7. 分片
顯然,我們必須跳出順序計算機指令的窠臼。我們必須敘述定義、提供優先順序和資料描述。我們必須敘述關係,而不是過程。
Grace Murray Hopper,《未來的計算機及其管理》(1962)
分散式資料庫通常透過兩種方式在節點間分佈資料:
- 在多個節點上儲存相同資料的副本:這是 複製,我們在 第 6 章 中討論過。
- 如果我們不想讓每個節點都儲存所有資料,我們可以將大量資料分割成更小的 分片(shards) 或 分割槽(partitions),並將不同的分片儲存在不同的節點上。我們將在本章討論分片。
通常,分片的定義方式使得每條資料(每條記錄、行或文件)恰好屬於一個分片。有多種方法可以實現這一點,我們將在本章深入討論。實際上,每個分片本身就是一個小型資料庫,儘管某些資料庫系統支援同時涉及多個分片的操作。
分片通常與複製結合使用,以便每個分片的副本儲存在多個節點上。這意味著,即使每條記錄屬於恰好一個分片,它仍然可以儲存在多個不同的節點上以提供容錯能力。
一個節點可能儲存多個分片。如果使用單主複製模型,分片和複製的組合可能看起來像 圖 7-1,例如。每個分片的主節點被分配給一個節點,其從節點被分配給其他節點。每個節點可能是某些分片的主節點,同時是其他分片的從節點。
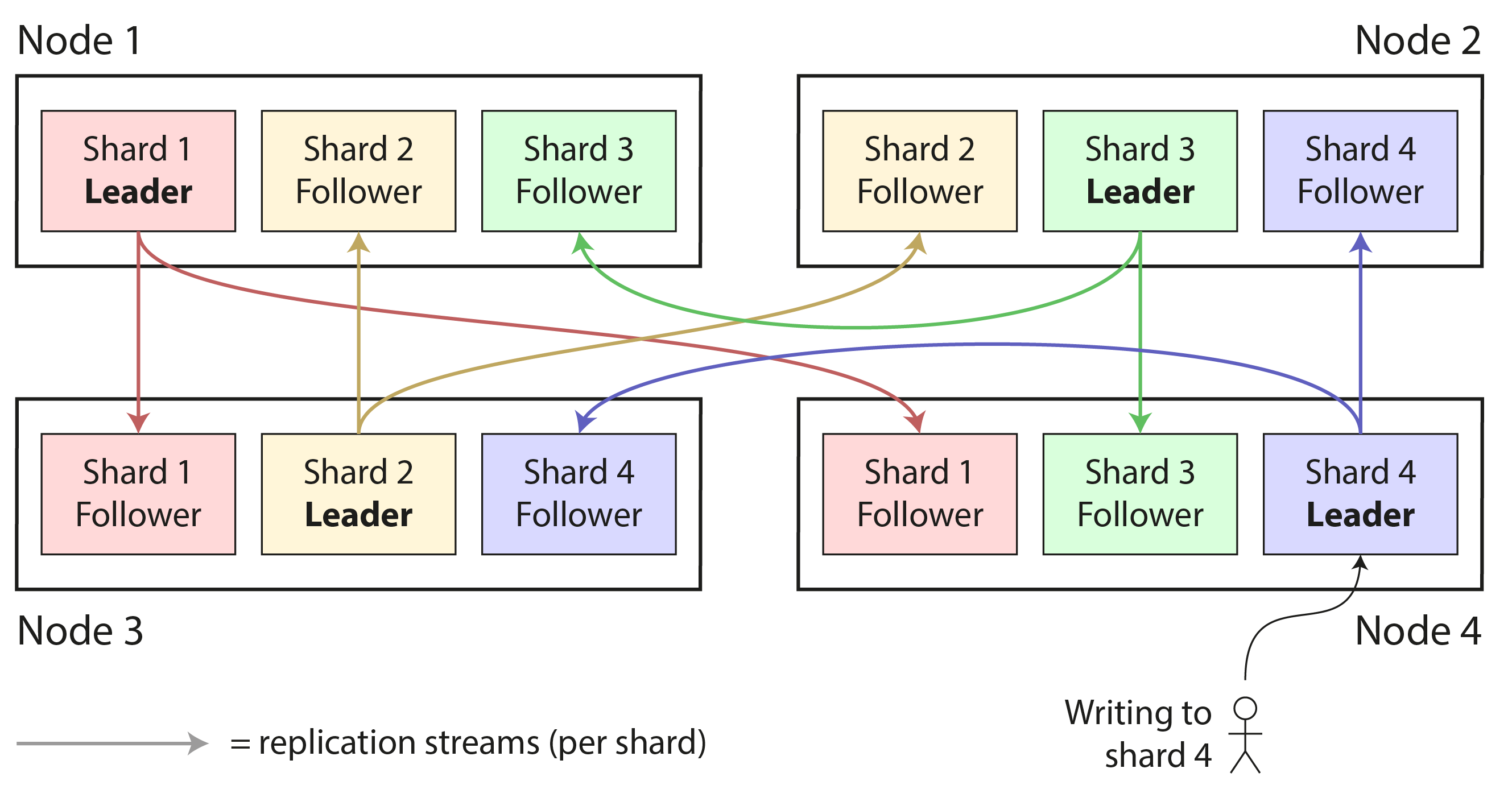
我們在 第 6 章 中討論的關於資料庫複製的所有內容同樣適用於分片的複製。由於分片方案的選擇大部分獨立於複製方案的選擇,為了簡單起見,我們將在本章中忽略複製。
分片和分割槽
在本章中我們稱之為 分片 的東西,根據你使用的軟體不同有許多不同的名稱:在 Kafka 中稱為 分割槽(partition),在 CockroachDB 中稱為 範圍(range),在 HBase 和 TiDB 中稱為 區域(region),在 Bigtable 和 YugabyteDB 中稱為 表塊(tablet),在 Cassandra、ScyllaDB 和 Riak 中稱為 虛節點(vnode),在 Couchbase 中稱為 虛桶(vBucket),僅舉幾例。
一些資料庫將分割槽和分片視為兩個不同的概念。例如,在 PostgreSQL 中,分割槽是將大表拆分為儲存在同一臺機器上的多個檔案的方法(這有幾個優點,例如可以非常快速地刪除整個分割槽),而分片則是將資料集拆分到多臺機器上 1 2。在許多其他系統中,分割槽只是分片的另一個詞。
雖然 分割槽 相當具有描述性,但 分片 這個術語可能令人驚訝。根據一種理論,該術語源於線上角色扮演遊戲《網路創世紀》(Ultima Online),其中一塊魔法水晶被打碎成碎片,每個碎片都折射出遊戲世界的副本 3。分片 一詞因此用來指一組並行遊戲伺服器中的一個,後來被引入資料庫。另一種理論是 分片 最初是 高可用複製資料系統(System for Highly Available Replicated Data)的縮寫——據說是 1980 年代的一個數據庫,其細節已經失傳。
順便說一下,分割槽與 網路分割槽(netsplits)無關,後者是節點之間網路中的一種故障。我們將在 第 9 章 中討論此類故障。
分片的利與弊
對資料庫進行分片的主要原因是 可伸縮性:如果資料量或寫吞吐量已經超出單個節點的處理能力,這是一個解決方案,它允許你將資料和寫入分散到多個節點上。(如果讀吞吐量是問題,你不一定需要分片——你可以使用 第 6 章 中討論的 讀擴充套件。)
事實上,分片是我們實現 水平擴充套件(橫向擴充套件 架構)的主要工具之一,如 “共享記憶體、共享磁碟和無共享架構” 中所討論的:即,允許系統透過新增更多(較小的)機器而不是轉移到更大的機器來增長其容量。如果你可以劃分工作負載,使每個分片處理大致相等的份額,那麼你可以將這些分片分配給不同的機器,以便並行處理它們的資料和查詢。
雖然複製在小規模和大規模上都很有用,因為它支援容錯和離線操作,但分片是一個重量級解決方案,主要在大規模場景下才有意義。如果你的資料量和寫吞吐量可以在單臺機器上處理(而單臺機器現在可以做很多事情!),通常最好避免分片並堅持使用單分片資料庫。
推薦這樣做的原因是分片通常會增加複雜性:你通常必須透過選擇 分割槽鍵 來決定將哪些記錄放在哪個分片中;具有相同分割槽鍵的所有記錄都放在同一個分片中 4。這個選擇很重要,因為如果你知道記錄在哪個分片中,訪問記錄會很快,但如果你不知道分片,你必須在所有分片中進行低效的搜尋,而且分片方案很難更改。
因此,分片通常適用於鍵值資料,你可以輕鬆地按鍵進行分片,但對於關係資料則較難,因為你可能想要透過二級索引搜尋,或連線可能分佈在不同分片中的記錄。我們將在 “分片與二級索引” 中進一步討論這個問題。
分片的另一個問題是寫入可能需要更新多個不同分片中的相關記錄。雖然單節點上的事務相當常見(見 第 8 章),但確保跨多個分片的一致性需要 分散式事務。正如我們將在 第 8 章 中看到的,分散式事務在某些資料庫中可用,但它們通常比單節點事務慢得多,可能成為整個系統的瓶頸,有些系統根本不支援它們。
一些系統即使在單臺機器上也使用分片,通常每個 CPU 核心執行一個單執行緒程序以利用 CPU 中的並行性,或者利用 非一致性記憶體訪問(NUMA)架構,其中某些記憶體庫比其他記憶體庫更接近某個 CPU 5。例如,Redis、VoltDB 和 FoundationDB 每個核心使用一個程序,並依靠分片在同一臺機器的 CPU 核心之間分散負載 6。
