用 Linux 的 kill 命令暫停或殺死 Linux 程序,可以使用 umount 解除安裝磁碟,可以透過防火牆設定中斷網路連線。你可以在注入故障期間和之後檢查系統行為,以確保事情按預期工作。
觸發故障所需的無數工具使故障注入測試編寫起來很麻煩。採用像 Jepsen 這樣的故障注入框架來執行故障注入測試以簡化過程是常見的。這些框架帶有各種作業系統的整合和許多預構建的故障注入器 129。Jepsen 在許多廣泛使用的系統中發現關鍵錯誤方面非常有效 130 131。
確定性模擬測試
確定性模擬測試(DST)也已成為模型檢查和故障注入的流行補充。它使用與模型檢查器類似的狀態空間探索過程,但它測試你的實際程式碼,而不是模型。
在 DST 中,模擬自動執行系統的大量隨機執行。模擬期間的網路通訊、I/O 和時鐘時序都被模擬替換,允許模擬器控制事情發生的確切順序,包括各種時序和故障場景。這允許模擬器探索比手寫測試或故障注入更多的情況。如果測試失敗,它可以重新執行,因為模擬器知道觸發故障的確切操作順序 —— 與故障注入相比,後者對系統沒有如此細粒度的控制。
DST 要求模擬器能夠控制所有非確定性來源,例如網路延遲。通常採用三種策略之一來使程式碼確定性:
- 應用程式級
- 一些系統從頭開始構建,以便於確定性地執行程式碼。例如,DST 領域的先驅之一 FoundationDB 是使用稱為 Flow 的非同步通訊庫構建的。Flow 為開發人員提供了將確定性網路模擬注入系統的點 132。類似地,TigerBeetle 是一個具有一流 DST 支援的線上事務處理(OLTP)資料庫。系統的狀態被建模為狀態機,所有突變都發生在單個事件迴圈中。當與模擬確定性原語(如時鐘)結合時,這種架構能夠確定性地執行 133。
- 執行時級
- 具有非同步執行時和常用庫的語言提供了引入確定性的插入點。使用單執行緒執行時強制所有非同步程式碼按順序執行。例如,FrostDB 修補 Go 的執行時以按順序執行 goroutine 134。Rust 的 madsim 庫以類似的方式工作。Madsim 提供了 Tokio 的非同步執行時 API、AWS 的 S3 庫、Kafka 的 Rust 庫等的確定性實現。應用程式可以交換確定性庫和執行時以獲得確定性測試執行,而無需更改其程式碼。
- 機器級
- 與其在執行時修補程式碼,不如使整個機器確定性。這是一個微妙的過程,需要機器對所有通常非確定性的呼叫響應確定性響應。Antithesis 等工具透過構建自定義虛擬機器管理程式來做到這一點,該虛擬機器管理程式用確定性操作替換通常的非確定性操作。從時鐘到網路和儲存的一切都需要考慮。不過,一旦完成,開發人員可以在虛擬機器管理程式內的容器集合中執行其整個分散式系統,並獲得完全確定性的分散式系統。
DST 提供了超越可重放性的幾個優勢。Antithesis 等工具試圖透過在發現不太常見的行為時將測試執行分支為多個子執行來探索應用程式程式碼中的許多不同程式碼路徑。由於確定性測試通常使用模擬時鐘和網路呼叫,因此此類測試可以比掛鐘時間執行得更快。例如,TigerBeetle 的時間抽象允許模擬模擬網路延遲和超時,而實際上不需要觸發超時的全部時間長度。這些技術允許模擬器更快地探索更多程式碼路徑。
確定性的力量
非確定性是我們在本章中討論的所有分散式系統挑戰的核心:併發性、網路延遲、程序暫停、時鐘跳躍和崩潰都以不可預測的方式發生,從系統的一次執行到下一次執行都不同。相反,如果你能使系統確定性,那可以極大地簡化事情。
事實上,使事物確定性是一個簡單但強大的想法,在分散式系統設計中一再出現。除了確定性模擬測試,我們在過去的章節中已經看到了幾種使用確定性的方法:
- 事件溯源的一個關鍵優勢(見 “事件溯源和 CQRS”)是你可以確定性地重放事件日誌以重建派生的物化檢視。
- 工作流引擎(見 “持久執行和工作流”)依賴於工作流定義是確定性的,以提供持久執行語義。
- 狀態機複製,我們將在 “使用共享日誌” 中討論,透過在每個副本上獨立執行相同的確定性事務序列來複制資料。我們已經看到了這個想法的兩個變體:基於語句的複製(見 “複製日誌的實現”)和使用儲存過程的序列事務執行(見 “儲存過程的利弊”)。
然而,使程式碼完全確定性需要小心。即使你已經刪除了所有併發性並用確定性模擬替換了 I/O、網路通訊、時鐘和隨機數生成器,非確定性元素可能仍然存在。例如,在某些程式語言中,迭代雜湊表元素的順序可能是非確定性的。是否遇到資源限制(記憶體分配失敗、堆疊溢位)也是非確定性的。
總結
在本章中,我們討論了分散式系統中可能發生的各種問題,包括:
- 每當你嘗試透過網路傳送資料包時,它可能會丟失或任意延遲。同樣,回覆可能會丟失或延遲,所以如果你沒有得到回覆,你不知道訊息是否送達。
- 節點的時鐘可能與其他節點嚴重不同步(儘管你盡最大努力設定了 NTP),它可能會突然向前或向後跳躍,而依賴它是危險的,因為你很可能沒有一個好的時鐘置信區間度量。
- 程序可能在其執行的任何時刻暫停相當長的時間,被其他節點宣告死亡,然後再次恢復活動而沒有意識到它曾暫停。
這種 部分失效 可能發生的事實是分散式系統的決定性特徵。每當軟體嘗試做任何涉及其他節點的事情時,都有可能偶爾失敗、隨機變慢或根本沒有響應(並最終超時)。在分散式系統中,我們嘗試將對部分失效的容忍構建到軟體中,這樣即使某些組成部分出現故障,整個系統也可以繼續執行。
要容忍故障,第一步是 檢測 它們,但即使這樣也很困難。大多數系統沒有準確的機制來檢測節點是否已失敗,因此大多數分散式演算法依賴超時來確定遠端節點是否仍然可用。然而,超時無法區分網路和節點故障,可變的網路延遲有時會導致節點被錯誤地懷疑崩潰。處理跛行節點(limping nodes)更加困難,這些節點正在響應但速度太慢而無法做任何有用的事情。
一旦檢測到故障,讓系統容忍它也不容易:沒有全域性變數、沒有共享記憶體、沒有公共知識或機器之間任何其他型別的共享狀態 83。節點甚至無法就現在是什麼時間達成一致,更不用說任何更深刻的事情了。資訊從一個節點流向另一個節點的唯一方式是透過不可靠的網路傳送。單個節點無法安全地做出重大決策,因此我們需要協議來徵求其他節點的幫助並嘗試獲得法定人數的同意。
如果你習慣於在單臺計算機的理想數學完美環境中編寫軟體,其中相同的操作總是確定性地返回相同的結果,那麼轉向分散式系統混亂的物理現實可能會有點震驚。相反,分散式系統工程師通常會認為如果一個問題可以在單臺計算機上解決,那它就是微不足道的 4,而且單臺計算機現在確實可以做很多事情。如果你可以避免開啟潘多拉的盒子,只需將事情保持在單臺機器上,例如使用嵌入式儲存引擎(見 “嵌入式儲存引擎”),通常值得這樣做。
然而,正如在 “分散式系統與單節點系統” 中討論的,可伸縮性並不是使用分散式系統的唯一原因。容錯和低延遲(透過將資料在地理上放置在靠近使用者的位置)是同樣重要的目標,而這些事情無法透過單個節點實現。分散式系統的力量在於,原則上它們可以在服務層面永遠執行而不被中斷,因為所有故障和維護都可以在節點層面處理。(實際上,如果錯誤的配置更改被推送到所有節點,仍然會讓分散式系統崩潰。)
