9. 分布式系统的麻烦
意外这东西挺有意思:你没碰上之前,它就从来不会发生。
A.A. 米尔恩,《小熊维尼和老灰驴的家》(1928)
正如 “可靠性与容错” 中所讨论的,让系统可靠意味着确保系统作为一个整体继续工作,即使出了问题(即出现故障)。然而,预料所有可能的故障并处理它们并不是那么容易。作为开发者,我们很容易主要关注正常路径(毕竟,大多数时候事情都运行良好!)而忽略故障,因为故障会引入大量边界情况。
如果你希望系统在故障存在的情况下仍然可靠,你必须从根本上改变你的思维方式,并专注于可能出错的事情,即使它们可能性很低。一件事情出错的概率是否只有百万分之一并不重要:在一个足够大的系统中,百万分之一的事件每天都在发生。经验丰富的系统操作员会告诉你,任何 可能 出错的事情 都会 出错。
此外,使用分布式系统与在单台计算机上编写软件有着根本的不同 —— 主要区别在于有许多新的、令人兴奋的出错方式 1 2。在本章中,你将体验实践中出现的问题,并理解你可以依赖和不能依赖的事物。
为了理解我们面临的挑战,我们现在将把悲观情绪发挥到极致,探索分布式系统中可能出错的事情。我们将研究网络问题(“不可靠的网络”)以及时钟和时序问题(“不可靠的时钟”)。所有这些问题的后果令人迷惑,因此我们将探索如何思考分布式系统的状态以及如何推理已经发生的事情(“知识、真相与谎言”)。稍后,在 第 10 章 中,我们将看一些面对这些故障时如何实现容错的例子。
故障与部分失效
当你在单台计算机上编写程序时,它通常以相当可预测的方式运行:要么工作,要么不工作。有缺陷的软件可能会给人一种计算机有时 “状态不佳” 的印象(这个问题通常通过重启来解决),但这主要只是编写不良的软件的后果。
软件在单台计算机上不应该是不稳定的,这没有根本原因:当硬件正常工作时,相同的操作总是产生相同的结果(它是 确定性的)。如果存在硬件问题(例如,内存损坏或连接器松动),后果通常是整个系统故障(例如,内核恐慌、“蓝屏死机”、无法启动)。一台运行良好软件的单独计算机通常要么完全正常运行,要么完全故障,而不是介于两者之间。
这是计算机设计中的一个刻意选择:如果发生内部故障,我们宁愿计算机完全崩溃而不是返回错误的结果,因为错误的结果很难处理且令人困惑。因此,计算机隐藏了它们所实现的模糊物理现实,并呈现一个以数学完美运行的理想化系统模型。CPU 指令总是做同样的事情;如果你将一些数据写入内存或磁盘,该数据保持完整,不会被随机损坏。正如 “硬件与软件故障” 中所讨论的,这实际上并不是真的 —— 实际上,数据确实会被静默损坏,CPU 有时会静默返回错误的结果 —— 但这种情况发生得足够少,以至于我们可以忽略它。
当你编写在多台计算机上运行的软件,通过网络连接时,情况就根本不同了。在分布式系统中,故障发生得更加频繁,因此我们不能再忽略它们 —— 我们别无选择,只能直面物理世界的混乱现实。在物理世界中,可能出错的事情范围非常广泛,正如这个轶事所说明的 3:
在我有限的经验中,我处理过单个数据中心(DC)中的长期网络分区、PDU [配电单元] 故障、交换机故障、整个机架的意外断电、整个 DC 骨干网故障、整个 DC 电源故障,以及一个低血糖的司机将他的福特皮卡撞进 DC 的 HVAC [供暖、通风和空调] 系统。而我甚至不是运维人员。
—— Coda Hale
在分布式系统中,系统的某些部分可能以某种不可预测的方式出现故障,即使系统的其他部分工作正常。这被称为 部分失效。困难在于部分失效是 非确定性的:如果你尝试做任何涉及多个节点和网络的事情,它有时可能工作,有时可能不可预测地失败。正如我们将看到的,你甚至可能不 知道 某事是否成功!