面向多租戶的分片
軟體即服務(SaaS)產品和雲服務通常是 多租戶 的,其中每個租戶是一個客戶。多個使用者可能在同一租戶上擁有登入帳戶,但每個租戶都有一個獨立的資料集,與其他租戶分開。例如,在電子郵件營銷服務中,每個註冊的企業通常是一個單獨的租戶,因為一個企業的通訊訂閱、投遞資料等與其他企業的資料是分開的。
有時分片用於實現多租戶系統:要麼每個租戶被分配一個單獨的分片,要麼多個小租戶可能被分組到一個更大的分片中。這些分片可能是物理上分離的資料庫(我們之前在 “嵌入式儲存引擎” 中提到過),或者是更大邏輯資料庫的可單獨管理部分 7。使用分片實現多租戶有幾個優點:
- 資源隔離
- 如果一個租戶執行計算密集型操作,如果它們在不同的分片上執行,其他租戶的效能受影響的可能性較小。
- 許可權隔離
- 如果你的訪問控制邏輯中存在錯誤,如果這些租戶的資料集彼此物理分離儲存,你意外地給一個租戶訪問另一個租戶資料的可能性較小。
- 基於單元的架構
- 你不僅可以在資料儲存級別應用分片,還可以為執行應用程式程式碼的服務應用分片。在 基於單元的架構 中,特定租戶集的服務和儲存被分組到一個自包含的 單元 中,不同的單元被設定為可以在很大程度上彼此獨立執行。這種方法提供了 故障隔離:即,一個單元中的故障僅限於該單元,其他單元中的租戶不受影響 8。
- 按租戶備份和恢復
- 單獨備份每個租戶的分片使得可以從備份中恢復租戶的狀態而不影響其他租戶,這在租戶意外刪除或覆蓋重要資料的情況下很有用 9。
- 法規合規性
- 資料隱私法規(如 GDPR)賦予個人訪問和刪除儲存的所有關於他們的資料的權利。如果每個人的資料儲存在單獨的分片中,這就轉化為對其分片的簡單資料匯出和刪除操作 10。
- 資料駐留
- 如果特定租戶的資料需要儲存在特定司法管轄區以符合資料駐留法律,具有區域感知的資料庫可以允許你將該租戶的分片分配給特定區域。
- 漸進式模式推出
- 模式遷移(之前在 “文件模型中的模式靈活性” 中討論過)可以逐步推出,一次一個租戶。這降低了風險,因為你可以在影響所有租戶之前檢測到問題,但很難以事務方式執行 11。
使用分片實現多租戶的主要挑戰是:
- 它假設每個單獨的租戶都足夠小,可以適應單個節點。如果情況並非如此,並且你有一個對於一臺機器來說太大的租戶,你將需要在單個租戶內額外執行分片,這將我們帶回到為可伸縮性進行分片的主題 12。
- 如果你有許多小租戶,那麼為每個租戶建立單獨的分片可能會產生太多開銷。你可以將幾個小租戶組合到一個更大的分片中,但隨後你會遇到如何在租戶增長時將其從一個分片移動到另一個分片的問題。
- 如果你需要支援跨多個租戶連線資料的功能,如果你需要跨多個分片連線資料,這些功能將變得更難實現。
鍵值資料的分片
假設你有大量資料,並且想要對其進行分片。如何決定將哪些記錄儲存在哪些節點上?
我們進行分片的目標是將資料和查詢負載均勻地分佈在各節點上。如果每個節點承擔公平的份額,那麼理論上——10 個節點應該能夠處理 10 倍的資料量和 10 倍單個節點的讀寫吞吐量(忽略複製)。此外,如果我們新增或刪除節點,我們希望能夠 再平衡 負載,使其在新增時均勻分佈在 11 個節點上(或刪除時在剩餘的 9 個節點上)。
如果分片不公平,使得某些分片比其他分片有更多的資料或查詢,我們稱之為 傾斜。傾斜的存在使分片的效果大打折扣。在極端情況下,所有負載可能最終集中在一個分片上,因此 10 個節點中有 9 個處於空閒狀態,你的瓶頸是單個繁忙的節點。具有不成比例高負載的分片稱為 熱分片 或 熱點。如果有一個鍵具有特別高的負載(例如,社交網路中的名人),我們稱之為 熱鍵。
因此,我們需要一種演算法,它以記錄的分割槽鍵作為輸入,並告訴我們該記錄在哪個分片中。在鍵值儲存中,分割槽鍵通常是鍵,或鍵的第一部分。在關係模型中,分割槽鍵可能是表的某一列(不一定是其主鍵)。該演算法需要能夠進行再平衡以緩解熱點。
按鍵的範圍分片
一種分片方法是為每個分片分配一個連續的分割槽鍵範圍(從某個最小值到某個最大值),就像紙質百科全書的卷一樣,如 圖 7-2 所示。在這個例子中,條目的分割槽鍵是其標題。如果你想查詢特定標題的條目,你可以透過找到鍵範圍包含你要查詢標題的捲來輕鬆確定哪個分片包含該條目,從而從書架上挑選正確的書。

鍵的範圍不一定是均勻分佈的,因為你的資料可能不是均勻分佈的。例如,在 圖 7-2 中,第 1 捲包含以 A 和 B 開頭的單詞,但第 12 捲包含以 T、U、V、W、X、Y 和 Z 開頭的單詞。簡單地為字母表的每兩個字母分配一卷會導致某些卷比其他卷大得多。為了均勻分佈資料,分片邊界需要適應資料。
分片邊界可能由管理員手動選擇,或者資料庫可以自動選擇它們。手動鍵範圍分片例如被 Vitess(MySQL 的分片層)使用;自動變體被 Bigtable、其開源等價物 HBase、MongoDB 中基於範圍的分片選項、CockroachDB、RethinkDB 和 FoundationDB 使用 6。YugabyteDB 提供手動和自動錶塊分割兩種選項。