在本章中,我們還探討了網路、時鐘和程序的不可靠性是否是不可避免的自然法則。我們看到它不是:可以在網路中提供硬即時響應保證和有界延遲,但這樣做非常昂貴,並導致硬體資源利用率降低。大多數非安全關鍵系統選擇便宜和不可靠而不是昂貴和可靠。
本章一直在討論問題,給了我們一個暗淡的前景。在下一章中,我們將轉向解決方案,並討論一些為應對分散式系統中的問題而設計的演算法。
參考
Mark Cavage. There’s Just No Getting Around It: You’re Building a Distributed System. ACM Queue, volume 11, issue 4, pages 80-89, April 2013. doi:10.1145/2466486.2482856 ↩︎
Jay Kreps. Getting Real About Distributed System Reliability. blog.empathybox.com, March 2012. Archived at perma.cc/9B5Q-AEBW ↩︎
Coda Hale. You Can’t Sacrifice Partition Tolerance. codahale.com, October 2010. https://perma.cc/6GJU-X4G5 ↩︎
Jeff Hodges. Notes on Distributed Systems for Young Bloods. somethingsimilar.com, January 2013. Archived at perma.cc/B636-62CE ↩︎ ↩︎
Van Jacobson. Congestion Avoidance and Control. At ACM Symposium on Communications Architectures and Protocols (SIGCOMM), August 1988. doi:10.1145/52324.52356 ↩︎ ↩︎
Bert Hubert. The Ultimate SO_LINGER Page, or: Why Is My TCP Not Reliable. blog.netherlabs.nl, January 2009. Archived at perma.cc/6HDX-L2RR ↩︎ ↩︎
Jerome H. Saltzer, David P. Reed, and David D. Clark. End-To-End Arguments in System Design. ACM Transactions on Computer Systems, volume 2, issue 4, pages 277–288, November 1984. doi:10.1145/357401.357402 ↩︎
Peter Bailis and Kyle Kingsbury. The Network Is Reliable. ACM Queue, volume 12, issue 7, pages 48-55, July 2014. doi:10.1145/2639988.2639988 ↩︎ ↩︎
Joshua B. Leners, Trinabh Gupta, Marcos K. Aguilera, and Michael Walfish. Taming Uncertainty in Distributed Systems with Help from the Network. At 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741976 ↩︎ ↩︎
Phillipa Gill, Navendu Jain, and Nachiappan Nagappan. Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications. At ACM SIGCOMM Conference, August 2011. doi:10.1145/2018436.2018477 ↩︎
Urs Hölzle. But recently a farmer had started grazing a herd of cows nearby. And whenever they stepped on the fiber link, they bent it enough to cause a blip. x.com, May 2020. Archived at perma.cc/WX8X-ZZA5 ↩︎
CBC News. Hundreds lose internet service in northern B.C. after beaver chews through cable. cbc.ca, April 2021. Archived at perma.cc/UW8C-H2MY ↩︎
Will Oremus. The Global Internet Is Being Attacked by Sharks, Google Confirms. slate.com, August 2014. Archived at perma.cc/P6F3-C6YG ↩︎
Jess Auerbach Jahajeeah. Down to the wire: The ship fixing our internet. continent.substack.com, November 2023. Archived at perma.cc/DP7B-EQ7S ↩︎
Santosh Janardhan. More details about the October 4 outage. engineering.fb.com, October 2021. Archived at perma.cc/WW89-VSXH ↩︎
Tom Parfitt. Georgian woman cuts off web access to whole of Armenia. theguardian.com, April 2011. Archived at perma.cc/KMC3-N3NZ ↩︎
Antonio Voce, Tural Ahmedzade and Ashley Kirk. ‘Shadow fleets’ and subaquatic sabotage: are Europe’s undersea internet cables under attack? theguardian.com, March 2025. Archived at perma.cc/HA7S-ZDBV ↩︎
Shengyun Liu, Paolo Viotti, Christian Cachin, Vivien Quéma, and Marko Vukolić. XFT: Practical Fault Tolerance beyond Crashes. At 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), November 2016. ↩︎