这种非确定性和部分失效的可能性使分布式系统难以使用 4。另一方面,如果分布式系统可以容忍部分失效,这将开启强大的可能性:例如,它允许你执行滚动升级,一次重启一个节点以安装软件更新,而系统作为一个整体继续不间断地工作。因此,容错使我们能够从不可靠的组件构建比单节点系统更可靠的分布式系统。
但在我们实现容错之前,我们需要更多地了解我们应该容忍的故障。重要的是要考虑各种可能的故障 —— 即使是相当不太可能的故障 —— 并在你的测试环境中人为地创建这种情况以查看会发生什么。在分布式系统中,怀疑、悲观和偏执是有回报的。
不可靠的网络
正如 “共享内存、共享磁盘和无共享架构” 中所讨论的,我们在本书中关注的分布式系统主要是 无共享系统:即通过网络连接的一组机器。网络是这些机器进行通信的唯一方式 —— 我们假设每台机器都有自己的内存和磁盘,一台机器不能访问另一台机器的内存或磁盘(除非通过网络向服务发出请求)。即使存储是共享的,例如亚马逊的 S3,机器也是通过网络与共享存储服务通信。
互联网和数据中心中的大多数内部网络(通常是以太网)都是 异步分组网络。在这种网络中,一个节点可以向另一个节点发送消息(数据包),但网络不保证它何时到达,或者是否会到达。如果你发送请求并期望响应,许多事情可能会出错(其中一些如 图 9-1 所示):
- 你的请求可能已经丢失(也许有人拔掉了网线)。
- 你的请求可能在队列中等待,稍后将被交付(也许网络或接收方过载)。
- 远程节点可能已经失效(也许它崩溃了或被关闭了)。
- 远程节点可能暂时停止响应(也许它正在经历长时间的垃圾回收暂停;见 “进程暂停”),但稍后会再次开始响应。
- 远程节点可能已经处理了你的请求,但响应在网络上丢失了(也许网络交换机配置错误)。
- 远程节点可能已经处理了你的请求,但响应被延迟了,稍后将被交付(也许网络或你自己的机器过载)。
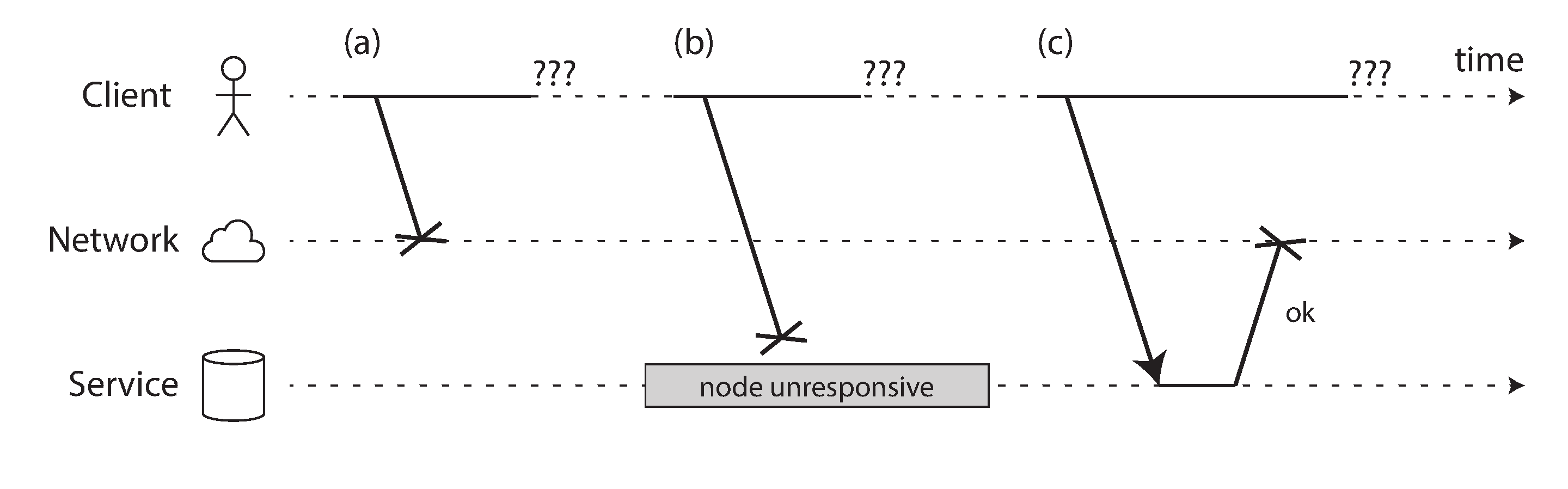
发送方甚至无法判断数据包是否已交付:唯一的选择是让接收方发送响应消息,而响应消息本身也可能丢失或延迟。在异步网络中,这些问题是无法区分的:你拥有的唯一信息是你还没有收到响应。如果你向另一个节点发送请求但没有收到响应,不可能 判断原因。
处理这个问题的常用方法是 超时:在一段时间后,你放弃等待并假设响应不会到达。然而,当超时发生时,你仍然不知道远程节点是否收到了你的请求(如果请求仍在某处排队,即使发送方已经放弃了它,它仍可能被交付给接收方)。
TCP 的局限性
网络数据包有最大大小(通常为几千字节),但许多应用程序需要发送太大而无法装入一个数据包的消息(请求、响应)。这些应用程序最常使用 TCP(传输控制协议)来建立一个 连接,将大型数据流分解为单个数据包,并在接收端将它们重新组合起来。
Note