在每個分片內,鍵以排序順序儲存(例如,在 B 樹或 SSTable 中,如 第 4 章 中所討論的)。這樣做的優點是範圍掃描很容易,你可以將鍵視為連線索引,以便在一個查詢中獲取多個相關記錄(參見 “多維和全文索引”)。例如,考慮一個儲存感測器網路資料的應用程式,其中鍵是測量的時間戳。範圍掃描在這種情況下非常有用,因為它們讓你可以輕鬆獲取,比如說,特定月份的所有讀數。
鍵範圍分片的一個缺點是,如果有大量對相鄰鍵的寫入,你很容易得到一個熱分片。例如,如果鍵是時間戳,那麼分片對應於時間範圍——例如,每個月一個分片。不幸的是,如果你在測量發生時將感測器資料寫入資料庫,所有寫入最終都會進入同一個分片(本月的分片),因此該分片可能會因寫入而過載,而其他分片則處於空閒狀態 13。
為了避免感測器資料庫中的這個問題,你需要使用時間戳以外的東西作為鍵的第一個元素。例如,你可以在每個時間戳前加上感測器 ID,使鍵排序首先按感測器 ID,然後按時間戳。假設你有許多感測器同時活動,寫入負載最終會更均勻地分佈在各個分片上。缺點是當你想要在一個時間範圍內獲取多個感測器的值時,你現在需要為每個感測器執行單獨的範圍查詢。
重新平衡鍵範圍分片資料
當你首次設定資料庫時,沒有鍵範圍可以分割成分片。一些資料庫,如 HBase 和 MongoDB,允許你在空資料庫上配置一組初始分片,這稱為 預分割。這要求你已經對鍵分佈將會是什麼樣子有所瞭解,以便你可以選擇適當的鍵範圍邊界 14。
後來,隨著你的資料量和寫吞吐量增長,具有鍵範圍分片的系統透過將現有分片分割成兩個或更多較小的分片來增長,每個分片都儲存原始分片鍵範圍的連續子範圍。然後可以將生成的較小分片分佈在多個節點上。如果刪除了大量資料,你可能還需要將幾個相鄰的已變小的分片合併為一個更大的分片。這個過程類似於 B 樹頂層發生的事情(參見 “B 樹”)。
對於自動管理分片邊界的資料庫,分片分割通常由以下觸發:
- 分片達到配置的大小(例如,在 HBase 上,預設值為 10 GB),或
- 在某些系統中,寫吞吐量持續高於某個閾值。因此,即使熱分片沒有儲存大量資料,也可能被分割,以便其寫入負載可以更均勻地分佈。
鍵範圍分片的一個優點是分片數量適應資料量。如果只有少量資料,少量分片就足夠了,因此開銷很小;如果有大量資料,每個單獨分片的大小被限制在可配置的最大值 15。
這種方法的一個缺點是分割分片是一項昂貴的操作,因為它需要將其所有資料重寫到新檔案中,類似於日誌結構儲存引擎中的壓實。需要分割的分片通常也是處於高負載下的分片,分割的成本可能會加劇該負載,有使其過載的風險。
按鍵的雜湊分片
鍵範圍分片在你希望具有相鄰(但不同)分割槽鍵的記錄被分組到同一個分片中時很有用;例如,如果是時間戳,這可能就是這種情況。如果你不關心分割槽鍵是否彼此接近(例如,如果它們是多租戶應用程式中的租戶 ID),一種常見方法是先對分割槽鍵進行雜湊,然後將其對映到分片。
一個好的雜湊函式接受傾斜的資料並使其均勻分佈。假設你有一個 32 位雜湊函式,它接受一個字串。每當你給它一個新字串時,它返回一個介於 0 和 2³² − 1 之間的看似隨機的數字。即使輸入字串非常相似,它們的雜湊值也會均勻分佈在該數字範圍內(但相同的輸入總是產生相同的輸出)。
出於分片目的,雜湊函式不需要是密碼學強度的:例如,MongoDB 使用 MD5,而 Cassandra 和 ScyllaDB 使用 Murmur3。許多程式語言都內建了簡單的雜湊函式(因為它們用於雜湊表),但它們可能不適合分片:例如,在 Java 的 Object.hashCode() 和 Ruby 的 Object#hash 中,相同的鍵在不同的程序中可能有不同的雜湊值,使它們不適合分片 16。
雜湊取模節點數
一旦你對鍵進行了雜湊,如何選擇將其儲存在哪個分片中?也許你的第一個想法是取雜湊值 模 系統中的節點數(在許多程式語言中使用 % 運算子)。例如,hash(key) % 10 將返回 0 到 9 之間的數字(如果我們將雜湊寫為十進位制數,hash % 10 將是最後一位數字)。如果我們有 10 個節點,編號從 0 到 9,這似乎是將每個鍵分配給節點的簡單方法。
mod N 方法的問題是,如果節點數 N 發生變化,大多數鍵必須從一個節點移動到另一個節點。圖 7-3 顯示了當你有三個節點並新增第四個節點時會發生什麼。在再平衡之前,節點 0 儲存雜湊值為 0、3、6、9 等的鍵。新增第四個節點後,雜湊值為 3 的鍵已移動到節點 3,雜湊值為 6 的鍵已移動到節點 2,雜湊值為 9 的鍵已移動到節點 1,依此類推。
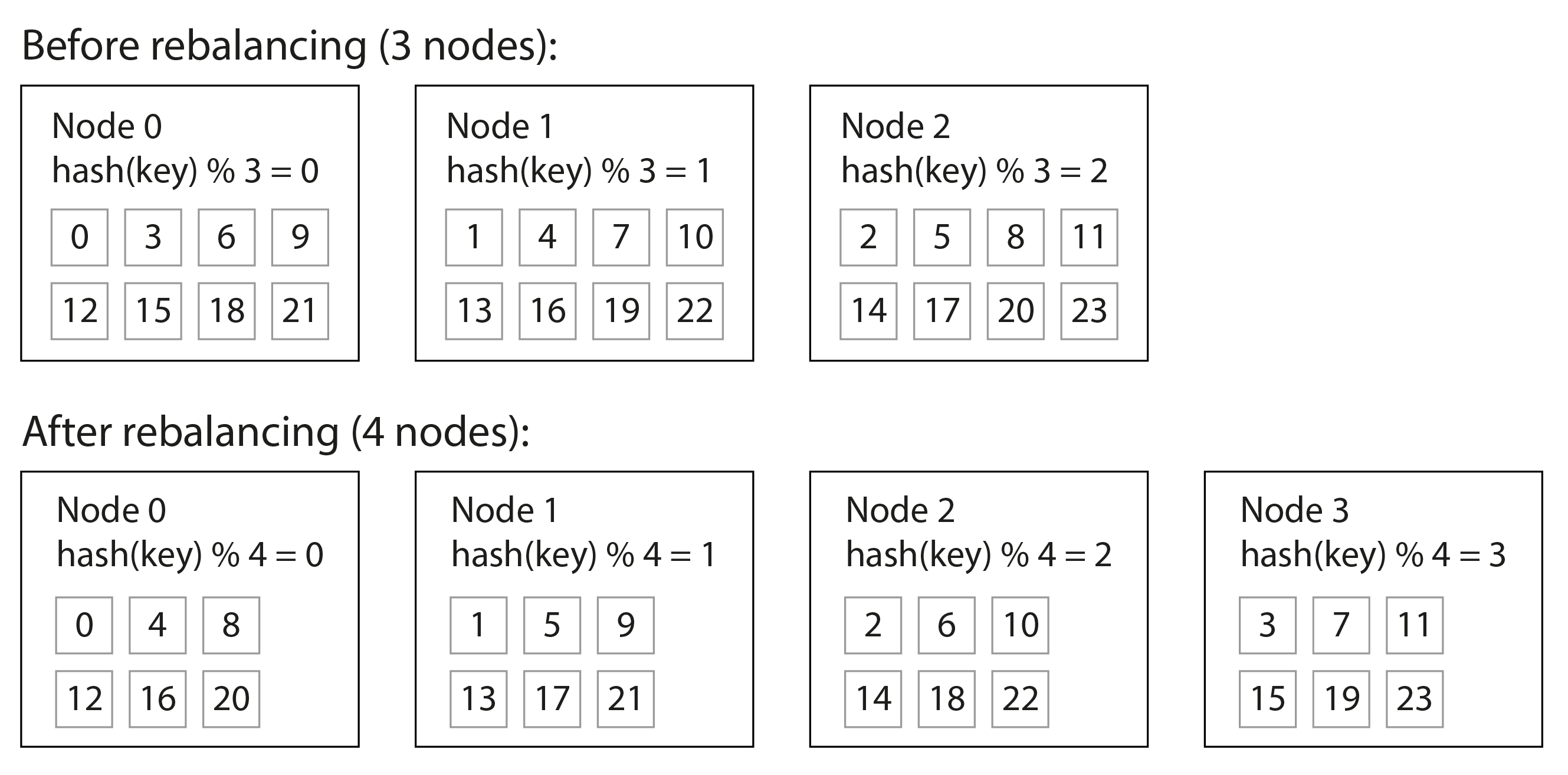
mod N 函式易於計算,但它導致非常低效的再平衡,因為存在大量不必要的記錄從一個節點移動到另一個節點。我們需要一種不會移動超過必要資料的方法。
固定數量的分片
一個簡單但廣泛使用的解決方案是建立比節點多得多的分片,併為每個節點分配多個分片。例如,在 10 個節點的叢集上執行的資料庫可能從一開始就被分成 1,000 個分片,以便每個節點分配 100 個分片。然後將鍵儲存在分片號 hash(key) % 1,000 中,系統單獨跟蹤哪個分片儲存在哪個節點上。
現在,如果向叢集新增一個節點,系統可以從現有節點重新分配一些分片到新節點,直到它們再次公平分佈。這個過程在 圖 7-4 中說明。如果從叢集中刪除節點,則反向發生相同的事情。
