2. 定義非功能性需求

網際網路做得如此之好,以至於大多數人都把它想象成像太平洋一樣的自然資源,而不是人造的東西。上一次出現這種規模且無差錯的技術是什麼時候?
艾倫・凱, 在接受 Dr Dobb’s Journal 採訪時(2012 年)
如果你正在構建一個應用程式,你將會被一系列需求所驅動。在你的需求列表中,最重要的可能是應用程式必須提供的功能:需要哪些介面和按鈕,以及每個操作應該做什麼,以實現軟體的目的。這些是你的 功能性需求。
此外,你可能還有一些 非功能性需求:例如,應用程式應該快速、可靠、安全、合規,並且易於維護。這些需求可能沒有明確寫下來,因為它們看起來有些顯而易見,但它們與應用程式的功能同樣重要:一個慢得讓人無法忍受或不可靠的應用程式還不如不存在。
許多非功能性需求,比如安全性,超出了本書的範圍。但我們將考慮一些非功能性需求,本章將幫助你為自己的系統闡明它們:
- 如何定義和衡量系統的 效能(參見 “描述效能”);
- 服務 可靠 意味著什麼——即即使出現問題也能繼續正確工作(參見 “可靠性與容錯”);
- 透過在系統負載增長時新增計算能力的有效方法,使系統具有 可伸縮性(參見 “可伸縮性”);以及
- 使系統長期更 易於維護(參見 “可維護性”)。
本章介紹的術語在後續章節中也很有用,當我們深入研究資料密集型系統的實現細節時。然而,抽象定義可能相當枯燥;為了使這些想法更具體,我們將從一個案例研究開始本章,研究社交網路服務可能如何工作,這將提供效能和可伸縮性的實際案例。
案例研究:社交網路首頁時間線
想象一下,你被賦予了實現一個類似 X(前身為 Twitter)風格的社交網路的任務,使用者可以釋出訊息並關注其他使用者。這將是對這種服務實際工作方式的巨大簡化 1 2 3,但它將有助於說明大規模系統中出現的一些問題。
假設使用者每天釋出 5 億條帖子,或平均每秒 5,700 條帖子。偶爾,速率可能飆升至每秒 150,000 條帖子 4。我們還假設平均每個使用者關注 200 人並有 200 個粉絲(儘管實際的範圍要大得多:大多數人只有少數粉絲,而少數名人如巴拉克・奧巴馬有超過 1 億粉絲)。
表示使用者、帖子與關注關係
假設我們將所有資料儲存在關係資料庫中,如 圖 2-1 所示。我們有一個使用者表、一個帖子表和一個關注關係表。
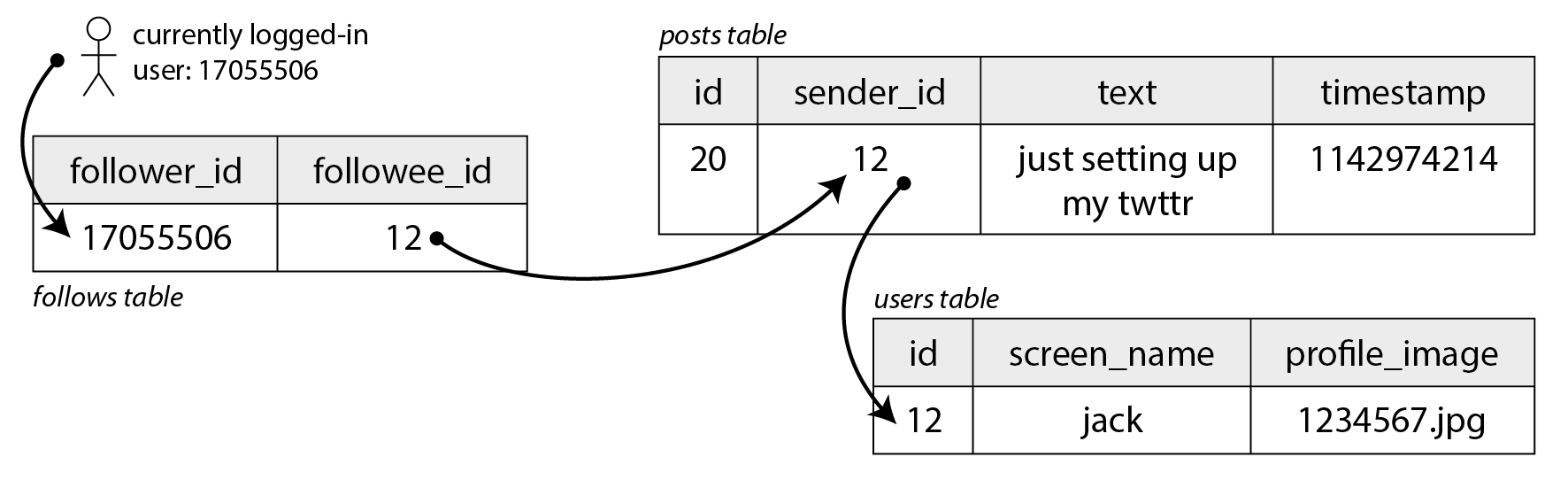
假設我們的社交網路必須支援的主要讀取操作是 首頁時間線,它顯示你關注的人最近釋出的帖子(為簡單起見,我們將忽略廣告、來自你未關注的人的推薦帖子和其他擴充套件)。我們可以編寫以下 SQL 查詢來獲取特定使用者的首頁時間線:
SELECT posts.*, users.* FROM posts
JOIN follows ON posts.sender_id = follows.followee_id
JOIN users ON posts.sender_id = users.id
WHERE follows.follower_id = current_user
ORDER BY posts.timestamp DESC
LIMIT 1000要執行此查詢,資料庫將使用 follows 表找到 current_user 關注的所有人,查詢這些使用者最近的帖子,並按時間戳排序以獲取被關注使用者的最新 1,000 條帖子。
帖子應該是及時的,所以假設在某人釋出帖子後,我們希望他們的粉絲能夠在 5 秒內看到它。一種方法是讓使用者的客戶端每 5 秒重複上述查詢(這稱為 輪詢)。如果我們假設有 1000 萬用戶同時線上登入,這意味著每秒執行 200 萬次查詢。即使增加輪詢間隔,這也是很大的負載。
此外,上述查詢相當昂貴:如果你關注 200 人,它需要獲取這 200 人中每個人的最近帖子列表,併合並這些列表。每秒 200 萬次時間線查詢意味著資料庫需要每秒查詢某個傳送者的最近帖子 4 億次——這是一個巨大的數字。這是平均情況。一些使用者關注數萬個賬戶;對他們來說,這個查詢執行起來非常昂貴,而且很難快速完成。
時間線的物化與更新
我們如何做得更好?首先,與其輪詢,不如伺服器主動向當前線上的任何粉絲推送新帖子。其次,我們應該預先計算上述查詢的結果,以便可以從快取中提供使用者的首頁時間線請求。
想象一下,我們為每個使用者儲存一個包含其首頁時間線的資料結構,即他們關注的人的最近帖子。每次使用者釋出帖子時,我們查詢他們的所有粉絲,並將該帖子插入到每個粉絲的首頁時間線中——就像向郵箱投遞訊息一樣。現在當用戶登入時,我們可以簡單地給他們這個預先計算的首頁時間線。此外,要接收時間線上任何新帖子的通知,使用者的客戶端只需訂閱新增到其首頁時間線的帖子流。
這種方法的缺點是,現在每次使用者釋出帖子時我們需要做更多的工作,因為首頁時間線是需要更新的派生資料。該過程如 圖 2-2 所示。當一個初始請求導致幾個下游請求被執行時,我們使用術語 扇出 來描述請求數量增加的因子。
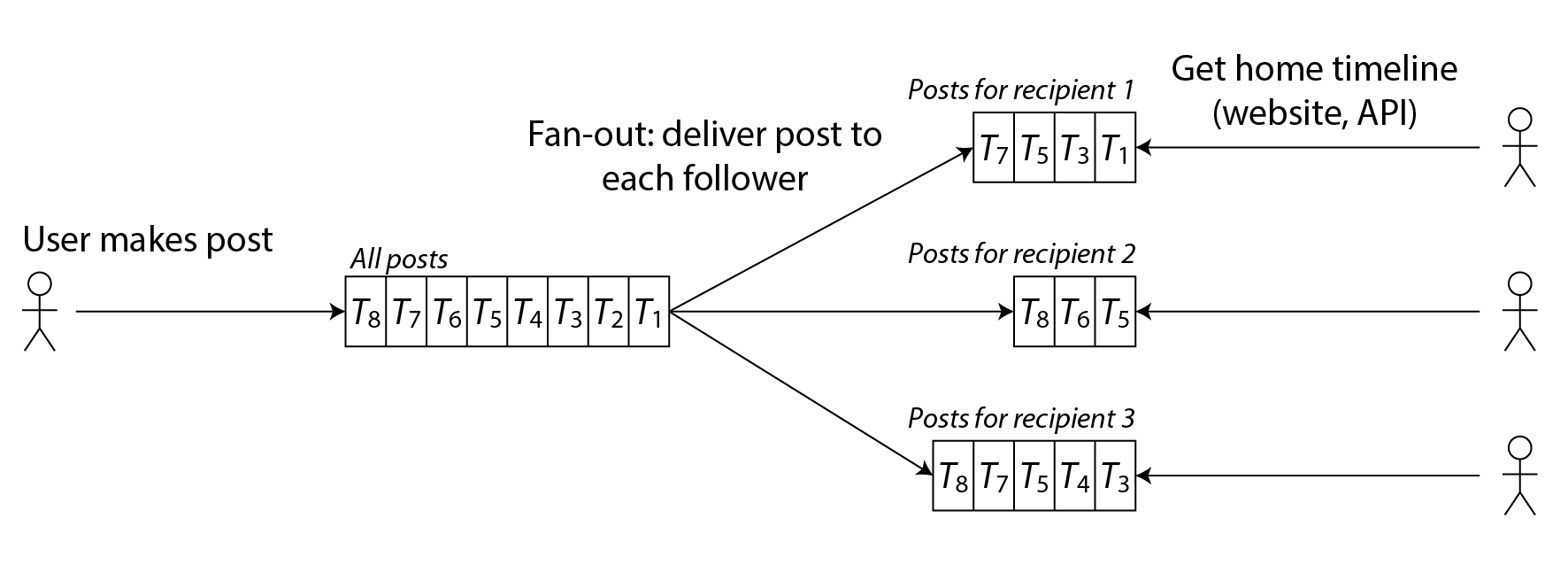
以每秒 5,700 條帖子的速率,如果平均帖子到達 200 個粉絲(即扇出因子為 200),我們將需要每秒執行超過 100 萬次首頁時間線寫入。這很多,但與我們本來需要的每秒 4 億次每個傳送者的帖子查詢相比,這仍然是一個顯著的節省。
如果由於某些特殊事件導致帖子速率激增,我們不必立即進行時間線交付——我們可以將它們排隊,並接受帖子在粉絲的時間線中顯示會暫時花費更長時間。即使在這種負載峰值期間,時間線仍然可以快速載入,因為我們只是從快取中提供它們。
這種預先計算和更新查詢結果的過程稱為 物化,時間線快取是 物化檢視 的一個例子(我們將在 [待補充連結] 中進一步討論這個概念)。物化檢視加速了讀取,但作為回報,我們必須在寫入時做更多的工作。對於大多數使用者來說,寫入成本是適度的,但社交網路還必須考慮一些極端情況:
- 如果使用者關注非常多的賬戶,並且這些賬戶釋出很多內容,該使用者的物化時間線將有很高的寫入率。然而,在這種情況下,使用者實際上不太可能閱讀其時間線中的所有帖子,因此可以簡單地丟棄其時間線的一些寫入,只向用戶顯示他們關注的賬戶的帖子樣本 5。
- 當擁有大量粉絲的名人賬戶釋出帖子時,我們必須做大量工作將該帖子插入到他們數百萬粉絲的每個首頁時間線中。在這種情況下,丟棄一些寫入是不可接受的。解決這個問題的一種方法是將名人帖子與其他人的帖子分開處理:我們可以透過將名人帖子單獨儲存並在讀取時與物化時間線合併,來節省將它們新增到數百萬時間線的工作。儘管有這些最佳化,在社交網路上處理名人仍然需要大量基礎設施 6。
描述效能
大多數關於軟體效能的討論都考慮兩種主要的度量型別:
- 響應時間
- 從使用者發出請求到收到所請求答案的經過時間。測量單位是秒(或毫秒,或微秒)。
- 吞吐量
- 系統正在處理的每秒請求數,或每秒資料量。對於給定的硬體資源分配,存在可以處理的 最大吞吐量。測量單位是"每秒某物"。
在社交網路案例研究中,“每秒帖子數"和"每秒時間線寫入數"是吞吐量指標,而"載入首頁時間線所需的時間"或"帖子傳遞給粉絲的時間"是響應時間指標。
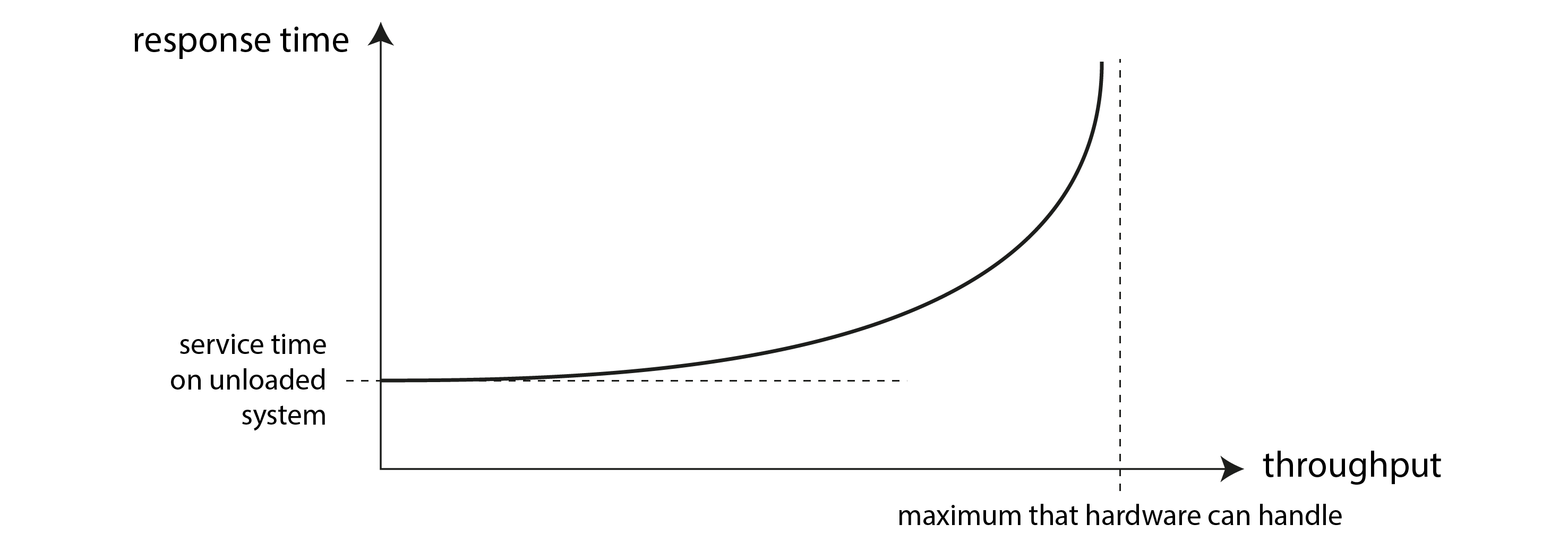
吞吐量和響應時間之間通常存在聯絡;線上服務的這種關係示例如 圖 2-3 所示。當請求吞吐量較低時,服務具有較低的響應時間,但隨著負載增加,響應時間也會增加。這是因為 排隊:當請求到達高負載系統時,CPU 很可能已經在處理先前的請求,因此傳入請求需要等待先前請求完成。隨著吞吐量接近硬體可以處理的最大值,排隊延遲急劇增加。
當過載系統無法恢復時
如果系統接近過載,吞吐量被推到極限附近,它有時會進入惡性迴圈,變得效率更低,從而更加過載。例如,如果有很長的請求佇列等待處理,響應時間可能會增加到客戶端超時並重新發送請求的程度。這導致請求率進一步增加,使問題變得更糟——重試風暴。即使負載再次降低,這樣的系統也可能保持過載狀態,直到重新啟動或以其他方式重置。這種現象稱為 亞穩態故障(Metastable Failure),它可能導致生產系統的嚴重中斷 7 8。
為了避免重試使服務過載,你可以在客戶端增加並隨機化連續重試之間的時間(指數退避 9 10),並暫時停止向最近返回錯誤或超時的服務傳送請求(使用 熔斷器 11 12 或 令牌桶 演算法 13)。伺服器還可以檢測何時接近過載並開始主動拒絕請求(負載卸除 14),併發送響應要求客戶端減速(背壓 1 15)。排隊和負載均衡演算法的選擇也可能產生影響 16。
就效能指標而言,響應時間通常是使用者最關心的,而吞吐量決定了所需的計算資源(例如,你需要多少伺服器),因此決定了服務特定工作負載的成本。如果吞吐量可能會增長超出當前硬體可以處理的範圍,則需要擴充套件容量;如果系統的最大吞吐量可以透過新增計算資源顯著增加,則稱系統為 可伸縮的。
在本節中,我們將主要關注響應時間,我們將在 “可伸縮性” 中回到吞吐量和可伸縮性。
延遲與響應時間
“延遲"和"響應時間"有時可互換使用,但在本書中我們將以特定方式使用這些術語(如 圖 2-4 所示):
- 響應時間 是客戶端看到的;它包括系統中任何地方產生的所有延遲。
- 服務時間 是服務主動處理使用者請求的持續時間。
- 排隊延遲 可能發生在流程中的幾個點:例如,在收到請求後,它可能需要等待直到 CPU 可用才能被處理;如果同一臺機器上的其他任務通過出站網路介面傳送大量資料,響應資料包可能需要在傳送之前進行緩衝。
- 延遲 是一個涵蓋請求未被主動處理時間的總稱,即在此期間它是 潛在的。特別是,網路延遲 或 網路延遲 指的是請求和響應在網路中傳輸所花費的時間。
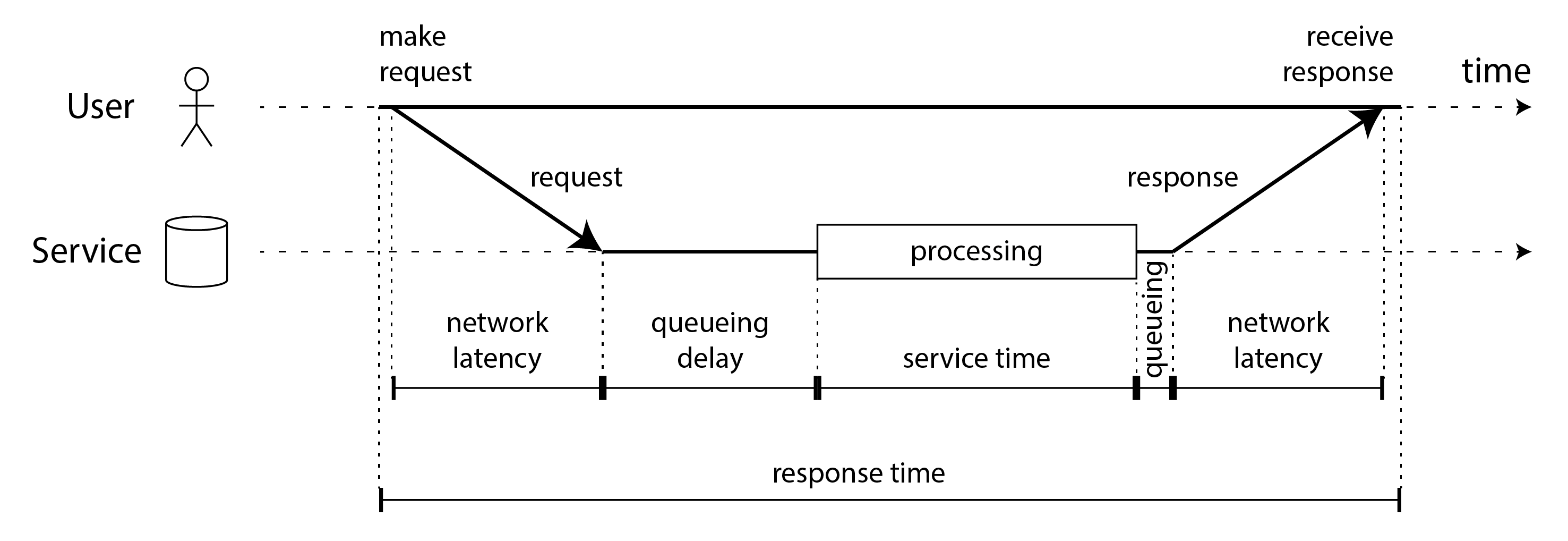
在 圖 2-4 中,時間從左到右流動,每個通訊節點顯示為水平線,請求或響應訊息顯示為從一個節點到另一個節點的粗對角箭頭。你將在本書中經常遇到這種風格的圖表。
響應時間可能會因請求而異,即使你一遍又一遍地發出相同的請求。許多因素可能會增加隨機延遲:例如,上下文切換到後臺程序、網路資料包丟失和 TCP 重傳、垃圾回收暫停、強制從磁碟讀取的缺頁錯誤、伺服器機架中的機械振動 17,或許多其他原因。我們將在 “超時與無界延遲” 中更詳細地討論這個主題。
排隊延遲通常佔響應時間變化的很大一部分。由於伺服器只能並行處理少量事務(例如,受其 CPU 核心數的限制),只需要少量慢請求就可以阻塞後續請求的處理——這種效應稱為 隊頭阻塞。即使那些後續請求的服務時間很快,由於等待先前請求完成的時間,客戶端仍會看到緩慢的整體響應時間。排隊延遲不是服務時間的一部分,因此在客戶端測量響應時間很重要。
平均值、中位數與百分位數
因為響應時間因請求而異,我們需要將其視為值的 分佈,而不是單個數字。在 圖 2-5 中,每個灰色條表示對服務的請求,其高度顯示該請求花費的時間。大多數請求相當快,但偶爾會有 異常值 需要更長時間。網路延遲的變化也稱為 抖動。
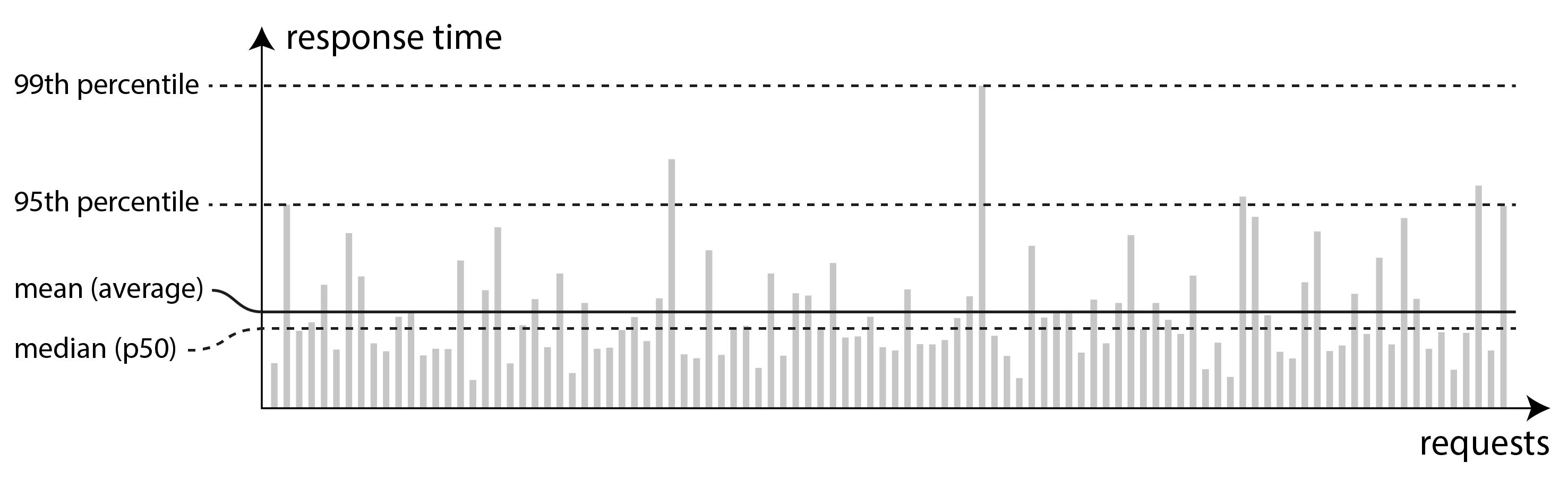
報告服務的 平均 響應時間是常見的(技術上是 算術平均值:即,將所有響應時間相加,然後除以請求數)。平均響應時間對於估計吞吐量限制很有用 18。然而,如果你想知道你的"典型"響應時間,平均值不是一個很好的指標,因為它不能告訴你有多少使用者實際經歷了那種延遲。
通常使用 百分位數 更好。如果你將響應時間列表從最快到最慢排序,那麼 中位數 就在中間:例如,如果你的中位響應時間是 200 毫秒,這意味著一半的請求在不到 200 毫秒內返回,一半的請求花費的時間更長。這使得中位數成為了解使用者通常需要等待多長時間的良好指標。中位數也稱為 第 50 百分位,有時縮寫為 p50。
為了弄清異常值有多糟糕,你可以檢視更高的百分位數:第 95、99 和 99.9 百分位數很常見(縮寫為 p95、p99 和 p999)。它們是 95%、99% 或 99.9% 的請求比該特定閾值快的響應時間閾值。例如,如果第 95 百分位響應時間是 1.5 秒,這意味著 100 個請求中的 95 個花費不到 1.5 秒,100 個請求中的 5 個花費 1.5 秒或更長時間。這在 圖 2-5 中有所說明。