我们关于 TCP 的大部分内容也适用于其更新的替代方案 QUIC,以及 WebRTC 中使用的流控制传输协议(SCTP)、BitTorrent uTP 协议和其他传输协议。有关与 UDP 的比较,请参见 “TCP 与 UDP”。
TCP 通常被描述为提供 “可靠” 的交付,从某种意义上说,它检测并重传丢弃的数据包,检测重新排序的数据包并将它们恢复到正确的顺序,并使用简单的校验和检测数据包损坏。它还计算出可以发送数据的速度,以便尽快传输数据,但不会使网络或接收节点过载;这被称为 拥塞控制、流量控制 或 背压 5。
当你通过将数据写入套接字来 “发送” 一些数据时,它实际上不会立即发送,而只是放置在由操作系统管理的缓冲区中。当拥塞控制算法决定它有能力发送数据包时,它会从该缓冲区中获取下一个数据包的数据并将其传递给网络接口。数据包通过几个交换机和路由器,最终接收节点的操作系统将数据包的数据放置在接收缓冲区中并向发送方发送确认数据包。只有这样,接收操作系统才会通知应用程序有更多数据到达 6。
那么,如果 TCP 提供 “可靠性”,这是否意味着我们不再需要担心网络不可靠?不幸的是不是。如果在某个超时时间内没有收到确认,它会认为数据包一定已经丢失,但 TCP 也无法判断是出站数据包还是确认丢失了。尽管 TCP 可以重新发送数据包,但它不能保证新数据包也会通过。如果网线被拔掉,TCP 不能为你重新插上它。最终,在可配置的超时后,TCP 放弃并向应用程序发出错误信号。
如果 TCP 连接因错误而关闭 —— 也许是因为远程节点崩溃了,或者是因为网络被中断了 —— 你不幸地无法知道远程节点实际处理了多少数据 6。即使 TCP 确认数据包已交付,这也仅意味着远程节点上的操作系统内核收到了它,但应用程序可能在处理该数据之前就崩溃了。如果你想确保请求成功,你需要应用层返回明确的成功响应 7。
尽管如此,TCP 非常有用,因为它提供了一种方便的方式来发送和接收太大而无法装入一个数据包的消息。一旦建立了 TCP 连接,你还可以使用它来发送多个请求和响应。这通常是通过首先发送一个标头来完成的,该标头以字节为单位指示后续消息的长度,然后是实际消息。HTTP 和许多 RPC 协议(见 “通过服务的数据流:REST 和 RPC”)就是这样工作的。
实践中的网络故障
我们已经建立计算机网络几十年了 —— 人们可能希望到现在我们已经弄清楚如何使它们可靠。不幸的是,我们还没有成功。有一些系统研究和大量轶事证据表明,网络问题可能出人意料地常见,即使在由一家公司运营的受控环境(如数据中心)中也是如此 8:
- 一项在中型数据中心的研究发现,每月约有 12 次网络故障,其中一半断开了单台机器,一半断开了整个机架 9。
- 另一项研究测量了组件(如机架顶部交换机、汇聚交换机和负载均衡器)的故障率 10。它发现,添加冗余网络设备并不能像你希望的那样减少故障,因为它不能防范人为错误(例如,配置错误的交换机),这是停机的主要原因。