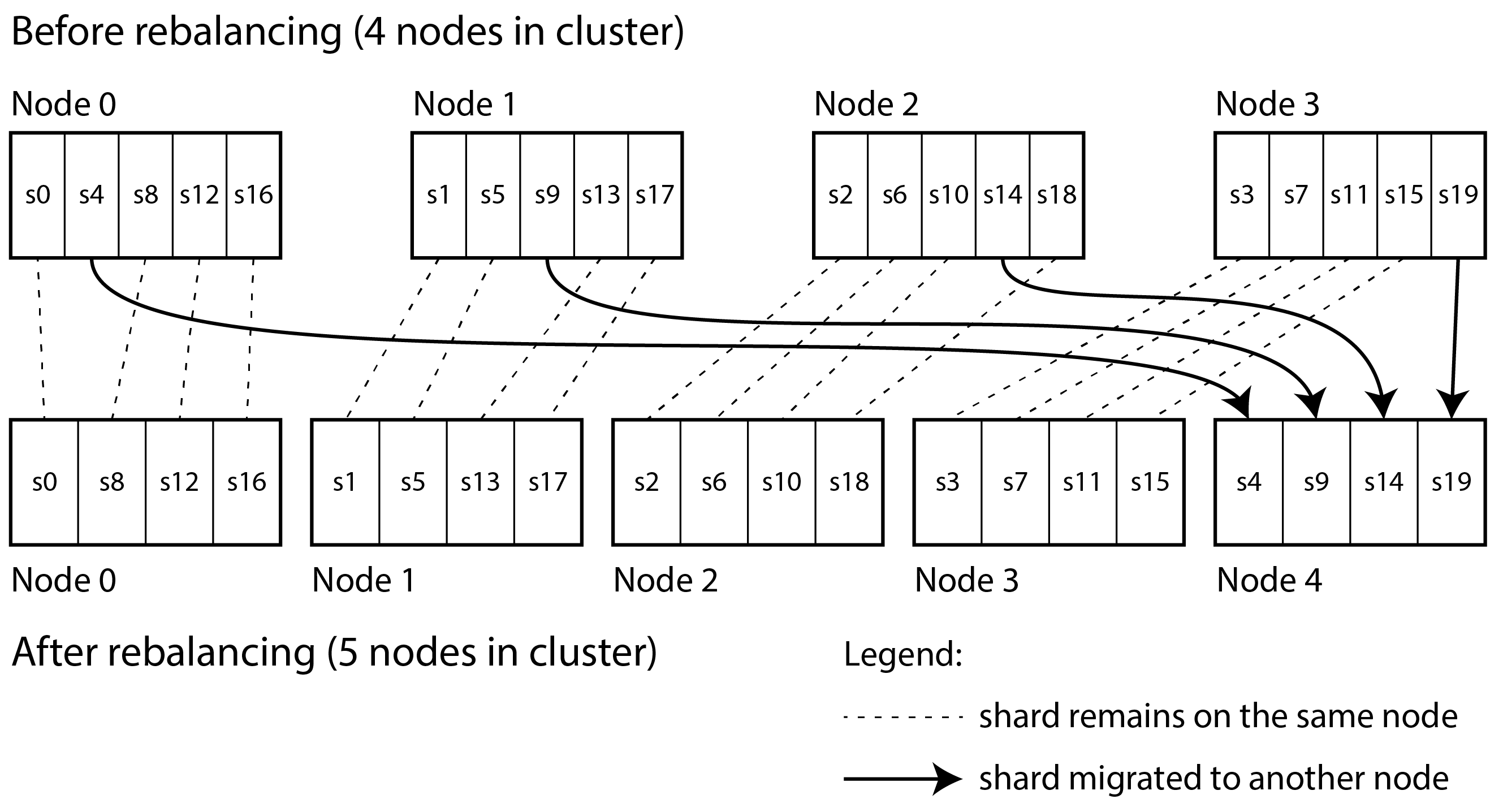
在這個模型中,只有整個分片在節點之間移動,這比分割分片更便宜。分片的數量不會改變,也不會改變鍵到分片的分配。唯一改變的是分片到節點的分配。這種分配的變化不是立即的——透過網路傳輸大量資料需要一些時間——因此在傳輸進行時,舊的分片分配用於任何發生的讀寫。
選擇分片數量為可被許多因子整除的數字是很常見的,這樣資料集可以在各種不同數量的節點之間均勻分割——例如,不要求節點數必須是 2 的冪 4。你甚至可以考慮叢集中不匹配的硬體:透過為更強大的節點分配更多分片,你可以讓這些節點承擔更大份額的負載。
這種分片方法被 Citus(PostgreSQL 的分片層)、Riak、Elasticsearch 和 Couchbase 等使用。只要你對首次建立資料庫時需要多少分片有很好的估計,它就很有效。然後你可以輕鬆新增或刪除節點,但受限於你不能擁有比分片更多的節點。
如果你發現最初配置的分片數量是錯誤的——例如,如果你已經達到需要比分片更多節點的規模——那麼需要進行昂貴的重新分片操作。它需要分割每個分片並將其寫入新檔案,在此過程中使用大量額外的磁碟空間。一些系統不允許在併發寫入資料庫時進行重新分片,這使得在沒有停機時間的情況下更改分片數量變得困難。
如果資料集的總大小高度可變(例如,如果它開始很小但可能隨時間增長得更大),選擇正確的分片數量是困難的。由於每個分片包含總資料的固定部分,每個分片的大小與叢集中的總資料量成比例增長。如果分片非常大,再平衡和從節點故障恢復會變得昂貴。但如果分片太小,它們會產生太多開銷。當分片大小"恰到好處"時可以實現最佳效能,既不太大也不太小,如果分片數量固定但資料集大小變化,這可能很難實現。
按雜湊範圍分片
如果無法提前預測所需的分片數量,最好使用一種方案,其中分片數量可以輕鬆適應工作負載。前面提到的鍵範圍分片方案具有這個屬性,但當有大量對相鄰鍵的寫入時,它有熱點的風險。一種解決方案是將鍵範圍分片與雜湊函式結合,使每個分片包含 雜湊值 的範圍而不是 鍵 的範圍。
圖 7-5 顯示了使用 16 位雜湊函式的示例,該函式返回 0 到 65,535 = 2¹⁶ − 1 之間的數字(實際上,雜湊通常是 32 位或更多)。即使輸入鍵非常相似(例如,連續的時間戳),它們的雜湊值也會在該範圍內均勻分佈。然後我們可以為每個分片分配一個雜湊值範圍:例如,值 0 到 16,383 分配給分片 0,值 16,384 到 32,767 分配給分片 1,依此類推。
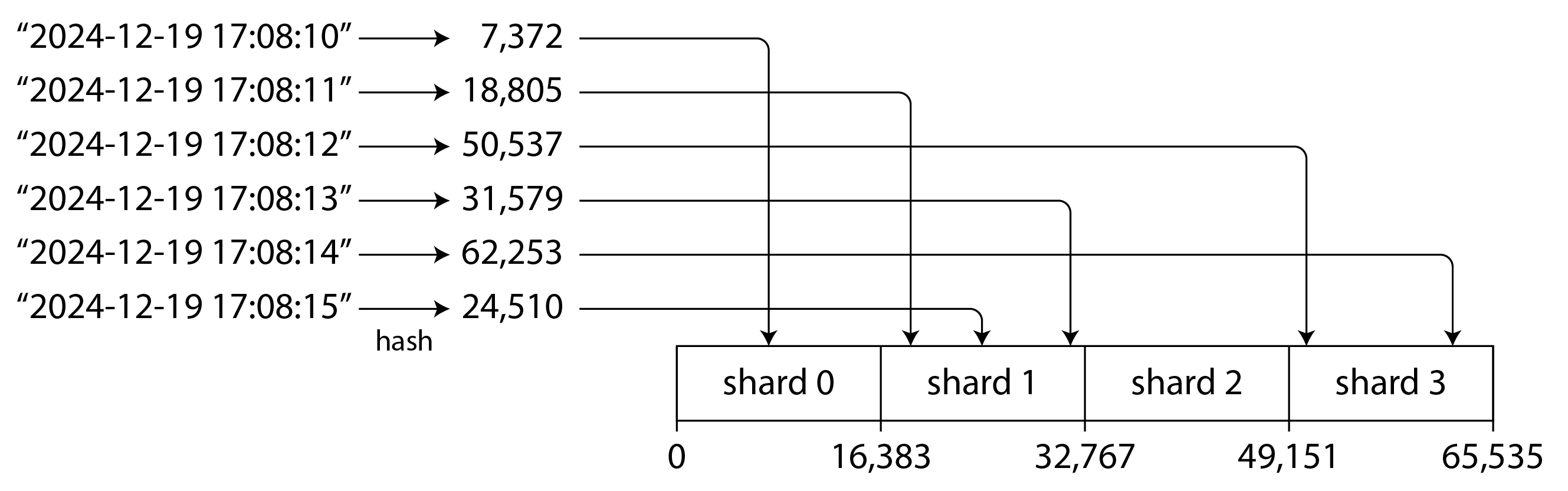
與鍵範圍分片一樣,雜湊範圍分片中的分片在變得太大或負載太重時可以被分割。這仍然是一個昂貴的操作,但它可以根據需要發生,因此分片數量適應資料量而不是預先固定。
與鍵範圍分片相比的缺點是,對分割槽鍵的範圍查詢效率不高,因為範圍內的鍵現在分散在所有分片中。但是,如果鍵由兩列或更多列組成,並且分割槽鍵只是這些列中的第一列,你仍然可以對第二列和後續列執行高效的範圍查詢:只要範圍查詢中的所有記錄具有相同的分割槽鍵,它們就會在同一個分片中。
資料倉庫中的分割槽和範圍查詢
資料倉庫如 BigQuery、Snowflake 和 Delta Lake 支援類似的索引方法,儘管術語不同。例如,在 BigQuery 中,分割槽鍵決定記錄駐留在哪個分割槽中,而"叢集列"決定記錄在分割槽內如何排序。Snowflake 自動將記錄分配給"微分割槽",但允許使用者為表定義叢集鍵。Delta Lake 支援手動和自動分割槽分配,並支援叢集鍵。聚集資料不僅可以提高範圍掃描效能,還可以提高壓縮和過濾效能。
雜湊範圍分片被 YugabyteDB 和 DynamoDB 使用 17,並且是 MongoDB 中的一個選項。Cassandra 和 ScyllaDB 使用這種方法的一個變體,如 圖 7-6 所示:雜湊值空間被分割成與節點數成比例的範圍數(圖 7-6 中每個節點 3 個範圍,但實際數字在 Cassandra 中預設為每個節點 8 個,在 ScyllaDB 中為每個節點 256 個),這些範圍之間有隨機邊界。這意味著某些範圍比其他範圍大,但透過每個節點有多個範圍,這些不平衡傾向於平均化 15 18。
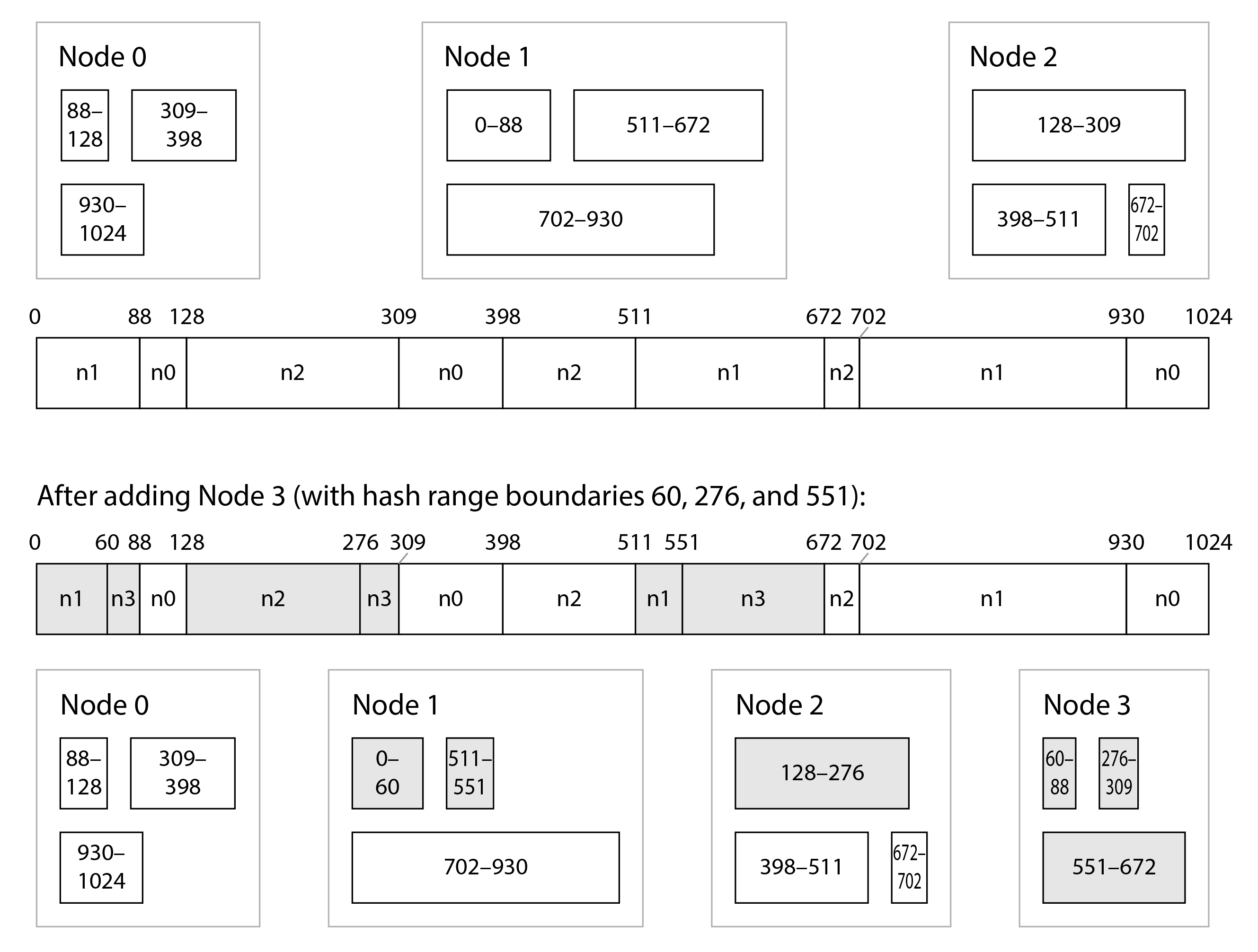
當新增或刪除節點時,會新增和刪除範圍邊界,並相應地分割或合併分片 19。在 圖 7-6 的示例中,當新增節點 3 時,節點 1 將其兩個範圍的部分轉移到節點 3,節點 2 將其一個範圍的部分轉移到節點 3。這樣做的效果是給新節點一個大致公平的資料集份額,而不會在節點之間傳輸超過必要的資料。
一致性雜湊
一致性雜湊 演算法是一種雜湊函式,它以滿足兩個屬性的方式將鍵對映到指定數量的分片:
- 對映到每個分片的鍵數大致相等,並且
- 當分片數量變化時,儘可能少的鍵從一個分片移動到另一個分片。
注意這裡的 一致性 與副本一致性(見 第 6 章)或 ACID 一致性(見 第 8 章)無關,而是描述了鍵儘可能保持在同一個分片中的傾向。