Mark Imbriaco. Downtime last Saturday. github.blog, December 2012. Archived at perma.cc/M7X5-E8SQ ↩︎ ↩︎
Tom Lianza and Chris Snook. A Byzantine failure in the real world. blog.cloudflare.com, November 2020. Archived at perma.cc/83EZ-ALCY ↩︎ ↩︎
Mohammed Alfatafta, Basil Alkhatib, Ahmed Alquraan, and Samer Al-Kiswany. Toward a Generic Fault Tolerance Technique for Partial Network Partitioning. At 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI), November 2020. ↩︎
Marc A. Donges. Re: bnx2 cards Intermittantly Going Offline. Message to Linux netdev mailing list, spinics.net, September 2012. Archived at perma.cc/TXP6-H8R3 ↩︎ ↩︎
Troy Toman. Inside a CODE RED: Network Edition. signalvnoise.com, September 2020. Archived at perma.cc/BET6-FY25 ↩︎
Kyle Kingsbury. Call Me Maybe: Elasticsearch. aphyr.com, June 2014. perma.cc/JK47-S89J ↩︎
Salvatore Sanfilippo. A Few Arguments About Redis Sentinel Properties and Fail Scenarios. antirez.com, October 2014. perma.cc/8XEU-CLM8 ↩︎
Nicolas Liochon. CAP: If All You Have Is a Timeout, Everything Looks Like a Partition. blog.thislongrun.com, May 2015. Archived at perma.cc/FS57-V2PZ ↩︎
Matthew P. Grosvenor, Malte Schwarzkopf, Ionel Gog, Robert N. M. Watson, Andrew W. Moore, Steven Hand, and Jon Crowcroft. Queues Don’t Matter When You Can JUMP Them! At 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015. ↩︎ ↩︎
Theo Julienne. Debugging network stalls on Kubernetes. github.blog, November 2019. Archived at perma.cc/K9M8-XVGL ↩︎
Guohui Wang and T. S. Eugene Ng. The Impact of Virtualization on Network Performance of Amazon EC2 Data Center. At 29th IEEE International Conference on Computer Communications (INFOCOM), March 2010. doi:10.1109/INFCOM.2010.5461931 ↩︎ ↩︎
Brandon Philips. etcd: Distributed Locking and Service Discovery. At Strange Loop, September 2014. ↩︎
Steve Newman. A Systematic Look at EC2 I/O. blog.scalyr.com, October 2012. Archived at perma.cc/FL4R-H2VE ↩︎ ↩︎
Naohiro Hayashibara, Xavier Défago, Rami Yared, and Takuya Katayama. The ϕ Accrual Failure Detector. Japan Advanced Institute of Science and Technology, School of Information Science, Technical Report IS-RR-2004-010, May 2004. Archived at perma.cc/NSM2-TRYA ↩︎
Jeffrey Wang. Phi Accrual Failure Detector. ternarysearch.blogspot.co.uk, August 2013. perma.cc/L452-AMLV ↩︎
Srinivasan Keshav. An Engineering Approach to Computer Networking: ATM Networks, the Internet, and the Telephone Network. Addison-Wesley Professional, May 1997. ISBN: 978-0-201-63442-6 ↩︎ ↩︎
Othmar Kyas. ATM Networks. International Thomson Publishing, 1995. ISBN: 978-1-850-32128-6 ↩︎
Mellanox Technologies. InfiniBand FAQ, Rev 1.3. network.nvidia.com, December 2014. Archived at perma.cc/LQJ4-QZVK ↩︎
Jose Renato Santos, Yoshio Turner, and G. (John) Janakiraman. End-to-End Congestion Control for InfiniBand. At 22nd Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM), April 2003. Also published by HP Laboratories Palo Alto, Tech Report HPL-2002-359. doi:10.1109/INFCOM.2003.1208949 ↩︎