響應時間的高百分位數,也稱為 尾部延遲,很重要,因為它們直接影響使用者的服務體驗。例如,亞馬遜在描述內部服務的響應時間要求時使用第 99.9 百分位,即使它隻影響 1,000 個請求中的 1 個。這是因為請求最慢的客戶通常是那些賬戶上資料最多的客戶,因為他們進行了許多購買——也就是說,他們是最有價值的客戶 19。確保網站對他們來說速度快對於保持這些客戶的滿意度很重要。
另一方面,最佳化第 99.99 百分位(10,000 個請求中最慢的 1 個)被認為太昂貴,對亞馬遜的目的沒有足夠的好處。在非常高的百分位數上減少響應時間很困難,因為它們很容易受到你無法控制的隨機事件的影響,而且收益遞減。
響應時間對使用者的影響
直覺上似乎很明顯,快速服務比慢速服務對使用者更好 20。然而,要獲得可靠的資料來量化延遲對使用者行為的影響是令人驚訝地困難的。
一些經常被引用的統計資料是不可靠的。2006 年,谷歌報告說,搜尋結果從 400 毫秒減慢到 900 毫秒與流量和收入下降 20% 相關 21。然而,2009 年穀歌的另一項研究報告說,延遲增加 400 毫秒導致每天搜尋減少僅 0.6% 22,同年必應發現載入時間增加兩秒將廣告收入減少 4.3% 23。這些公司的較新資料似乎沒有公開。
Akamai 最近的一項研究 24 聲稱響應時間增加 100 毫秒將電子商務網站的轉化率降低多達 7%;然而,仔細檢查後,同一研究顯示,非常 快 的頁面載入時間也與較低的轉化率相關!這個看似矛盾的結果是因為載入最快的頁面通常是那些沒有有用內容的頁面(例如,404 錯誤頁面)。然而,由於該研究沒有努力將頁面內容的影響與載入時間的影響分開,其結果可能沒有意義。
雅虎的一項研究 25 比較了快速載入與慢速載入搜尋結果的點選率,控制了搜尋結果的質量。它發現當快速和慢速響應之間的差異為 1.25 秒或更多時,快速搜尋的點選次數增加 20-30%。
響應時間指標的應用
高百分位數在被多次呼叫作為服務單個終端使用者請求的一部分的後端服務中尤其重要。即使你並行進行呼叫,終端使用者請求仍然需要等待最慢的並行呼叫完成。只需要一個慢呼叫就可以使整個終端使用者請求變慢,如 圖 2-6 所示。即使只有一小部分後端呼叫很慢,如果終端使用者請求需要多個後端呼叫,獲得慢呼叫的機會就會增加,因此更高比例的終端使用者請求最終會變慢(這種效應稱為 尾部延遲放大 26)。
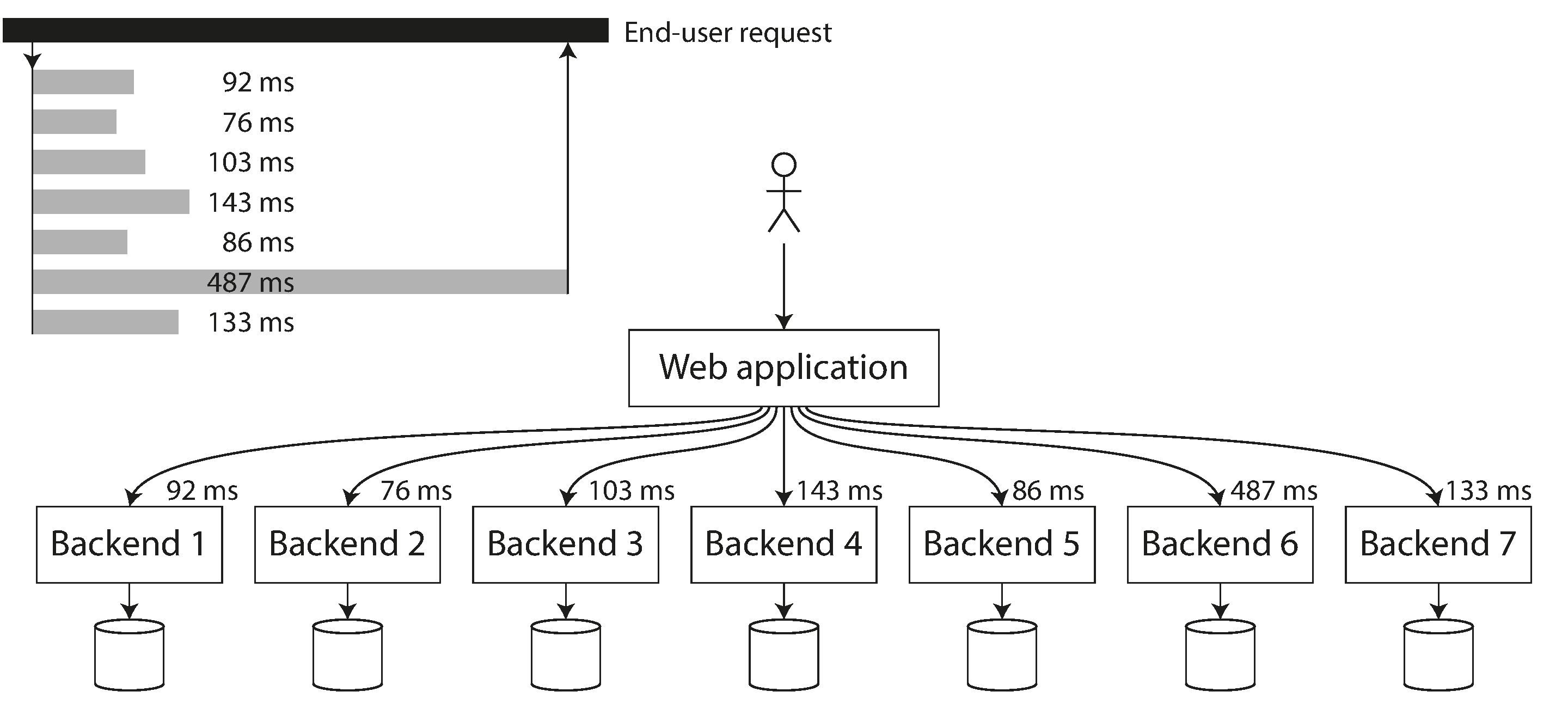
百分位數通常用於 服務級別目標(SLO)和 服務級別協議(SLA),作為定義服務預期效能和可用性的方式 27。例如,SLO 可能設定服務的中位響應時間小於 200 毫秒且第 99 百分位低於 1 秒的目標,以及至少 99.9% 的有效請求導致非錯誤響應的目標。SLA 是一份合同,規定如果不滿足 SLO 會發生什麼(例如,客戶可能有權獲得退款)。這至少是基本想法;實際上,為 SLO 和 SLA 定義良好的可用性指標並不簡單 28 29。
計算百分位數
如果你想將響應時間百分位數新增到服務的監控儀表板中,你需要持續有效地計算它們。例如,你可能希望保留過去 10 分鐘內請求的響應時間的滾動視窗。每分鐘,你計算該視窗中值的中位數和各種百分位數,並在圖表上繪製這些指標。
最簡單的實現是在時間視窗內保留所有請求的響應時間列表,並每分鐘對該列表進行排序。如果這對你來說效率太低,有一些演算法可以以最小的 CPU 和記憶體成本計算百分位數的良好近似值。開源百分位數估計庫包括 HdrHistogram、t-digest 30 31、OpenHistogram 32 和 DDSketch 33。
請注意,平均百分位數,例如,減少時間解析度或組合來自多臺機器的資料,在數學上是沒有意義的——聚合響應時間資料的正確方法是新增直方圖 34。
可靠性與容錯
每個人都對某物是否可靠或不可靠有直觀的想法。對於軟體,典型的期望包括:
- 應用程式執行使用者期望的功能。
- 它可以容忍使用者犯錯誤或以意想不到的方式使用軟體。
- 在預期的負載和資料量下,其效能足以滿足所需的用例。
- 系統防止任何未經授權的訪問和濫用。
如果所有這些加在一起意味著"正確工作”,那麼我們可以將 可靠性 大致理解為"即使出現問題也能繼續正確工作”。為了更準確地說明出現問題,我們將區分 故障 和 失效 35 36 37:
- 故障
- 故障是指系統的某個特定 部分 停止正確工作:例如,如果單個硬碟驅動器發生故障,或單臺機器崩潰,或外部服務(系統所依賴的)發生中斷。
- 失效
- 失效是指 整個 系統停止向用戶提供所需的服務;換句話說,當它不滿足服務級別目標(SLO)時。
故障和失效之間的區別可能會令人困惑,因為它們在不同層面上是同一件事。例如,如果硬碟驅動器停止工作,我們說硬碟驅動器已失效:如果系統僅由該一個硬碟驅動器組成,它已停止提供所需的服務。然而,如果你正在談論的系統包含許多硬碟驅動器,那麼從更大系統的角度來看,單個硬碟驅動器的失效只是一個故障,並且更大的系統可能能夠透過在另一個硬碟驅動器上擁有資料副本來容忍該故障。
容錯
如果系統在發生某些故障時仍繼續向用戶提供所需的服務,我們稱系統為 容錯的。如果系統不能容忍某個部分變得有故障,我們稱該部分為 單點故障(SPOF),因為該部分的故障會升級導致整個系統的失效。
例如,在社交網路案例研究中,可能發生的故障是在扇出過程中,參與更新物化時間線的機器崩潰或變得不可用。為了使這個過程容錯,我們需要確保另一臺機器可以接管這項任務,而不會錯過任何應該交付的帖子,也不會複製任何帖子。(這個想法被稱為 精確一次語義,我們將在 [待補充連結] 中詳細研究它。)
容錯總是限於某些型別的某些數量的故障。例如,系統可能能夠容忍最多兩個硬碟驅動器同時故障,或最多三個節點中的一個崩潰。如果所有節點都崩潰,沒有什麼可以做的,這沒有意義容忍任何數量的故障。如果整個地球(及其上的所有伺服器)被黑洞吞噬,容忍該故障將需要在太空中進行網路託管——祝你獲得批准該預算專案的好運。