Cassandra 和 ScyllaDB 使用的分片演算法類似於一致性雜湊的原始定義 20,但也提出了其他幾種一致性雜湊演算法 21,如 最高隨機權重,也稱為 會合雜湊 22,以及 跳躍一致性雜湊 23。使用 Cassandra 的演算法,如果新增一個節點,少量現有分片會被分割成子範圍;另一方面,使用會合和跳躍一致性雜湊,新節點被分配之前分散在所有其他節點中的單個鍵。哪種更可取取決於應用程式。
傾斜的工作負載與緩解熱點
一致性雜湊確保鍵在節點間均勻分佈,但這並不意味著實際負載是均勻分佈的。如果工作負載高度傾斜——即某些分割槽鍵下的資料量遠大於其他鍵,或者對某些鍵的請求率遠高於其他鍵——你仍然可能最終導致某些伺服器過載,而其他伺服器幾乎處於空閒狀態。
例如,在社交媒體網站上,擁有數百萬粉絲的名人使用者在做某事時可能會引起活動風暴 24。這個事件可能導致對同一個鍵的大量讀寫(其中分割槽鍵可能是名人的使用者 ID,或者人們正在評論的動作的 ID)。
在這種情況下,需要更靈活的分片策略 25 26。基於鍵範圍(或雜湊範圍)定義分片的系統使得可以將單個熱鍵放在自己的分片中,甚至可能為其分配專用機器 27。
也可以在應用程式級別補償傾斜。例如,如果已知一個鍵非常熱,一個簡單的技術是在鍵的開頭或結尾新增一個隨機數。僅僅一個兩位數的十進位制隨機數就會將對該鍵的寫入均勻分佈在 100 個不同的鍵上,允許這些鍵分佈到不同的分片。
然而,將寫入分散到不同的鍵之後,任何讀取現在都必須做額外的工作,因為它們必須從所有 100 個鍵讀取資料並將其組合。對熱鍵每個分片的讀取量沒有減少;只有寫入負載被分割。這種技術還需要額外的記賬:只對少數熱鍵附加隨機數是有意義的;對於寫入吞吐量低的絕大多數鍵,這將是不必要的開銷。因此,你還需要某種方法來跟蹤哪些鍵正在被分割,以及將常規鍵轉換為特殊管理的熱鍵的過程。
問題因負載隨時間變化而進一步複雜化:例如,一個已經病毒式傳播的特定社交媒體帖子可能會在幾天內經歷高負載,但之後可能會再次平靜下來。此外,某些鍵可能對寫入很熱,而其他鍵對讀取很熱,需要不同的策略來處理它們。
一些系統(特別是為大規模設計的雲服務)有自動處理熱分片的方法;例如,Amazon 稱之為 熱管理 28 或 自適應容量 17。這些系統如何工作的細節超出了本書的範圍。
運維:自動/手動再均衡
關於再平衡有一個我們已經忽略的重要問題:分片的分割和再平衡是自動發生還是手動發生?
一些系統自動決定何時分割分片以及何時將它們從一個節點移動到另一個節點,無需任何人工互動,而其他系統則讓分片由管理員明確配置。還有一個中間地帶:例如,Couchbase 和 Riak 自動生成建議的分片分配,但需要管理員提交才能生效。
完全自動的再平衡可能很方便,因為正常維護的操作工作較少,這樣的系統甚至可以自動擴充套件以適應工作負載的變化。雲資料庫如 DynamoDB 被宣傳為能夠在幾分鐘內自動新增和刪除分片以適應負載的大幅增加或減少 17 29。
然而,自動分片管理也可能是不可預測的。再平衡是一項昂貴的操作,因為它需要重新路由請求並將大量資料從一個節點移動到另一個節點。如果操作不當,這個過程可能會使網路或節點過載,並可能損害其他請求的效能。系統必須在再平衡進行時繼續處理寫入;如果系統接近其最大寫入吞吐量,分片分割過程甚至可能無法跟上傳入寫入的速率 29。
這種自動化與自動故障檢測結合可能很危險。例如,假設一個節點過載並暫時響應請求緩慢。其他節點得出結論,過載的節點已死,並自動重新平衡叢集以將負載從它移開。這會對其他節點和網路施加額外負載,使情況變得更糟。存在導致級聯故障的風險,其中其他節點變得過載並也被錯誤地懷疑已關閉。
出於這個原因,在再平衡過程中有人參與可能是件好事。它比完全自動的過程慢,但它可以幫助防止操作意外。
請求路由
我們已經討論了如何將資料集分片到多個節點上,以及如何在新增或刪除節點時重新平衡這些分片。現在讓我們繼續討論這個問題:如果你想讀取或寫入特定的鍵,你如何知道需要連線到哪個節點——即哪個 IP 地址和埠號?
我們稱這個問題為 請求路由,它與 服務發現 非常相似,我們之前在 “負載均衡器、服務發現和服務網格” 中討論過。兩者之間最大的區別是,對於執行應用程式程式碼的服務,每個例項通常是無狀態的,負載均衡器可以將請求傳送到任何例項。對於分片資料庫,對鍵的請求只能由包含該鍵的分片的副本節點處理。
這意味著請求路由必須知道鍵到分片的分配,以及分片到節點的分配。在高層次上,這個問題有幾種不同的方法(在 圖 7-7 中說明):
- 允許客戶端連線任何節點(例如,透過迴圈負載均衡器)。如果該節點恰好擁有請求適用的分片,它可以直接處理請求;否則,它將請求轉發到適當的節點,接收回復,並將回覆傳遞給客戶端。
- 首先將客戶端的所有請求傳送到路由層,該層確定應該處理每個請求的節點並相應地轉發它。這個路由層本身不處理任何請求;它只充當分片感知的負載均衡器。
- 要求客戶端知道分片和分片到節點的分配。在這種情況下,客戶端可以直接連線到適當的節點,而無需任何中介。
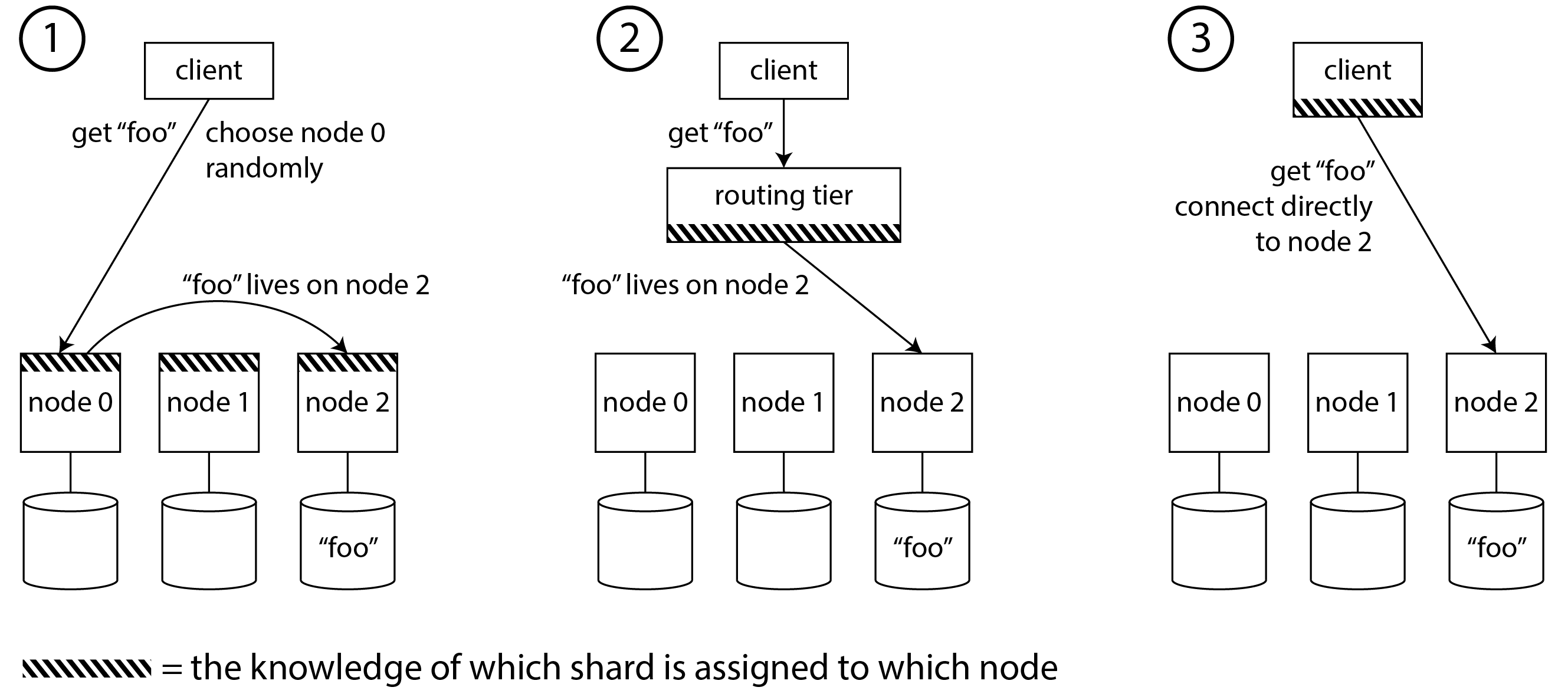
在所有情況下,都有一些關鍵問題:
- 誰決定哪個分片應該存在於哪個節點上?最簡單的是有一個單一的協調器做出該決定,但在這種情況下,如果執行協調器的節點出現故障,如何使其容錯?如果協調器角色可以故障轉移到另一個節點,如何防止腦裂情況(見 “處理節點中斷”),其中兩個不同的協調器做出相互矛盾的分片分配?