Jialin Li, Naveen Kr. Sharma, Dan R. K. Ports, and Steven D. Gribble. Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency. At ACM Symposium on Cloud Computing (SOCC), November 2014. doi:10.1145/2670979.2670988 ↩︎
Ulrich Windl, David Dalton, Marc Martinec, and Dale R. Worley. The NTP FAQ and HOWTO. ntp.org, November 2006. ↩︎ ↩︎ ↩︎
John Graham-Cumming. How and why the leap second affected Cloudflare DNS. blog.cloudflare.com, January 2017. Archived at archive.org ↩︎ ↩︎
David Holmes. Inside the Hotspot VM: Clocks, Timers and Scheduling Events – Part I – Windows. blogs.oracle.com, October 2006. Archived at archive.org ↩︎
Joran Dirk Greef. Three Clocks are Better than One. tigerbeetle.com, August 2021. Archived at perma.cc/5RXG-EU6B ↩︎
Oliver Yang. Pitfalls of TSC usage. oliveryang.net, September 2015. Archived at perma.cc/Z2QY-5FRA ↩︎
Steve Loughran. Time on Multi-Core, Multi-Socket Servers. steveloughran.blogspot.co.uk, September 2015. Archived at perma.cc/7M4S-D4U6 ↩︎
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. Spanner: Google’s Globally-Distributed Database. At 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012. ↩︎ ↩︎ ↩︎
M. Caporaloni and R. Ambrosini. How Closely Can a Personal Computer Clock Track the UTC Timescale Via the Internet? European Journal of Physics, volume 23, issue 4, pages L17–L21, June 2012. doi:10.1088/0143-0807/23/4/103 ↩︎
Nelson Minar. A Survey of the NTP Network. alumni.media.mit.edu, December 1999. Archived at perma.cc/EV76-7ZV3 ↩︎
Viliam Holub. Synchronizing Clocks in a Cassandra Cluster Pt. 1 – The Problem. blog.rapid7.com, March 2014. Archived at perma.cc/N3RV-5LNL ↩︎
Poul-Henning Kamp. The One-Second War (What Time Will You Die?) ACM Queue, volume 9, issue 4, pages 44–48, April 2011. doi:10.1145/1966989.1967009 ↩︎
Nelson Minar. Leap Second Crashes Half the Internet. somebits.com, July 2012. Archived at perma.cc/2WB8-D6EU ↩︎
Christopher Pascoe. Time, Technology and Leaping Seconds. googleblog.blogspot.co.uk, September 2011. Archived at perma.cc/U2JL-7E74 ↩︎
Mingxue Zhao and Jeff Barr. Look Before You Leap – The Coming Leap Second and AWS. aws.amazon.com, May 2015. Archived at perma.cc/KPE9-XMFM ↩︎
Darryl Veitch and Kanthaiah Vijayalayan. Network Timing and the 2015 Leap Second. At 17th International Conference on Passive and Active Measurement (PAM), April 2016. doi:10.1007/978-3-319-30505-9_29 ↩︎
VMware, Inc. Timekeeping in VMware Virtual Machines. vmware.com, October 2008. Archived at perma.cc/HM5R-T5NF ↩︎
Victor Yodaiken. Clock Synchronization in Finance and Beyond. yodaiken.com, November 2017. Archived at perma.cc/9XZD-8ZZN ↩︎
Mustafa Emre Acer, Emily Stark, Adrienne Porter Felt, Sascha Fahl, Radhika Bhargava, Bhanu Dev, Matt Braithwaite, Ryan Sleevi, and Parisa Tabriz. Where the Wild Warnings Are: Root Causes of Chrome HTTPS Certificate Errors. At ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 1407–1420, October 2017. doi:10.1145/3133956.3134007 ↩︎
European Securities and Markets Authority. MiFID II / MiFIR: Regulatory Technical and Implementing Standards – Annex I. esma.europa.eu, Report ESMA/2015/1464, September 2015. Archived at perma.cc/ZLX9-FGQ3 ↩︎