反直覺地,在這種容錯系統中,透過故意觸發故障來 增加 故障率是有意義的——例如,在沒有警告的情況下隨機殺死單個程序。這稱為 故障注入。許多關鍵錯誤實際上是由於錯誤處理不當造成的 38;透過故意引發故障,你確保容錯機制不斷得到鍛鍊和測試,這可以增加你對故障自然發生時將被正確處理的信心。混沌工程 是一門旨在透過故意注入故障等實驗來提高對容錯機制的信心的學科 39。
儘管我們通常更喜歡容忍故障而不是預防故障,但在預防比治療更好的情況下(例如,因為不存在治療方法)。安全問題就是這種情況:如果攻擊者已經破壞了系統並獲得了對敏感資料的訪問,該事件無法撤消。然而,本書主要涉及可以治癒的故障型別,如以下部分所述。
硬體與軟體故障
當我們想到系統失效的原因時,硬體故障很快就會浮現在腦海中:
- 大約 2-5% 的磁性硬碟驅動器每年發生故障 40 41;在擁有 10,000 個磁碟的儲存叢集中,我們因此應該期望平均每天有一個磁碟故障。最近的資料表明磁碟變得更可靠,但故障率仍然很顯著 42。
- 大約 0.5-1% 的固態硬碟(SSD)每年發生故障 43。少量位錯誤會自動糾正 44,但不可糾正的錯誤大約每年每個驅動器發生一次,即使在相當新的驅動器中(即,經歷很少磨損);這個錯誤率高於磁性硬碟驅動器 45、46。
- 其他硬體元件,如電源、RAID 控制器和記憶體模組也會發生故障,儘管頻率低於硬碟驅動器 47 48。
- 大約千分之一的機器有一個 CPU 核心偶爾計算錯誤的結果,可能是由於製造缺陷 49 50 51。在某些情況下,錯誤的計算會導致崩潰,但在其他情況下,它會導致程式簡單地返回錯誤的結果。
- RAM 中的資料也可能被損壞,要麼是由於宇宙射線等隨機事件,要麼是由於永久性物理缺陷。即使使用糾錯碼(ECC)的記憶體,超過 1% 的機器在給定年份遇到不可糾正的錯誤,這通常會導致機器崩潰和受影響的記憶體模組需要更換 52。此外,某些病理記憶體訪問模式可以以高機率翻轉位 53。
- 整個資料中心可能變得不可用(例如,由於停電或網路配置錯誤)甚至被永久摧毀(例如,由火災、洪水或地震 54)。太陽風暴,當太陽噴射大量帶電粒子時,會在長距離電線中感應出大電流,可能會損壞電網和海底網路電纜 55。儘管這種大規模故障很少見,但如果服務不能容忍資料中心的丟失,它們的影響可能是災難性的 56。
這些事件足夠罕見,你在處理小型系統時通常不需要擔心它們,只要你可以輕鬆更換變得有故障的硬體。然而,在大規模系統中,硬體故障發生得足夠頻繁,以至於它們成為正常系統執行的一部分。
透過冗餘容忍硬體故障
我們對不可靠硬體的第一反應通常是向各個硬體元件新增冗餘,以降低系統的故障率。磁碟可以設定為 RAID 配置(將資料分佈在同一臺機器的多個磁碟上,以便故障磁碟不會導致資料丟失),伺服器可能有雙電源和可熱插拔的 CPU,資料中心可能有電池和柴油發電機作為備用電源。這種冗餘通常可以使機器不間斷執行多年。
當元件故障獨立時,冗餘最有效,即一個故障的發生不會改變另一個故障發生的可能性。然而,經驗表明,元件故障之間通常存在顯著的相關性 41 57 58;整個伺服器機架或整個資料中心的不可用仍然比我們希望的更頻繁地發生。
硬體冗餘增加了單臺機器的正常執行時間;然而,如 “分散式與單節點系統” 中所討論的,使用分散式系統有一些優勢,例如能夠容忍一個數據中心的完全中斷。出於這個原因,雲系統傾向於較少關注單個機器的可靠性,而是旨在透過在軟體級別容忍故障節點來使服務高度可用。雲提供商使用 可用區 來識別哪些資源在物理上位於同一位置;同一地方的資源比地理上分離的資源更可能同時發生故障。
我們在本書中討論的容錯技術旨在容忍整個機器、機架或可用區的丟失。它們通常透過允許一個數據中心的機器在另一個數據中心的機器發生故障或變得不可達時接管來工作。我們將在 第 6 章、第 10 章 以及本書的其他各個地方討論這種容錯技術。
能夠容忍整個機器丟失的系統也具有運營優勢:如果你需要重新啟動機器(例如,應用作業系統安全補丁),單伺服器系統需要計劃停機時間,而多節點容錯系統可以一次修補一個節點,而不影響使用者的服務。這稱為 滾動升級,我們將在 第 5 章 中進一步討論它。
軟體故障
儘管硬體故障可能是弱相關的,但它們大多仍然是獨立的:例如,如果一個磁碟發生故障,同一臺機器中的其他磁碟很可能在一段時間內還能正常工作。另一方面,軟體故障通常高度相關,因為許多節點執行相同的軟體並因此具有相同的錯誤是常見的 59 60。這種故障比不相關的硬體故障更難預料,並且它們往往導致比硬體故障更多的系統失效 47。例如:
- 在特定情況下導致每個節點同時失效的軟體錯誤。例如,2012 年 6 月 30 日,閏秒導致許多 Java 應用程式由於 Linux 核心中的錯誤而同時掛起 61。由於韌體錯誤,某些型號的所有 SSD 在精確執行 32,768 小時(不到 4 年)後突然失效,使其上的資料無法恢復 62。
- 使用某些共享、有限資源(如 CPU 時間、記憶體、磁碟空間、網路頻寬或執行緒)的失控程序 63。例如,處理大請求時消耗過多記憶體的程序可能會被作業系統殺死。客戶端庫中的錯誤可能導致比預期更高的請求量 64。
- 系統所依賴的服務變慢、無響應或開始返回損壞的響應。
- 不同系統之間的互動導致在隔離測試每個系統時不會發生的緊急行為 65。
- 級聯故障,其中一個元件中的問題導致另一個元件過載和減速,這反過來又導致另一個元件崩潰 66 67。
導致這些型別軟體故障的錯誤通常會潛伏很長時間,直到它們被一組不尋常的環境觸發。在這些情況下,軟體對其環境做出了某種假設——雖然該假設通常是正確的,但它最終由於某種原因不再成立 68 69。
軟體中的系統故障沒有快速解決方案。許多小事情可以幫助:仔細考慮系統中的假設和互動;徹底測試;程序隔離;允許程序崩潰和重新啟動;避免反饋迴圈,如重試風暴(參見 “當過載系統無法恢復時”);測量、監控和分析生產中的系統行為。