- 執行路由的元件(可能是節點之一、路由層或客戶端)如何瞭解分片到節點分配的變化?
- 當分片從一個節點移動到另一個節點時,有一個切換期,在此期間新節點已接管,但對舊節點的請求可能仍在傳輸中。如何處理這些?
許多分散式資料系統依賴於單獨的協調服務(如 ZooKeeper 或 etcd)來跟蹤分片分配,如 圖 7-8 所示。它們使用共識演算法(見 第 10 章)來提供容錯和防止腦裂。每個節點在 ZooKeeper 中註冊自己,ZooKeeper 維護分片到節點的權威對映。其他參與者,如路由層或分片感知客戶端,可以在 ZooKeeper 中訂閱此資訊。每當分片所有權發生變化,或者新增或刪除節點時,ZooKeeper 都會通知路由層,以便它可以保持其路由資訊最新。
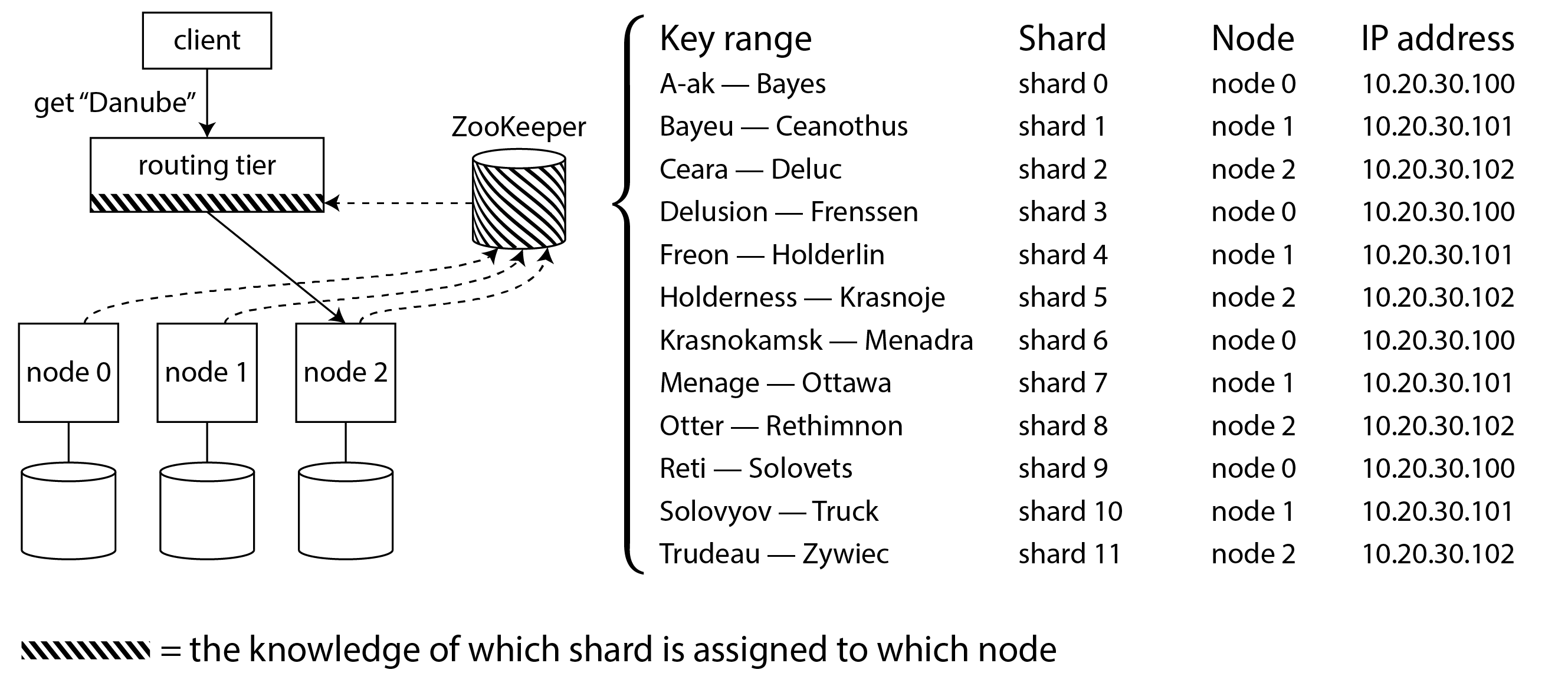
例如,HBase 和 SolrCloud 使用 ZooKeeper 管理分片分配,Kubernetes 使用 etcd 跟蹤哪個服務例項在哪裡執行。MongoDB 有類似的架構,但它依賴於自己的 配置伺服器 實現和 mongos 守護程序作為路由層。Kafka、YugabyteDB 和 TiDB 使用內建的 Raft 共識協議實現來執行此協調功能。
Cassandra、ScyllaDB 和 Riak 採用不同的方法:它們在節點之間使用 流言協議 來傳播叢集狀態的任何變化。這提供了比共識協議弱得多的一致性;可能會出現腦裂,其中叢集的不同部分對同一分片有不同的節點分配。無主資料庫可以容忍這一點,因為它們通常提供弱一致性保證(見 “仲裁一致性的限制”)。
當使用路由層或向隨機節點發送請求時,客戶端仍然需要找到要連線的 IP 地址。這些不像分片到節點的分配那樣快速變化,因此通常使用 DNS 就足夠了。
這個關於請求路由的討論集中在查詢單個鍵的分片,這對於分片 OLTP 資料庫最相關。分析資料庫通常也使用分片,但它們通常有非常不同型別的查詢執行:查詢通常需要並行聚合和連線來自許多不同分片的資料,而不是在單個分片中執行。我們將在 [連結待定] 中討論這種並行查詢執行的技術。
分片與二級索引
到目前為止,我們討論的分片方案依賴於客戶端知道它想要訪問的任何記錄的分割槽鍵。這在鍵值資料模型中最容易做到,其中分割槽鍵是主鍵的第一部分(或整個主鍵),因此我們可以使用分割槽鍵來確定分片,從而將讀寫路由到負責該鍵的節點。
如果涉及二級索引,情況會變得更加複雜(另見 “多列和二級索引”)。二級索引通常不唯一地標識記錄,而是一種搜尋特定值出現的方法:查詢使用者 123 的所有操作、查詢包含單詞 hogwash 的所有文章、查詢顏色為 red 的所有汽車等。
鍵值儲存通常沒有二級索引,但它們是關係資料庫的基礎,在文件資料庫中也很常見,它們是 Solr 和 Elasticsearch 等搜尋引擎的 存在理由。二級索引的問題是它們不能整齊地對映到分片。有兩種主要方法來使用二級索引對資料庫進行分片:本地索引和全域性索引。
本地二級索引
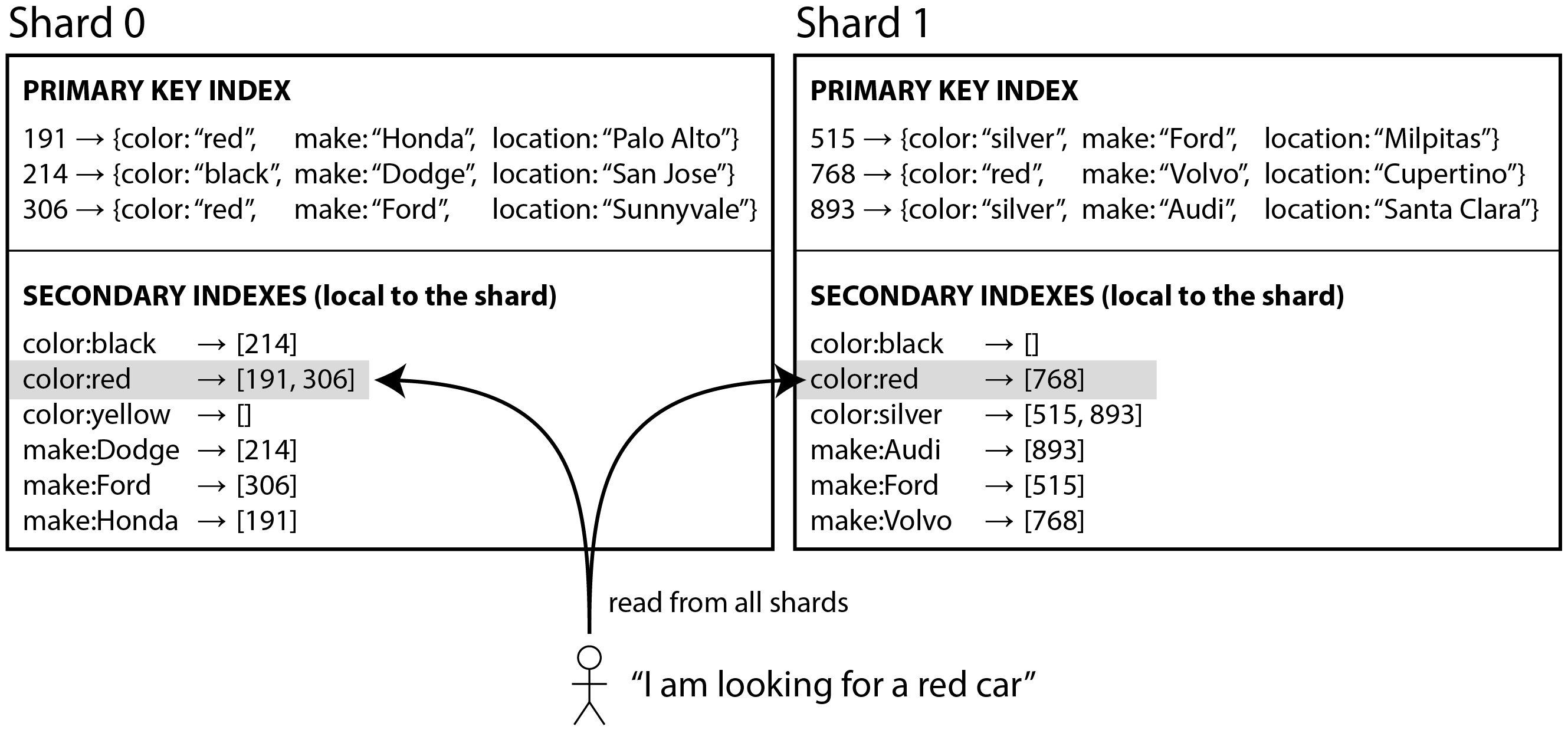
例如,假設你正在運營一個出售二手車的網站(如 圖 7-9 所示)。每個列表都有一個唯一的 ID——稱之為文件 ID——你使用該 ID 作為分割槽鍵對資料庫進行分片(例如,ID 0 到 499 在分片 0 中,ID 500 到 999 在分片 1 中,等等)。
如果你想讓使用者搜尋汽車,允許他們按顏色和製造商過濾,你需要在 color 和 make 上建立二級索引(在文件資料庫中這些是欄位;在關係資料庫中這些是列)。如果你已宣告索引,資料庫可以自動執行索引。例如,每當將紅色汽車新增到資料庫時,資料庫分片會自動將其 ID 新增到索引條目 color:red 的文件 ID 列表中。如 第 4 章 中所討論的,該 ID 列表也稱為 釋出列表。
警告
如果你的資料庫只支援鍵值模型,你可能會嘗試透過在應用程式程式碼中建立從值到文件 ID 的對映來自己實現二級索引。如果你走這條路,你需要格外小心,確保你的索引與底層資料保持一致。競態條件和間歇性寫入失敗(其中某些更改已儲存但其他更改未儲存)很容易導致資料不同步——見 “多物件事務的需求”。
在這種索引方法中,每個分片是完全獨立的:每個分片維護自己的二級索引,僅覆蓋該分片中的文件。它不關心儲存在其他分片中的資料。每當你需要寫入資料庫——新增、刪除或更新記錄——你只需要處理包含你正在寫入的文件 ID 的分片。出於這個原因,這種型別的二級索引被稱為 本地索引。在資訊檢索上下文中,它也被稱為 文件分割槽索引 30。
當從本地二級索引讀取時,如果你已經知道你正在查詢的記錄的分割槽鍵,你可以只在適當的分片上執行搜尋。此外,如果你只想要 一些 結果,而不需要全部,你可以將請求傳送到任何分片。
但是,如果你想要所有結果並且事先不知道它們的分割槽鍵,你需要將查詢傳送到所有分片,並組合你收到的結果,因為匹配的記錄可能分散在所有分片中。在 圖 7-9 中,紅色汽車出現在分片 0 和分片 1 中。
這種查詢分片資料庫的方法有時稱為 分散/聚集,它可能使二級索引上的讀取查詢相當昂貴。即使並行查詢分片,分散/聚集也容易導致尾部延遲放大(見 “響應時間指標的使用”)。它還限制了應用程式的可伸縮性:新增更多分片讓你儲存更多資料,但如果每個分片無論如何都必須處理每個查詢,它不會增加你的查詢吞吐量。
儘管如此,本地二級索引被廣泛使用 31:例如,MongoDB、Riak、Cassandra 32、Elasticsearch 33、SolrCloud 和 VoltDB 34 都使用本地二級索引。
全域性二級索引
我們可以構建一個覆蓋所有分片資料的 全域性索引,而不是每個分片有自己的本地二級索引。但是,我們不能只將該索引儲存在一個節點上,因為它可能會成為瓶頸並違背分片的目的。全域性索引也必須進行分片,但它可以以不同於主鍵索引的方式進行分片。
圖 7-10 說明了這可能是什麼樣子:來自所有分片的紅色汽車的 ID 出現在索引的 color:red 下,但索引是分片的,以便以字母 a 到 r 開頭的顏色出現在分片 0 中,以 s 到 z 開頭的顏色出現在分片 1 中。汽車製造商的索引也類似地分割槽(分片邊界在 f 和 h 之間)。
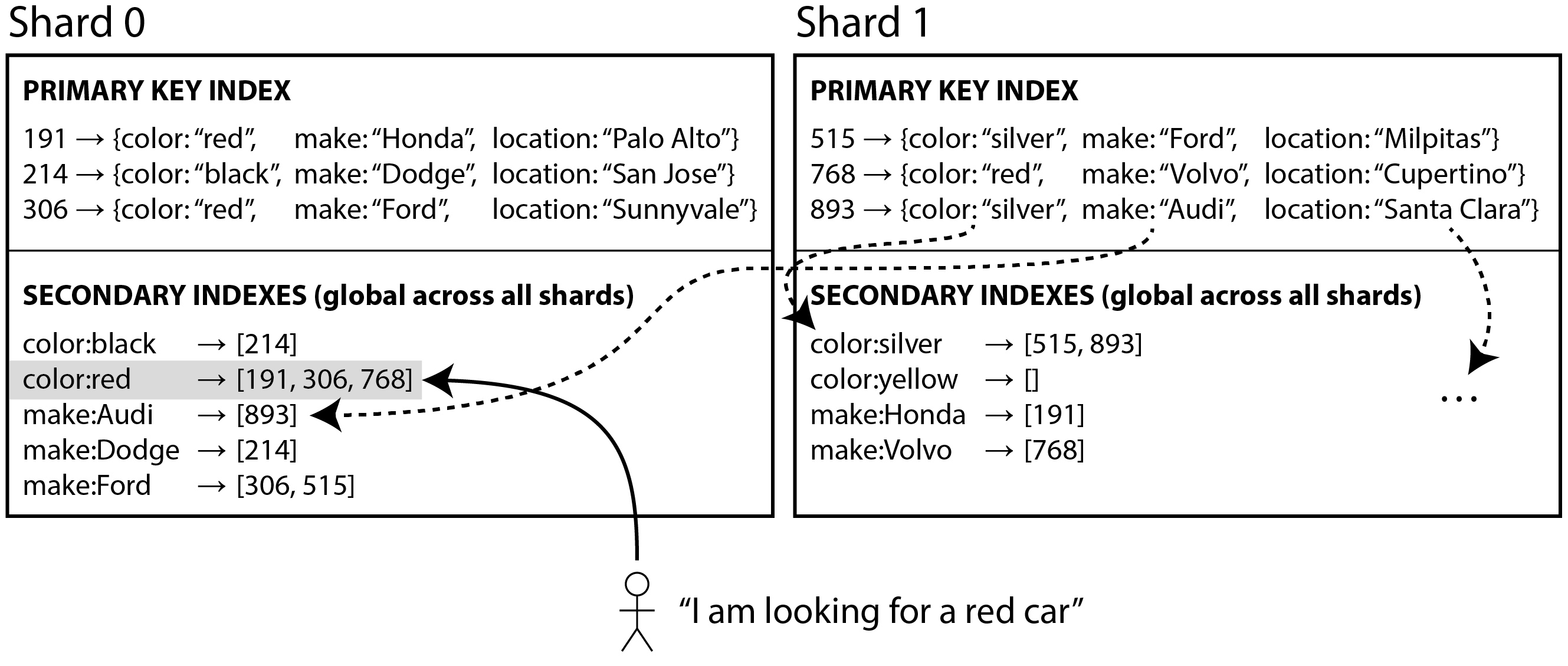
這種索引也稱為 基於詞項分割槽 30:回憶一下 “全文檢索”,在全文檢索中,詞項 是你可以搜尋的文字中的關鍵字。這裡我們將其推廣為指二級索引中你可以搜尋的任何值。
全域性索引使用詞項作為分割槽鍵,因此當你查詢特定詞項或值時,你可以找出需要查詢哪個分片。和以前一樣,分片可以包含連續的詞項範圍(如 圖 7-10),或者你可以基於詞項的雜湊將詞項分配給分片。
全域性索引的優點是具有單個條件的查詢(如 color = red)只需要從單個分片讀取以獲取釋出列表。但是,如果你想獲取記錄而不僅僅是 ID,你仍然必須從負責這些 ID 的所有分片中讀取。
如果你有多個搜尋條件或詞項(例如,搜尋某種顏色和某種製造商的汽車,或搜尋同一文字中出現的多個單詞),很可能這些詞項將被分配給不同的分片。要計算兩個條件的邏輯 AND,系統需要找到兩個釋出列表中都出現的所有 ID。如果釋出列表很短,這沒問題,但如果它們很長,透過網路傳送它們來計算它們的交集可能會很慢 30。
全域性二級索引的另一個挑戰是寫入比本地索引更複雜,因為寫入單個記錄可能會影響索引的多個分片(文件中的每個詞項可能在不同的分片或不同的節點上)。這使得二級索引與底層資料保持同步更加困難。一種選擇是使用分散式事務來原子地更新儲存主記錄的分片及其二級索引(見 第 8 章)。