Luke Bigum. Solving MiFID II Clock Synchronisation With Minimum Spend (Part 1). catach.blogspot.com, November 2015. Archived at perma.cc/4J5W-FNM4 ↩︎
Oleg Obleukhov and Ahmad Byagowi. How Precision Time Protocol is being deployed at Meta. engineering.fb.com, November 2022. Archived at perma.cc/29G6-UJNW ↩︎
John Wiseman. gpsjam.org, July 2022. ↩︎
Josh Levinson, Julien Ridoux, and Chris Munns. It’s About Time: Microsecond-Accurate Clocks on Amazon EC2 Instances. aws.amazon.com, November 2023. Archived at perma.cc/56M6-5VMZ ↩︎
Kyle Kingsbury. Call Me Maybe: Cassandra. aphyr.com, September 2013. Archived at perma.cc/4MBR-J96V ↩︎ ↩︎ ↩︎
John Daily. Clocks Are Bad, or, Welcome to the Wonderful World of Distributed Systems. riak.com, November 2013. Archived at perma.cc/4XB5-UCXY ↩︎ ↩︎
Marc Brooker. It’s About Time! brooker.co.za, November 2023. Archived at perma.cc/N6YK-DRPA ↩︎
Kyle Kingsbury. The Trouble with Timestamps. aphyr.com, October 2013. Archived at perma.cc/W3AM-5VAV ↩︎
Leslie Lamport. Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, volume 21, issue 7, pages 558–565, July 1978. doi:10.1145/359545.359563 ↩︎
Justin Sheehy. There Is No Now: Problems With Simultaneity in Distributed Systems. ACM Queue, volume 13, issue 3, pages 36–41, March 2015. doi:10.1145/2733108 ↩︎
Murat Demirbas. Spanner: Google’s Globally-Distributed Database. muratbuffalo.blogspot.co.uk, July 2013. Archived at perma.cc/6VWR-C9WB ↩︎
Dahlia Malkhi and Jean-Philippe Martin. Spanner’s Concurrency Control. ACM SIGACT News, volume 44, issue 3, pages 73–77, September 2013. doi:10.1145/2527748.2527767 ↩︎
Franck Pachot. Achieving Precise Clock Synchronization on AWS. yugabyte.com, December 2024. Archived at perma.cc/UYM6-RNBS ↩︎
Spencer Kimball. Living Without Atomic Clocks: Where CockroachDB and Spanner diverge. cockroachlabs.com, January 2022. Archived at perma.cc/AWZ7-RXFT ↩︎
Murat Demirbas. Use of Time in Distributed Databases (part 4): Synchronized clocks in production databases. muratbuffalo.blogspot.com, January 2025. Archived at perma.cc/9WNX-Q9U3 ↩︎
Cary G. Gray and David R. Cheriton. Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency. At 12th ACM Symposium on Operating Systems Principles (SOSP), December 1989. doi:10.1145/74850.74870 ↩︎
Daniel Sturman, Scott Delap, Max Ross, et al. Roblox Return to Service. corp.roblox.com, January 2022. Archived at perma.cc/8ALT-WAS4 ↩︎
Todd Lipcon. Avoiding Full GCs with MemStore-Local Allocation Buffers. slideshare.net, February 2011. Archived at https://perma.cc/CH62-2EWJ ↩︎
Christopher Clark, Keir Fraser, Steven Hand, Jacob Gorm Hansen, Eric Jul, Christian Limpach, Ian Pratt, and Andrew Warfield. Live Migration of Virtual Machines. At 2nd USENIX Symposium on Symposium on Networked Systems Design & Implementation (NSDI), May 2005. ↩︎
Mike Shaver. fsyncers and Curveballs. shaver.off.net, May 2008. Archived at archive.org ↩︎