人類與可靠性
人類設計和構建軟體系統,保持系統執行的操作員也是人類。與機器不同,人類不只是遵循規則;他們的力量是創造性和適應性地完成工作。然而,這一特徵也導致不可預測性,有時會導致失效的錯誤,儘管有最好的意圖。例如,一項對大型網際網路服務的研究發現,操作員的配置更改是中斷的主要原因,而硬體故障(伺服器或網路)僅在 10-25% 的中斷中發揮作用 70。
將這些問題標記為"人為錯誤"並希望透過更嚴格的程式和規則合規性來更好地控制人類行為來解決它們是很誘人的。然而,責怪人們的錯誤是適得其反的。我們所說的"人為錯誤"實際上不是事件的原因,而是人們在社會技術系統中盡力做好工作的問題的症狀 71。通常,複雜系統具有緊急行為,元件之間的意外互動也可能導致故障 72。
各種技術措施可以幫助最小化人為錯誤的影響,包括徹底測試(手寫測試和對大量隨機輸入的 屬性測試)38、快速回滾配置更改的回滾機制、新程式碼的逐步推出、詳細和清晰的監控、用於診斷生產問題的可觀測性工具(參見 “分散式系統的問題”),以及鼓勵"正確的事情"並阻止"錯誤的事情"的精心設計的介面。
然而,這些事情需要時間和金錢的投資,在日常業務的務實現實中,組織通常優先考慮創收活動而不是增加其抵禦錯誤的韌性的措施。如果在更多功能和更多測試之間有選擇,許多組織可以理解地選擇功能。鑑於這種選擇,當可預防的錯誤不可避免地發生時,責怪犯錯誤的人是沒有意義的——問題是組織的優先事項。
越來越多的組織正在採用 無責備事後分析 的文化:事件發生後,鼓勵相關人員充分分享發生的事情的細節,而不用擔心懲罰,因為這允許組織中的其他人學習如何在未來防止類似的問題 73。這個過程可能會發現需要改變業務優先順序、需要投資於被忽視的領域、需要改變相關人員的激勵措施,或者需要引起管理層注意的其他一些系統性問題。
作為一般原則,在調查事件時,你應該對簡單化的答案持懷疑態度。“鮑勃在部署該更改時應該更加小心"是沒有成效的,但"我們必須用 Haskell 重寫後端"也不是。相反,管理層應該藉此機會從每天與之合作的人的角度瞭解社會技術系統如何工作的細節,並根據這些反饋採取措施改進它 71。
可靠性有多重要?
可靠性不僅僅適用於核電站和空中交通管制——更平凡的應用程式也應該可靠地工作。業務應用程式中的錯誤會導致生產力損失(如果數字報告不正確,還會有法律風險),電子商務網站的中斷可能會在收入和聲譽損害方面造成巨大成本。
在許多應用程式中,幾分鐘甚至幾小時的臨時中斷是可以容忍的 74,但永久資料丟失或損壞將是災難性的。考慮一位家長在你的照片應用程式中儲存他們孩子的所有照片和影片 75。如果該資料庫突然損壞,他們會有什麼感覺?他們會知道如何從備份中恢復嗎?
作為不可靠軟體如何傷害人們的另一個例子,考慮郵局地平線醜聞。在 1999 年至 2019 年期間,管理英國郵局分支機構的數百人因會計軟體顯示其賬戶短缺而被判盜竊或欺詐罪。最終變得清楚,許多這些短缺是由於軟體中的錯誤,許多定罪已被推翻 76。導致這一可能是英國曆史上最大的司法不公的是,英國法律假設計算機正確執行(因此,計算機產生的證據是可靠的),除非有相反的證據 77。軟體工程師可能會嘲笑軟體可能無錯誤的想法,但這對那些因不可靠的計算機系統而被錯誤監禁、宣佈破產甚至自殺的人來說,這是很少的安慰。
在某些情況下,我們可能選擇犧牲可靠性以降低開發成本(例如,在為未經證實的市場開發原型產品時)——但我們應該非常清楚何時走捷徑並牢記潛在的後果。
可伸縮性
即使系統今天可靠地工作,這並不意味著它將來必然會可靠地工作。降級的一個常見原因是負載增加:也許系統已經從 10,000 個併發使用者增長到 100,000 個併發使用者,或者從 100 萬增長到 1000 萬。也許它正在處理比以前大得多的資料量。
可伸縮性 是我們用來描述系統應對負載增加能力的術語。有時,在討論可伸縮性時,人們會發表評論,如"你不是谷歌或亞馬遜。停止擔心規模,只使用關係資料庫。“這個格言是否適用於你取決於你正在構建的應用程式型別。
如果你正在構建一個目前只有少數使用者的新產品,也許是在初創公司,首要的工程目標通常是保持系統儘可能簡單和靈活,以便你可以在瞭解更多關於客戶需求時輕鬆修改和調整產品的功能 78。在這種環境中,擔心未來可能需要的假設規模是適得其反的:在最好的情況下,對可伸縮性的投資是浪費的努力和過早的最佳化;在最壞的情況下,它們會將你鎖定在不靈活的設計中,並使你的應用程式更難發展。
原因是可伸縮性不是一維標籤:說"X 是可伸縮的"或"Y 不伸縮"是沒有意義的。相反,討論可伸縮性意味著考慮諸如以下問題:
- “如果系統以特定方式增長,我們有什麼選擇來應對增長?”
- “我們如何新增計算資源來處理額外的負載?”
- “基於當前的增長預測,我們何時會達到當前架構的極限?”
如果你成功地使你的應用程式受歡迎,因此處理越來越多的負載,你將瞭解你的效能瓶頸在哪裡,因此你將知道需要沿著哪些維度進行伸縮。那時是開始擔心可伸縮性技術的時候。
描述負載
首先,我們需要簡潔地描述系統上的當前負載;只有這樣我們才能討論增長問題(如果我們的負載翻倍會發生什麼?)。通常這將是吞吐量的度量:例如,對服務的每秒請求數、每天到達多少千兆位元組的新資料,或每小時購物車結賬的數量。有時你關心某個變數數量的峰值,例如 “案例研究:社交網路首頁時間線” 中同時線上使用者的數量。
通常還有其他影響訪問模式並因此影響可伸縮性要求的負載統計特徵。例如,你可能需要知道資料庫中的讀寫比率、快取的命中率或每個使用者的資料項數量(例如,社交網路案例研究中的粉絲數量)。也許平均情況對你很重要,或者也許你的瓶頸由少數極端情況主導。這一切都取決於你特定應用程式的細節。
一旦你描述了系統上的負載,你就可以調查當負載增加時會發生什麼。你可以從兩個方面來看待它:
- 當你以某種方式增加負載並保持系統資源(CPU、記憶體、網路頻寬等)不變時,系統的效能如何受到影響?
- 當你以某種方式增加負載時,如果你想保持效能不變,你需要增加多少資源?