全域性二級索引被 CockroachDB、TiDB 和 YugabyteDB 使用;DynamoDB 支援本地和全域性二級索引。在 DynamoDB 的情況下,寫入非同步反映在全域性索引中,因此從全域性索引讀取可能是陳舊的(類似於複製延遲,如 “複製延遲的問題”)。儘管如此,如果讀取吞吐量高於寫入吞吐量,並且釋出列表不太長,全域性索引是有用的。
總結
在本章中,我們探討了將大型資料集分片為更小子集的不同方法。當你有如此多的資料以至於在單臺機器上儲存和處理它不再可行時,分片是必要的。
分片的目標是在多臺機器上均勻分佈資料和查詢負載,避免熱點(負載不成比例高的節點)。這需要選擇適合你的資料的分片方案,並在節點新增到叢集或從叢集中刪除時重新平衡分片。
我們討論了兩種主要的分片方法:
鍵範圍分片,其中鍵是有序的,分片擁有從某個最小值到某個最大值的所有鍵。排序的優點是可以進行高效的範圍查詢,但如果應用程式經常訪問排序順序中彼此接近的鍵,則存在熱點風險。
在這種方法中,當分片變得太大時,通常透過將範圍分成兩個子範圍來動態重新平衡分片。
雜湊分片,其中對每個鍵應用雜湊函式,分片擁有一個雜湊值範圍(或者可以使用另一種一致性雜湊演算法將雜湊對映到分片)。這種方法破壞了鍵的順序,使範圍查詢效率低下,但可能更均勻地分佈負載。
當按雜湊分片時,通常預先建立固定數量的分片,為每個節點分配多個分片,並在新增或刪除節點時將整個分片從一個節點移動到另一個節點。像鍵範圍一樣分割分片也是可能的。
通常使用鍵的第一部分作為分割槽鍵(即,識別分片),並在該分片內按鍵的其餘部分對記錄進行排序。這樣,你仍然可以在具有相同分割槽鍵的記錄之間進行高效的範圍查詢。
我們還討論了分片和二級索引之間的互動。二級索引也需要進行分片,有兩種方法:
- 本地二級索引,其中二級索引與主鍵和值儲存在同一個分片中。這意味著寫入時只需要更新一個分片,但二級索引的查詢需要從所有分片讀取。
- 全域性二級索引,它們基於索引值單獨分片。二級索引中的條目可能引用來自主鍵所有分片的記錄。寫入記錄時,可能需要更新多個二級索引分片;但是,可以從單個分片提供釋出列表的讀取(獲取實際記錄仍需要從多個分片讀取)。
最後,我們討論了將查詢路由到適當分片的技術,以及協調服務通常用於跟蹤分片到節點的分配的方式。
按設計,每個分片主要獨立執行——這就是允許分片資料庫擴充套件到多臺機器的原因。但是,需要寫入多個分片的操作可能會有問題:例如,如果對一個分片的寫入成功,但對另一個分片的寫入失敗,會發生什麼?我們將在以下章節中解決該問題。
References
Claire Giordano. Understanding partitioning and sharding in Postgres and Citus. citusdata.com, August 2023. Archived at perma.cc/8BTK-8959 ↩︎
Brandur Leach. Partitioning in Postgres, 2022 edition. brandur.org, October 2022. Archived at perma.cc/Z5LE-6AKX ↩︎
Raph Koster. Database “sharding” came from UO? raphkoster.com, January 2009. Archived at perma.cc/4N9U-5KYF ↩︎
Garrett Fidalgo. Herding elephants: Lessons learned from sharding Postgres at Notion. notion.com, October 2021. Archived at perma.cc/5J5V-W2VX ↩︎ ↩︎
Ulrich Drepper. What Every Programmer Should Know About Memory. akkadia.org, November 2007. Archived at perma.cc/NU6Q-DRXZ ↩︎
Jingyu Zhou, Meng Xu, Alexander Shraer, Bala Namasivayam, Alex Miller, Evan Tschannen, Steve Atherton, Andrew J. Beamon, Rusty Sears, John Leach, Dave Rosenthal, Xin Dong, Will Wilson, Ben Collins, David Scherer, Alec Grieser, Young Liu, Alvin Moore, Bhaskar Muppana, Xiaoge Su, and Vishesh Yadav. FoundationDB: A Distributed Unbundled Transactional Key Value Store. At ACM International Conference on Management of Data (SIGMOD), June 2021. doi:10.1145/3448016.3457559 ↩︎ ↩︎
Marco Slot. Citus 12: Schema-based sharding for PostgreSQL. citusdata.com, July 2023. Archived at perma.cc/R874-EC9W ↩︎
Robisson Oliveira. Reducing the Scope of Impact with Cell-Based Architecture. AWS Well-Architected white paper, Amazon Web Services, September 2023. Archived at perma.cc/4KWW-47NR ↩︎
Gwen Shapira. Things DBs Don’t Do - But Should. thenile.dev, February 2023. Archived at perma.cc/C3J4-JSFW ↩︎
Malte Schwarzkopf, Eddie Kohler, M. Frans Kaashoek, and Robert Morris. Position: GDPR Compliance by Construction. At Towards Polystores that manage multiple Databases, Privacy, Security and/or Policy Issues for Heterogenous Data (Poly), August 2019. doi:10.1007/978-3-030-33752-0_3 ↩︎
Gwen Shapira. Introducing pg_karnak: Transactional schema migration across tenant databases. thenile.dev, November 2024. Archived at perma.cc/R5RD-8HR9 ↩︎
Arka Ganguli, Guido Iaquinti, Maggie Zhou, and Rafael Chacón. Scaling Datastores at Slack with Vitess. slack.engineering, December 2020. Archived at perma.cc/UW8F-ALJK ↩︎
Ikai Lan. App Engine Datastore Tip: Monotonically Increasing Values Are Bad. ikaisays.com, January 2011. Archived at perma.cc/BPX8-RPJB ↩︎