Zhenyun Zhuang and Cuong Tran. Eliminating Large JVM GC Pauses Caused by Background IO Traffic. engineering.linkedin.com, February 2016. Archived at perma.cc/ML2M-X9XT ↩︎
Martin Thompson. Java Garbage Collection Distilled. mechanical-sympathy.blogspot.co.uk, July 2013. Archived at perma.cc/DJT3-NQLQ ↩︎ ↩︎
David Terei and Amit Levy. Blade: A Data Center Garbage Collector. arXiv:1504.02578, April 2015. ↩︎
Martin Maas, Tim Harris, Krste Asanović, and John Kubiatowicz. Trash Day: Coordinating Garbage Collection in Distributed Systems. At 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015. ↩︎
Martin Fowler. The LMAX Architecture. martinfowler.com, July 2011. Archived at perma.cc/5AV4-N6RJ ↩︎
Joseph Y. Halpern and Yoram Moses. Knowledge and common knowledge in a distributed environment. Journal of the ACM (JACM), volume 37, issue 3, pages 549–587, July 1990. doi:10.1145/79147.79161 ↩︎ ↩︎
Chuzhe Tang, Zhaoguo Wang, Xiaodong Zhang, Qianmian Yu, Binyu Zang, Haibing Guan, and Haibo Chen. Ad Hoc Transactions in Web Applications: The Good, the Bad, and the Ugly. At ACM International Conference on Management of Data (SIGMOD), June 2022. doi:10.1145/3514221.3526120 ↩︎
Flavio P. Junqueira and Benjamin Reed. ZooKeeper: Distributed Process Coordination. O’Reilly Media, 2013. ISBN: 978-1-449-36130-3 ↩︎ ↩︎
Enis Söztutar. HBase and HDFS: Understanding Filesystem Usage in HBase. At HBaseCon, June 2013. Archived at perma.cc/4DXR-9P88 ↩︎
SUSE LLC. SUSE Linux Enterprise High Availability 15 SP6 Administration Guide, Section 12: Fencing and STONITH. documentation.suse.com, March 2025. Archived at perma.cc/8LAR-EL9D ↩︎
Mike Burrows. The Chubby Lock Service for Loosely-Coupled Distributed Systems. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006. ↩︎
Kyle Kingsbury. etcd 3.4.3. jepsen.io, January 2020. Archived at perma.cc/2P3Y-MPWU ↩︎
Ensar Basri Kahveci. Distributed Locks are Dead; Long Live Distributed Locks! hazelcast.com, April 2019. Archived at perma.cc/7FS5-LDXE ↩︎
Martin Kleppmann. How to do distributed locking. martin.kleppmann.com, February 2016. Archived at perma.cc/Y24W-YQ5L ↩︎
Salvatore Sanfilippo. Is Redlock safe? antirez.com, February 2016. Archived at perma.cc/B6GA-9Q6A ↩︎
Gunnar Morling. Leader Election With S3 Conditional Writes. www.morling.dev, August 2024. Archived at perma.cc/7V2N-J78Y ↩︎
Leslie Lamport, Robert Shostak, and Marshall Pease. The Byzantine Generals Problem. ACM Transactions on Programming Languages and Systems (TOPLAS), volume 4, issue 3, pages 382–401, July 1982. doi:10.1145/357172.357176 ↩︎
Jim N. Gray. Notes on Data Base Operating Systems. in Operating Systems: An Advanced Course, Lecture Notes in Computer Science, volume 60, edited by R. Bayer, R. M. Graham, and G. Seegmüller, pages 393–481, Springer-Verlag, 1978. ISBN: 978-3-540-08755-7. Archived at perma.cc/7S9M-2LZU ↩︎
Brian Palmer. How Complicated Was the Byzantine Empire? slate.com, October 2011. Archived at perma.cc/AN7X-FL3N ↩︎
Leslie Lamport. My Writings. lamport.azurewebsites.net, December 2014. Archived at perma.cc/5NNM-SQGR ↩︎