通常我們的目標是在最小化執行系統成本的同時保持系統性能在 SLA 的要求範圍內(參見 “響應時間指標的應用”)。所需的計算資源越多,成本就越高。可能某些型別的硬體比其他型別更具成本效益,這些因素可能會隨著新型別硬體的出現而隨時間變化。
如果你可以將資源翻倍以處理兩倍的負載,同時保持效能不變,我們說你有 線性可伸縮性,這被認為是好事。偶爾,由於規模經濟或峰值負載的更好分佈,可以用不到兩倍的資源處理兩倍的負載 79 80。更可能的是,成本增長速度快於線性,並且效率低下可能有許多原因。例如,如果你有大量資料,那麼處理單個寫請求可能涉及比你有少量資料時更多的工作,即使請求的大小相同。
共享記憶體、共享磁碟與無共享架構
增加服務硬體資源的最簡單方法是將其移動到更強大的機器。單個 CPU 核心不再變得顯著更快,但你可以購買一臺機器(或租用雲實例)具有更多 CPU 核心、更多 RAM 和更多磁碟空間。這種方法稱為 縱向伸縮 或 向上擴充套件。
你可以透過使用多個程序或執行緒在單臺機器上獲得並行性。屬於同一程序的所有執行緒都可以訪問相同的 RAM,因此這種方法也稱為 共享記憶體架構。共享記憶體方法的問題是成本增長速度快於線性:具有兩倍硬體資源的高階機器通常成本遠遠超過兩倍。由於瓶頸,兩倍大小的機器通常可以處理不到兩倍的負載。
另一種方法是 共享磁碟架構,它使用幾臺具有獨立 CPU 和 RAM 的機器,但將資料儲存在機器之間共享的磁碟陣列上,這些機器透過快速網路連線:網路附加儲存(NAS)或 儲存區域網路(SAN)。這種架構傳統上用於本地資料倉庫工作負載,但爭用和鎖定的開銷限制了共享磁碟方法的可伸縮性 81。
相比之下,無共享架構 82(也稱為 橫向伸縮 或 向外擴充套件)已經獲得了很大的流行。在這種方法中,我們使用具有多個節點的分散式系統,每個節點都有自己的 CPU、RAM 和磁碟。節點之間的任何協調都在軟體級別透過傳統網路完成。
無共享的優點是它有線性伸縮的潛力,它可以使用提供最佳價效比的任何硬體(特別是在雲中),它可以隨著負載的增加或減少更容易地調整其硬體資源,並且它可以透過在多個數據中心和地區分佈系統來實現更大的容錯。缺點是它需要顯式分片(參見 第 7 章),並且它會產生分散式系統的所有複雜性(第 9 章)。
一些雲原生資料庫系統為儲存和事務執行使用單獨的服務(參見 “儲存與計算分離”),多個計算節點共享對同一儲存服務的訪問。這個模型與共享磁碟架構有一些相似之處,但它避免了舊系統的可伸縮性問題:它不是提供檔案系統(NAS)或塊裝置(SAN)抽象,而是儲存服務提供專門為資料庫特定需求設計的 API 83。
可伸縮性原則
在大規模執行的系統架構通常對應用程式高度特定——沒有通用的、一刀切的可伸縮架構(非正式地稱為 萬金油)。例如,設計用於處理每秒 100,000 個請求(每個 1 kB 大小)的系統與設計用於每分鐘 3 個請求(每個 2 GB 大小)的系統看起來非常不同——即使兩個系統具有相同的資料吞吐量(100 MB/秒)。
此外,適合一個負載級別的架構不太可能應對 10 倍的負載。如果你正在開發快速增長的服務,因此很可能你需要在每個數量級的負載增加時重新考慮你的架構。由於應用程式的需求可能會演變,通常不值得提前規劃超過一個數量級的未來伸縮需求。
可伸縮性的一個良好通用原則是將系統分解為可以在很大程度上相互獨立執行的較小元件。這是微服務背後的基本原則(參見 “微服務與無伺服器”)、分片(第 7 章)、流處理([待補充連結])和無共享架構。然而,挑戰在於知道在哪裡劃分應該在一起的事物和應該分開的事物之間的界限。微服務的設計指南可以在其他書籍中找到 84,我們在 第 7 章 中討論無共享系統的分片。
另一個好原則是不要讓事情變得比必要的更複雜。如果單機資料庫可以完成工作,它可能比複雜的分散式設定更可取。自動伸縮系統(根據需求自動新增或刪除資源)很酷,但如果你的負載相當可預測,手動伸縮的系統可能會有更少的操作意外(參見 “操作:自動或手動再平衡”)。具有五個服務的系統比具有五十個服務的系統更簡單。良好的架構通常涉及方法的務實混合。
可維護性
軟體不會磨損或遭受材料疲勞,因此它不會像機械物體那樣以同樣的方式損壞。但應用程式的要求經常變化,軟體執行的環境發生變化(例如其依賴項和底層平臺),並且它有需要修復的錯誤。
人們普遍認為,軟體的大部分成本不在其初始開發中,而在其持續維護中——修復錯誤、保持其系統執行、調查故障、將其適應新平臺、為新用例修改它、償還技術債務和新增新功能 85 86。
然而,維護也很困難。如果系統已成功執行很長時間,它可能使用今天不多工程師理解的過時技術(如大型機和 COBOL 程式碼);關於系統如何以及為何以某種方式設計的機構知識可能已經隨著人們離開組織而丟失;可能需要修復其他人的錯誤。此外,計算機系統通常與它支援的人類組織交織在一起,這意味著此類 遺留 系統的維護既是人的問題,也是技術問題 87。
如果我們今天建立的每個系統都足夠有價值以長期生存,它有一天將成為遺留系統。為了最小化需要維護我們軟體的未來幾代人的痛苦,我們應該在設計時考慮維護問題。儘管我們不能總是預測哪些決定可能會在未來造成維護難題,但在本書中,我們將注意幾個廣泛適用的原則:
- 可運維性(Operability)
- 使組織容易保持系統平穩執行。
- 簡單性(Simplicity)
- 透過使用易於理解、一致的模式和結構來實施它,並避免不必要的複雜性,使新工程師容易理解系統。
- 可演化性(Evolvability)
- 使工程師將來容易對系統進行更改,隨著需求變化而適應和擴充套件它以用於未預料的用例。
可運維性:讓運維更輕鬆
我們之前在 “雲時代的運維” 中討論了運維的角色,我們看到人類流程對於可靠運維至少與軟體工具一樣重要。 事實上,有人提出 “良好的運維通常可以解決糟糕(或不完整)軟體的侷限性,但再好的軟體碰上糟糕的運維也難以可靠地執行” 60。
在由數千臺機器組成的大規模系統中,手動維護將是不合理地昂貴的,自動化是必不可少的。然而,自動化可能是一把雙刃劍: 總會有邊緣情況(如罕見的故障場景)需要運維團隊的手動干預。由於無法自動處理的情況是最複雜的問題,更大的自動化需要一個 更 熟練的運維團隊來解決這些問題 88。
此外,如果自動化系統出錯,通常比依賴操作員手動執行某些操作的系統更難排除故障。出於這個原因,更多的自動化並不總是對可操作性更好。 然而,一定程度的自動化很重要,最佳點將取決於你特定應用程式和組織的細節。
良好的可操作性意味著使常規任務變得容易,使運維團隊能夠將精力集中在高價值活動上。 資料系統可以做各種事情來使常規任務變得容易,包括 89:
- 允許監控工具檢查系統的關鍵指標,並支援可觀測性工具(參見 “分散式系統的問題”)以深入瞭解系統的執行時行為。各種商業和開源工具可以在這裡提供幫助 90。
- 避免對單個機器的依賴(允許在系統整體繼續不間斷執行的同時關閉機器進行維護)
- 提供良好的文件和易於理解的操作模型(“如果我做 X,Y 將會發生”)
- 提供良好的預設行為,但也給管理員在需要時覆蓋預設值的自由
- 在適當的地方自我修復,但也在需要時給管理員手動控制系統狀態
- 表現出可預測的行為,最小化意外
簡單性:管理複雜度
小型軟體專案可以有令人愉快地簡單和富有表現力的程式碼,但隨著專案變大,它們通常變得非常複雜且難以理解。 這種複雜性減慢了需要在系統上工作的每個人,進一步增加了維護成本。陷入複雜性的軟體專案有時被描述為 大泥球 91。
當複雜性使維護困難時,預算和時間表經常超支。在複雜軟體中,進行更改時引入錯誤的風險也更大: 當系統對開發人員來說更難理解和推理時,隱藏的假設、意外的後果和意外的互動更容易被忽視 69。 相反,降低複雜性極大地提高了軟體的可維護性,因此簡單性應該是我們構建的系統的關鍵目標。
簡單系統更容易理解,因此我們應該嘗試以儘可能簡單的方式解決給定問題。不幸的是,這說起來容易做起來難。 某物是否簡單通常是主觀的品味問題,因為沒有客觀的簡單性標準 92。例如,一個系統可能在簡單介面後面隱藏複雜的實現, 而另一個系統可能有一個向用戶公開更多內部細節的簡單實現——哪一個更簡單?
推理複雜性的一種嘗試是將其分為兩類,本質複雜性 和 偶然複雜性 93。 這個想法是,本質複雜性是應用程式問題域中固有的,而偶然複雜性僅由於我們工具的限制而產生。 不幸的是,這種區別也有缺陷,因為本質和偶然之間的邊界隨著我們工具的發展而變化 94。
我們管理複雜性的最佳工具之一是 抽象。良好的抽象可以在乾淨、易於理解的外觀後面隱藏大量實現細節。良好的抽象也可以用於各種不同的應用程式。 這種重用不僅比多次重新實現類似的東西更有效,而且還導致更高質量的軟體,因為抽象元件中的質量改進使所有使用它的應用程式受益。
例如,高階程式語言是隱藏機器程式碼、CPU 暫存器和系統呼叫的抽象。SQL 是一種隱藏複雜的磁碟上和記憶體中資料結構、來自其他客戶端的併發請求以及崩潰後不一致性的抽象。 當然,在用高階語言程式設計時,我們仍在使用機器程式碼;我們只是不 直接 使用它,因為程式語言抽象使我們免於考慮它。
應用程式程式碼的抽象,旨在降低其複雜性,可以使用諸如 設計模式 95 和 領域驅動設計(DDD)96 等方法建立。 本書不是關於此類特定於應用程式的抽象,而是關於你可以在其上構建應用程式的通用抽象,例如資料庫事務、索引和事件日誌。如果你想使用像 DDD 這樣的技術,你可以在本書中描述的基礎之上實現它們。
可演化性:讓變化更容易
你的系統需求將保持不變的可能性極小。它們更可能處於不斷變化中: 你學習新事實、以前未預料的用例出現、業務優先順序發生變化、使用者請求新功能、 新平臺取代舊平臺、法律或監管要求發生變化、系統增長迫使架構變化等。
在組織流程方面,敏捷 工作模式為適應變化提供了框架。敏捷社群還開發了在頻繁變化的環境中開發軟體時有用的技術工具和流程, 例如測試驅動開發(TDD)和重構。在本書中,我們搜尋在由具有不同特徵的幾個不同應用程式或服務組成的系統級別增加敏捷性的方法。
你可以修改資料系統並使其適應不斷變化的需求的容易程度與其簡單性及其抽象密切相關:鬆散耦合、簡單系統通常比緊密耦合、複雜系統更容易修改。 由於這是一個如此重要的想法,我們將使用不同的詞來指代資料系統級別的敏捷性:可演化性 97。
使大型系統中的變化困難的一個主要因素是某些操作不可逆,因此需要非常謹慎地採取該操作 98。 例如,假設你正在從一個數據庫遷移到另一個數據庫:如果在新資料庫出現問題時無法切換回舊系統,風險就會高得多,而如果你可以輕鬆返回。最小化不可逆性提高了靈活性。
總結
在本章中,我們研究了幾個非功能性需求的例子:效能、可靠性、可伸縮性和可維護性。 透過這些主題,我們還遇到了我們在本書其餘部分需要的原則和術語。我們從社交網路中首頁時間線如何實現的案例研究開始,這說明了規模上出現的一些挑戰。
我們討論了如何衡量效能(例如,使用響應時間百分位數)、系統上的負載(例如,使用吞吐量指標),以及它們如何在 SLA 中使用。 可伸縮性是一個密切相關的概念:即,在負載增長時確保效能保持不變。我們看到了可伸縮性的一些一般原則,例如將任務分解為可以獨立執行的較小部分,我們將在以下章節中深入研究可伸縮性技術的技術細節。
為了實現可靠性,你可以使用容錯技術,即使某個元件(例如,磁碟、機器或其他服務)出現故障,系統也可以繼續提供其服務。 我們看到了可能發生的硬體故障的例子,並將它們與軟體故障區分開來,軟體故障可能更難處理,因為它們通常是強相關的。 實現可靠性的另一個方面是建立對人類犯錯誤的韌性,我們看到無責備事後分析作為從事件中學習的技術。
最後,我們研究了可維護性的幾個方面,包括支援運維團隊的工作、管理複雜性以及隨著時間的推移使應用程式功能易於演化。 實現這些目標沒有簡單的答案,但有一件事可以幫助,那就是使用提供有用抽象的易於理解的構建塊來構建應用程式。本書的其餘部分將涵蓋一系列在實踐中被證明有價值的構建塊。
參考
Mike Cvet. How We Learned to Stop Worrying and Love Fan-In at Twitter. At QCon San Francisco, December 2016. ↩︎ ↩︎
Raffi Krikorian. Timelines at Scale. At QCon San Francisco, November 2012. Archived at perma.cc/V9G5-KLYK ↩︎
Twitter. Twitter’s Recommendation Algorithm. blog.twitter.com, March 2023. Archived at perma.cc/L5GT-229T ↩︎
Raffi Krikorian. New Tweets per second record, and how! blog.twitter.com, August 2013. Archived at perma.cc/6JZN-XJYN ↩︎
Jaz Volpert. When Imperfect Systems are Good, Actually: Bluesky’s Lossy Timelines. jazco.dev, February 2025. Archived at perma.cc/2PVE-L2MX ↩︎
Samuel Axon. 3% of Twitter’s Servers Dedicated to Justin Bieber. mashable.com, September 2010. Archived at perma.cc/F35N-CGVX ↩︎
Nathan Bronson, Abutalib Aghayev, Aleksey Charapko, and Timothy Zhu. Metastable Failures in Distributed Systems. At Workshop on Hot Topics in Operating Systems (HotOS), May 2021. doi:10.1145/3458336.3465286 ↩︎
Marc Brooker. Metastability and Distributed Systems. brooker.co.za, May 2021. Archived at perma.cc/7FGJ-7XRK ↩︎
Marc Brooker. Exponential Backoff And Jitter. aws.amazon.com, March 2015. Archived at perma.cc/R6MS-AZKH ↩︎
Marc Brooker. What is Backoff For? brooker.co.za, August 2022. Archived at perma.cc/PW9N-55Q5 ↩︎
Michael T. Nygard. Release It!, 2nd Edition. Pragmatic Bookshelf, January 2018. ISBN: 9781680502398 ↩︎
Frank Chen. Slowing Down to Speed Up – Circuit Breakers for Slack’s CI/CD. slack.engineering, August 2022. Archived at perma.cc/5FGS-ZPH3 ↩︎
Marc Brooker. Fixing retries with token buckets and circuit breakers. brooker.co.za, February 2022. Archived at perma.cc/MD6N-GW26 ↩︎
David Yanacek. Using load shedding to avoid overload. Amazon Builders’ Library, aws.amazon.com. Archived at perma.cc/9SAW-68MP ↩︎
Matthew Sackman. Pushing Back. wellquite.org, May 2016. Archived at perma.cc/3KCZ-RUFY ↩︎
Dmitry Kopytkov and Patrick Lee. Meet Bandaid, the Dropbox service proxy. dropbox.tech, March 2018. Archived at perma.cc/KUU6-YG4S ↩︎