Enis Soztutar. Apache HBase Region Splitting and Merging. cloudera.com, February 2013. Archived at perma.cc/S9HS-2X2C ↩︎
Eric Evans. Rethinking Topology in Cassandra. At Cassandra Summit, June 2013. Archived at perma.cc/2DKM-F438 ↩︎ ↩︎
Martin Kleppmann. Java’s hashCode Is Not Safe for Distributed Systems. martin.kleppmann.com, June 2012. Archived at perma.cc/LK5U-VZSN ↩︎
Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, and Akshat Vig. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service. At USENIX Annual Technical Conference (ATC), July 2022. ↩︎ ↩︎ ↩︎
Brandon Williams. Virtual Nodes in Cassandra 1.2. datastax.com, December 2012. Archived at perma.cc/N385-EQXV ↩︎
Branimir Lambov. New Token Allocation Algorithm in Cassandra 3.0. datastax.com, January 2016. Archived at perma.cc/2BG7-LDWY ↩︎
David Karger, Eric Lehman, Tom Leighton, Rina Panigrahy, Matthew Levine, and Daniel Lewin. Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web. At 29th Annual ACM Symposium on Theory of Computing (STOC), May 1997. doi:10.1145/258533.258660 ↩︎
Damian Gryski. Consistent Hashing: Algorithmic Tradeoffs. dgryski.medium.com, April 2018. Archived at perma.cc/B2WF-TYQ8 ↩︎
David G. Thaler and Chinya V. Ravishankar. Using name-based mappings to increase hit rates. IEEE/ACM Transactions on Networking, volume 6, issue 1, pages 1–14, February 1998. doi:10.1109/90.663936 ↩︎
John Lamping and Eric Veach. A Fast, Minimal Memory, Consistent Hash Algorithm. arxiv.org, June 2014. ↩︎
Samuel Axon. 3% of Twitter’s Servers Dedicated to Justin Bieber. mashable.com, September 2010. Archived at perma.cc/F35N-CGVX ↩︎
Gerald Guo and Thawan Kooburat. Scaling services with Shard Manager. engineering.fb.com, August 2020. Archived at perma.cc/EFS3-XQYT ↩︎
Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Thawan Kooburat, Suryadeep Biswal, Jun Chen, Kun Huang, Yatpang Cheung, Yiding Zhou, Kaushik Veeraraghavan, Biren Damani, Pol Mauri Ruiz, Vikas Mehta, and Chunqiang Tang. Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications. 28th ACM SIGOPS Symposium on Operating Systems Principles (SOSP), pages 553–569, October 2021. doi:10.1145/3477132.3483546 ↩︎
Scott Lystig Fritchie. A Critique of Resizable Hash Tables: Riak Core & Random Slicing. infoq.com, August 2018. Archived at perma.cc/RPX7-7BLN ↩︎
Andy Warfield. Building and operating a pretty big storage system called S3. allthingsdistributed.com, July 2023. Archived at perma.cc/6S7P-GLM4 ↩︎
Rich Houlihan. DynamoDB adaptive capacity: smooth performance for chaotic workloads (DAT327). At AWS re:Invent, November 2017. ↩︎ ↩︎
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008. ISBN: 978-0-521-86571-5, available online at nlp.stanford.edu/IR-book ↩︎ ↩︎ ↩︎
Michael Busch, Krishna Gade, Brian Larson, Patrick Lok, Samuel Luckenbill, and Jimmy Lin. Earlybird: Real-Time Search at Twitter. At 28th IEEE International Conference on Data Engineering (ICDE), April 2012. doi:10.1109/ICDE.2012.149 ↩︎
Nadav Har’El. Indexing in Cassandra 3. github.com, April 2017. Archived at perma.cc/3ENV-8T9P ↩︎
Zachary Tong. Customizing Your Document Routing. elastic.co, June 2013. Archived at perma.cc/97VM-MREN ↩︎
Andrew Pavlo. H-Store Frequently Asked Questions. hstore.cs.brown.edu, October 2013. Archived at perma.cc/X3ZA-DW6Z ↩︎