John Rushby. Bus Architectures for Safety-Critical Embedded Systems. At 1st International Workshop on Embedded Software (EMSOFT), October 2001. doi:10.1007/3-540-45449-7_22 ↩︎ ↩︎
Jake Edge. ELC: SpaceX Lessons Learned. lwn.net, March 2013. Archived at perma.cc/AYX8-QP5X ↩︎
Shehar Bano, Alberto Sonnino, Mustafa Al-Bassam, Sarah Azouvi, Patrick McCorry, Sarah Meiklejohn, and George Danezis. SoK: Consensus in the Age of Blockchains. At 1st ACM Conference on Advances in Financial Technologies (AFT), October 2019. doi:10.1145/3318041.3355458 ↩︎
Ezra Feilden, Adi Oltean, and Philip Johnston. Why we should train AI in space. White Paper, starcloud.com, September 2024. Archived at perma.cc/7Y3S-8UB6 ↩︎
James Mickens. The Saddest Moment. USENIX ;login, May 2013. Archived at perma.cc/T7BZ-XCFR ↩︎
Martin Kleppmann and Heidi Howard. Byzantine Eventual Consistency and the Fundamental Limits of Peer-to-Peer Databases. arxiv.org, December 2020. doi:10.48550/arXiv.2012.00472 ↩︎
Martin Kleppmann. Making CRDTs Byzantine Fault Tolerant. At 9th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC), April 2022. doi:10.1145/3517209.3524042 ↩︎
Evan Gilman. The Discovery of Apache ZooKeeper’s Poison Packet. pagerduty.com, May 2015. Archived at perma.cc/RV6L-Y5CQ ↩︎ ↩︎
Jonathan Stone and Craig Partridge. When the CRC and TCP Checksum Disagree. At ACM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (SIGCOMM), August 2000. doi:10.1145/347059.347561 ↩︎
Evan Jones. How Both TCP and Ethernet Checksums Fail. evanjones.ca, October 2015. Archived at perma.cc/9T5V-B8X5 ↩︎
Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer. Consensus in the Presence of Partial Synchrony. Journal of the ACM, volume 35, issue 2, pages 288–323, April 1988. doi:10.1145/42282.42283 ↩︎ ↩︎ ↩︎
Richard D. Schlichting and Fred B. Schneider. Fail-stop processors: an approach to designing fault-tolerant computing systems. ACM Transactions on Computer Systems (TOCS), volume 1, issue 3, pages 222–238, August 1983. doi:10.1145/357369.357371 ↩︎
Thanh Do, Mingzhe Hao, Tanakorn Leesatapornwongsa, Tiratat Patana-anake, and Haryadi S. Gunawi. Limplock: Understanding the Impact of Limpware on Scale-out Cloud Systems. At 4th ACM Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523627 ↩︎
Josh Snyder and Joseph Lynch. Garbage collecting unhealthy JVMs, a proactive approach. Netflix Technology Blog, netflixtechblog.medium.com, November 2019. Archived at perma.cc/8BTA-N3YB ↩︎
Haryadi S. Gunawi, Riza O. Suminto, Russell Sears, Casey Golliher, Swaminathan Sundararaman, Xing Lin, Tim Emami, Weiguang Sheng, Nematollah Bidokhti, Caitie McCaffrey, Gary Grider, Parks M. Fields, Kevin Harms, Robert B. Ross, Andree Jacobson, Robert Ricci, Kirk Webb, Peter Alvaro, H. Birali Runesha, Mingzhe Hao, and Huaicheng Li. Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems. At 16th USENIX Conference on File and Storage Technologies, February 2018. ↩︎
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. At 16th Workshop on Hot Topics in Operating Systems (HotOS), May 2017. doi:10.1145/3102980.3103005 ↩︎