Haryadi S. Gunawi, Riza O. Suminto, Russell Sears, Casey Golliher, Swaminathan Sundararaman, Xing Lin, Tim Emami, Weiguang Sheng, Nematollah Bidokhti, Caitie McCaffrey, Gary Grider, Parks M. Fields, Kevin Harms, Robert B. Ross, Andree Jacobson, Robert Ricci, Kirk Webb, Peter Alvaro, H. Birali Runesha, Mingzhe Hao, and Huaicheng Li. Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems. At 16th USENIX Conference on File and Storage Technologies, February 2018. ↩︎
Marc Brooker. Is the Mean Really Useless? brooker.co.za, December 2017. Archived at perma.cc/U5AE-CVEM ↩︎
Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall, and Werner Vogels. Dynamo: Amazon’s Highly Available Key-Value Store. At 21st ACM Symposium on Operating Systems Principles (SOSP), October 2007. doi:10.1145/1294261.1294281 ↩︎
Kathryn Whitenton. The Need for Speed, 23 Years Later. nngroup.com, May 2020. Archived at perma.cc/C4ER-LZYA ↩︎
Greg Linden. Marissa Mayer at Web 2.0. glinden.blogspot.com, November 2005. Archived at perma.cc/V7EA-3VXB ↩︎
Jake Brutlag. Speed Matters for Google Web Search. services.google.com, June 2009. Archived at perma.cc/BK7R-X7M2 ↩︎
Eric Schurman and Jake Brutlag. Performance Related Changes and their User Impact. Talk at Velocity 2009. ↩︎
Akamai Technologies, Inc. The State of Online Retail Performance. akamai.com, April 2017. Archived at perma.cc/UEK2-HYCS ↩︎
Xiao Bai, Ioannis Arapakis, B. Barla Cambazoglu, and Ana Freire. Understanding and Leveraging the Impact of Response Latency on User Behaviour in Web Search. ACM Transactions on Information Systems, volume 36, issue 2, article 21, April 2018. doi:10.1145/3106372 ↩︎
Jeffrey Dean and Luiz André Barroso. The Tail at Scale. Communications of the ACM, volume 56, issue 2, pages 74–80, February 2013. doi:10.1145/2408776.2408794 ↩︎
Alex Hidalgo. Implementing Service Level Objectives: A Practical Guide to SLIs, SLOs, and Error Budgets. O’Reilly Media, September 2020. ISBN: 1492076813 ↩︎
Jeffrey C. Mogul and John Wilkes. Nines are Not Enough: Meaningful Metrics for Clouds. At 17th Workshop on Hot Topics in Operating Systems (HotOS), May 2019. doi:10.1145/3317550.3321432 ↩︎
Tamás Hauer, Philipp Hoffmann, John Lunney, Dan Ardelean, and Amer Diwan. Meaningful Availability. At 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), February 2020. ↩︎
Ted Dunning. The t-digest: Efficient estimates of distributions. Software Impacts, volume 7, article 100049, February 2021. doi:10.1016/j.simpa.2020.100049 ↩︎
David Kohn. How percentile approximation works (and why it’s more useful than averages). timescale.com, September 2021. Archived at perma.cc/3PDP-NR8B ↩︎
Heinrich Hartmann and Theo Schlossnagle. Circllhist — A Log-Linear Histogram Data Structure for IT Infrastructure Monitoring. arxiv.org, January 2020. ↩︎
Charles Masson, Jee E. Rim, and Homin K. Lee. DDSketch: A Fast and Fully-Mergeable Quantile Sketch with Relative-Error Guarantees. Proceedings of the VLDB Endowment, volume 12, issue 12, pages 2195–2205, August 2019. doi:10.14778/3352063.3352135 ↩︎
Baron Schwartz. Why Percentiles Don’t Work the Way You Think. solarwinds.com, November 2016. Archived at perma.cc/469T-6UGB ↩︎
Walter L. Heimerdinger and Charles B. Weinstock. A Conceptual Framework for System Fault Tolerance. Technical Report CMU/SEI-92-TR-033, Software Engineering Institute, Carnegie Mellon University, October 1992. Archived at perma.cc/GD2V-DMJW ↩︎
Felix C. Gärtner. Fundamentals of fault-tolerant distributed computing in asynchronous environments. ACM Computing Surveys, volume 31, issue 1, pages 1–26, March 1999. doi:10.1145/311531.311532 ↩︎
Algirdas Avižienis, Jean-Claude Laprie, Brian Randell, and Carl Landwehr. Basic Concepts and Taxonomy of Dependable and Secure Computing. IEEE Transactions on Dependable and Secure Computing, volume 1, issue 1, January 2004. doi:10.1109/TDSC.2004.2 ↩︎
Ding Yuan, Yu Luo, Xin Zhuang, Guilherme Renna Rodrigues, Xu Zhao, Yongle Zhang, Pranay U. Jain, and Michael Stumm. Simple Testing Can Prevent Most Critical Failures: An Analysis of Production Failures in Distributed Data-Intensive Systems. At 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), October 2014. ↩︎ ↩︎
Casey Rosenthal and Nora Jones. Chaos Engineering. O’Reilly Media, April 2020. ISBN: 9781492043867 ↩︎
Eduardo Pinheiro, Wolf-Dietrich Weber, and Luiz Andre Barroso. Failure Trends in a Large Disk Drive Population. At 5th USENIX Conference on File and Storage Technologies (FAST), February 2007. ↩︎
Bianca Schroeder and Garth A. Gibson. Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? At 5th USENIX Conference on File and Storage Technologies (FAST), February 2007. ↩︎ ↩︎
Andy Klein. Backblaze Drive Stats for Q2 2021. backblaze.com, August 2021. Archived at perma.cc/2943-UD5E ↩︎
Iyswarya Narayanan, Di Wang, Myeongjae Jeon, Bikash Sharma, Laura Caulfield, Anand Sivasubramaniam, Ben Cutler, Jie Liu, Badriddine Khessib, and Kushagra Vaid. SSD Failures in Datacenters: What? When? and Why? At 9th ACM International on Systems and Storage Conference (SYSTOR), June 2016. doi:10.1145/2928275.2928278 ↩︎
Alibaba Cloud Storage Team. Storage System Design Analysis: Factors Affecting NVMe SSD Performance (1). alibabacloud.com, January 2019. Archived at archive.org ↩︎
Bianca Schroeder, Raghav Lagisetty, and Arif Merchant. Flash Reliability in Production: The Expected and the Unexpected. At 14th USENIX Conference on File and Storage Technologies (FAST), February 2016. ↩︎
Jacob Alter, Ji Xue, Alma Dimnaku, and Evgenia Smirni. SSD failures in the field: symptoms, causes, and prediction models. At International Conference for High Performance Computing, Networking, Storage and Analysis (SC), November 2019. doi:10.1145/3295500.3356172 ↩︎
Daniel Ford, François Labelle, Florentina I. Popovici, Murray Stokely, Van-Anh Truong, Luiz Barroso, Carrie Grimes, and Sean Quinlan. Availability in Globally Distributed Storage Systems. At 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI), October 2010. ↩︎ ↩︎
Kashi Venkatesh Vishwanath and Nachiappan Nagappan. Characterizing Cloud Computing Hardware Reliability. At 1st ACM Symposium on Cloud Computing (SoCC), June 2010. doi:10.1145/1807128.1807161 ↩︎
Peter H. Hochschild, Paul Turner, Jeffrey C. Mogul, Rama Govindaraju, Parthasarathy Ranganathan, David E. Culler, and Amin Vahdat. Cores that don’t count. At Workshop on Hot Topics in Operating Systems (HotOS), June 2021. doi:10.1145/3458336.3465297 ↩︎
Harish Dattatraya Dixit, Sneha Pendharkar, Matt Beadon, Chris Mason, Tejasvi Chakravarthy, Bharath Muthiah, and Sriram Sankar. Silent Data Corruptions at Scale. arXiv:2102.11245, February 2021. ↩︎
Diogo Behrens, Marco Serafini, Sergei Arnautov, Flavio P. Junqueira, and Christof Fetzer. Scalable Error Isolation for Distributed Systems. At 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015. ↩︎
Bianca Schroeder, Eduardo Pinheiro, and Wolf-Dietrich Weber. DRAM Errors in the Wild: A Large-Scale Field Study. At 11th International Joint Conference on Measurement and Modeling of Computer Systems (SIGMETRICS), June 2009. doi:10.1145/1555349.1555372 ↩︎