Chang Lou, Peng Huang, and Scott Smith. Understanding, Detecting and Localizing Partial Failures in Large System Software. At 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), February 2020. ↩︎
Peter Bailis and Ali Ghodsi. Eventual Consistency Today: Limitations, Extensions, and Beyond. ACM Queue, volume 11, issue 3, pages 55-63, March 2013. doi:10.1145/2460276.2462076 ↩︎
Bowen Alpern and Fred B. Schneider. Defining Liveness. Information Processing Letters, volume 21, issue 4, pages 181–185, October 1985. doi:10.1016/0020-0190(85)90056-0 ↩︎
Flavio P. Junqueira. Dude, Where’s My Metadata? fpj.me, May 2015. Archived at perma.cc/D2EU-Y9S5 ↩︎
Scott Sanders. January 28th Incident Report. github.com, February 2016. Archived at perma.cc/5GZR-88TV ↩︎
Jay Kreps. A Few Notes on Kafka and Jepsen. blog.empathybox.com, September 2013. perma.cc/XJ5C-F583 ↩︎
Marc Brooker and Ankush Desai. Systems Correctness Practices at AWS. Queue, Volume 22, Issue 6, November/December 2024. doi:10.1145/3712057 ↩︎
Andrey Satarin. Testing Distributed Systems: Curated list of resources on testing distributed systems. asatarin.github.io. Archived at perma.cc/U5V8-XP24 ↩︎
Jack Vanlightly. Verifying Kafka transactions - Diary entry 2 - Writing an initial TLA+ spec. jack-vanlightly.com, December 2024. Archived at perma.cc/NSQ8-MQ5N ↩︎
Siddon Tang. From Chaos to Order — Tools and Techniques for Testing TiDB, A Distributed NewSQL Database. pingcap.com, April 2018. Archived at perma.cc/5EJB-R29F ↩︎
Nathan VanBenschoten. Parallel Commits: An atomic commit protocol for globally distributed transactions. cockroachlabs.com, November 2019. Archived at perma.cc/5FZ7-QK6J ↩︎
Jack Vanlightly. Paper: VR Revisited - State Transfer (part 3). jack-vanlightly.com, December 2022. Archived at perma.cc/KNK3-K6WS ↩︎
Hillel Wayne. What if the spec doesn’t match the code? buttondown.com, March 2024. Archived at perma.cc/8HEZ-KHER ↩︎
Lingzhi Ouyang, Xudong Sun, Ruize Tang, Yu Huang, Madhav Jivrajani, Xiaoxing Ma, Tianyin Xu. Multi-Grained Specifications for Distributed System Model Checking and Verification. At 20th European Conference on Computer Systems (EuroSys), March 2025. doi:10.1145/3689031.3696069 ↩︎
Yury Izrailevsky and Ariel Tseitlin. The Netflix Simian Army. netflixtechblog.com, July, 2011. Archived at perma.cc/M3NY-FJW6 ↩︎
Kyle Kingsbury. Jepsen: On the perils of network partitions. aphyr.com, May, 2013. Archived at perma.cc/W98G-6HQP ↩︎
Kyle Kingsbury. Jepsen Analyses. jepsen.io, 2024. Archived at perma.cc/8LDN-D2T8 ↩︎
Rupak Majumdar and Filip Niksic. Why is random testing effective for partition tolerance bugs? Proceedings of the ACM on Programming Languages (PACMPL), volume 2, issue POPL, article no. 46, December 2017. doi:10.1145/3158134 ↩︎
FoundationDB project authors. Simulation and Testing. apple.github.io. Archived at perma.cc/NQ3L-PM4C ↩︎
Alex Kladov. Simulation Testing For Liveness. tigerbeetle.com, July 2023. Archived at perma.cc/RKD4-HGCR ↩︎
Alfonso Subiotto Marqués. (Mostly) Deterministic Simulation Testing in Go. polarsignals.com, May 2024. Archived at perma.cc/ULD6-TSA4 ↩︎