Yoongu Kim, Ross Daly, Jeremie Kim, Chris Fallin, Ji Hye Lee, Donghyuk Lee, Chris Wilkerson, Konrad Lai, and Onur Mutlu. Flipping Bits in Memory Without Accessing Them: An Experimental Study of DRAM Disturbance Errors. At 41st Annual International Symposium on Computer Architecture (ISCA), June 2014. doi:10.5555/2665671.2665726 ↩︎
Tim Bray. Worst Case. tbray.org, October 2021. Archived at perma.cc/4QQM-RTHN ↩︎
Sangeetha Abdu Jyothi. Solar Superstorms: Planning for an Internet Apocalypse. At ACM SIGCOMM Conferene, August 2021. doi:10.1145/3452296.3472916 ↩︎
Adrian Cockcroft. Failure Modes and Continuous Resilience. adrianco.medium.com, November 2019. Archived at perma.cc/7SYS-BVJP ↩︎
Shujie Han, Patrick P. C. Lee, Fan Xu, Yi Liu, Cheng He, and Jiongzhou Liu. An In-Depth Study of Correlated Failures in Production SSD-Based Data Centers. At 19th USENIX Conference on File and Storage Technologies (FAST), February 2021. ↩︎
Edmund B. Nightingale, John R. Douceur, and Vince Orgovan. Cycles, Cells and Platters: An Empirical Analysis of Hardware Failures on a Million Consumer PCs. At 6th European Conference on Computer Systems (EuroSys), April 2011. doi:10.1145/1966445.1966477 ↩︎
Haryadi S. Gunawi, Mingzhe Hao, Tanakorn Leesatapornwongsa, Tiratat Patana-anake, Thanh Do, Jeffry Adityatama, Kurnia J. Eliazar, Agung Laksono, Jeffrey F. Lukman, Vincentius Martin, and Anang D. Satria. What Bugs Live in the Cloud? At 5th ACM Symposium on Cloud Computing (SoCC), November 2014. doi:10.1145/2670979.2670986 ↩︎
Jay Kreps. Getting Real About Distributed System Reliability. blog.empathybox.com, March 2012. Archived at perma.cc/9B5Q-AEBW ↩︎ ↩︎
Nelson Minar. Leap Second Crashes Half the Internet. somebits.com, July 2012. Archived at perma.cc/2WB8-D6EU ↩︎
Hewlett Packard Enterprise. Support Alerts – Customer Bulletin a00092491en_us. support.hpe.com, November 2019. Archived at perma.cc/S5F6-7ZAC ↩︎
Lorin Hochstein. awesome limits. github.com, November 2020. Archived at perma.cc/3R5M-E5Q4 ↩︎
Caitie McCaffrey. Clients Are Jerks: AKA How Halo 4 DoSed the Services at Launch & How We Survived. caitiem.com, June 2015. Archived at perma.cc/MXX4-W373 ↩︎
Lilia Tang, Chaitanya Bhandari, Yongle Zhang, Anna Karanika, Shuyang Ji, Indranil Gupta, and Tianyin Xu. Fail through the Cracks: Cross-System Interaction Failures in Modern Cloud Systems. At 18th European Conference on Computer Systems (EuroSys), May 2023. doi:10.1145/3552326.3587448 ↩︎
Mike Ulrich. Addressing Cascading Failures. In Betsy Beyer, Jennifer Petoff, Chris Jones, and Niall Richard Murphy (ed). Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media, 2016. ISBN: 9781491929124 ↩︎
Harri Faßbender. Cascading failures in large-scale distributed systems. blog.mi.hdm-stuttgart.de, March 2022. Archived at perma.cc/K7VY-YJRX ↩︎
Richard I. Cook. How Complex Systems Fail. Cognitive Technologies Laboratory, April 2000. Archived at perma.cc/RDS6-2YVA ↩︎
David D. Woods. STELLA: Report from the SNAFUcatchers Workshop on Coping With Complexity. snafucatchers.github.io, March 2017. Archived at archive.org ↩︎ ↩︎
David Oppenheimer, Archana Ganapathi, and David A. Patterson. Why Do Internet Services Fail, and What Can Be Done About It? At 4th USENIX Symposium on Internet Technologies and Systems (USITS), March 2003. ↩︎
Sidney Dekker. The Field Guide to Understanding ‘Human Error’, 3rd Edition. CRC Press, November 2017. ISBN: 9781472439055 ↩︎ ↩︎
Sidney Dekker. Drift into Failure: From Hunting Broken Components to Understanding Complex Systems. CRC Press, 2011. ISBN: 9781315257396 ↩︎
John Allspaw. Blameless PostMortems and a Just Culture. etsy.com, May 2012. Archived at perma.cc/YMJ7-NTAP ↩︎
Itzy Sabo. Uptime Guarantees — A Pragmatic Perspective. world.hey.com, March 2023. Archived at perma.cc/F7TU-78JB ↩︎
Michael Jurewitz. The Human Impact of Bugs. jury.me, March 2013. Archived at perma.cc/5KQ4-VDYL ↩︎
Mark Halper. How Software Bugs led to ‘One of the Greatest Miscarriages of Justice’ in British History. Communications of the ACM, January 2025. doi:10.1145/3703779 ↩︎
Nicholas Bohm, James Christie, Peter Bernard Ladkin, Bev Littlewood, Paul Marshall, Stephen Mason, Martin Newby, Steven J. Murdoch, Harold Thimbleby, and Martyn Thomas. The legal rule that computers are presumed to be operating correctly – unforeseen and unjust consequences. Briefing note, benthamsgaze.org, June 2022. Archived at perma.cc/WQ6X-TMW4 ↩︎
Dan McKinley. Choose Boring Technology. mcfunley.com, March 2015. Archived at perma.cc/7QW7-J4YP ↩︎
Andy Warfield. Building and operating a pretty big storage system called S3. allthingsdistributed.com, July 2023. Archived at perma.cc/7LPK-TP7V ↩︎
Marc Brooker. Surprising Scalability of Multitenancy. brooker.co.za, March 2023. Archived at perma.cc/ZZD9-VV8T ↩︎
Ben Stopford. Shared Nothing vs. Shared Disk Architectures: An Independent View. benstopford.com, November 2009. Archived at perma.cc/7BXH-EDUR ↩︎
Michael Stonebraker. The Case for Shared Nothing. IEEE Database Engineering Bulletin, volume 9, issue 1, pages 4–9, March 1986. ↩︎
Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, and Vikram Wakade. Socrates: The New SQL Server in the Cloud. At ACM International Conference on Management of Data (SIGMOD), pages 1743–1756, June 2019. doi:10.1145/3299869.3314047 ↩︎
Sam Newman. Building Microservices, second edition. O’Reilly Media, 2021. ISBN: 9781492034025 ↩︎
Nathan Ensmenger. When Good Software Goes Bad: The Surprising Durability of an Ephemeral Technology. At The Maintainers Conference, April 2016. Archived at perma.cc/ZXT4-HGZB ↩︎
Robert L. Glass. Facts and Fallacies of Software Engineering. Addison-Wesley Professional, October 2002. ISBN: 9780321117427 ↩︎
Marianne Bellotti. Kill It with Fire. No Starch Press, April 2021. ISBN: 9781718501188 ↩︎
Lisanne Bainbridge. Ironies of automation. Automatica, volume 19, issue 6, pages 775–779, November 1983. doi:10.1016/0005-1098(83)90046-8 ↩︎
James Hamilton. On Designing and Deploying Internet-Scale Services. At 21st Large Installation System Administration Conference (LISA), November 2007. ↩︎
Dotan Horovits. Open Source for Better Observability. horovits.medium.com, October 2021. Archived at perma.cc/R2HD-U2ZT ↩︎
Brian Foote and Joseph Yoder. Big Ball of Mud. At 4th Conference on Pattern Languages of Programs (PLoP), September 1997. Archived at perma.cc/4GUP-2PBV ↩︎
Marc Brooker. What is a simple system? brooker.co.za, May 2022. Archived at perma.cc/U72T-BFVE ↩︎
Frederick P. Brooks. No Silver Bullet – Essence and Accident in Software Engineering. In The Mythical Man-Month, Anniversary edition, Addison-Wesley, 1995. ISBN: 9780201835953 ↩︎
Dan Luu. Against essential and accidental complexity. danluu.com, December 2020. Archived at perma.cc/H5ES-69KC ↩︎
Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Professional, October 1994. ISBN: 9780201633610 ↩︎
Eric Evans. Domain-Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley Professional, August 2003. ISBN: 9780321125217 ↩︎
Hongyu Pei Breivold, Ivica Crnkovic, and Peter J. Eriksson. Analyzing Software Evolvability. at 32nd Annual IEEE International Computer Software and Applications Conference (COMPSAC), July 2008. doi:10.1109/COMPSAC.2008.50 ↩︎
Enrico Zaninotto. From X programming to the X organisation. At XP Conference, May 2002. Archived at perma.cc/R9AR-QCKZ ↩︎