- 广域光纤链路的中断被归咎于奶牛 11、海狸 12 和鲨鱼 13(尽管由于海底电缆屏蔽更好,鲨鱼咬伤已经变得更加罕见 14)。人类也有过错,无论是由于意外配置错误 15、拾荒 16 还是破坏 17。
- 在不同的云区域之间,已经观察到高百分位数下长达几 分钟 的往返时间 18。即使在单个数据中心内,在网络拓扑重新配置期间(由交换机软件升级期间的问题触发),也可能发生超过一分钟的数据包延迟 19。因此,我们必须假设消息可能被任意延迟。
- 有时通信部分中断,这取决于你在和谁交谈:例如,A 和 B 可以通信,B 和 C 可以通信,但 A 和 C 不能 20 21。其他令人惊讶的故障包括网络接口有时会丢弃所有入站数据包但成功发送出站数据包 22:仅仅因为网络链路在一个方向上工作并不能保证它在相反方向上也工作。
- 即使是短暂的网络中断也可能产生比原始问题持续时间更长的影响 8 20 23。
网络分区
当网络的一部分由于网络故障而与其余部分隔离时,有时称为 网络分区 或 网络分裂,但它与其他类型的网络中断没有根本区别。网络分区与存储系统的分片无关,后者有时也称为 分区(见 第 7 章)。
即使网络故障在你的环境中很少见,故障 可能 发生的事实意味着你的软件需要能够处理它们。每当通过网络进行任何通信时,它都可能失败 —— 这是无法避免的。
如果网络故障的错误处理没有定义和测试,可能会发生任意糟糕的事情:例如,集群可能会陷入死锁并永久无法提供请求,即使网络恢复 24,或者它甚至可能删除你的所有数据 25。如果软件处于意料之外的情况,它可能会做任意意外的事情。
处理网络故障不一定意味着 容忍 它们:如果你的网络通常相当可靠,一个有效的方法可能是在网络出现问题时简单地向用户显示错误消息。但是,你确实需要知道你的软件如何对网络问题做出反应,并确保系统可以从中恢复。故意触发网络问题并测试系统的响应可能是有意义的(这被称为 故障注入;见 “故障注入”)。
检测故障
许多系统需要自动检测故障节点。例如:
- 负载均衡器需要停止向已死亡的节点发送请求(即,将其 从轮询池中摘除)。
- 在具有单主复制的分布式数据库中,如果主节点失效,其中一个从节点需要被提升为新的主节点(见 “处理节点中断”)。
不幸的是,网络的不确定性使得很难判断节点是否正常工作。在某些特定情况下,你可能会得到一些明确告诉你某事不工作的反馈:
- 如果你可以访问节点应该运行的机器,但没有进程监听目标端口(例如,因为进程崩溃了),操作系统将通过发送
RST或FIN数据包来帮助关闭或拒绝 TCP 连接。 - 如果节点进程崩溃(或被管理员杀死)但节点的操作系统仍在运行,脚本可以通知其他节点有关崩溃的信息,以便另一个节点可以快速接管而无需等待超时到期。例如,HBase 就是这样做的 26。
- 如果你可以访问数据中心中网络交换机的管理接口,你可以查询它们以在硬件级别检测链路故障(例如,如果远程机器已关闭电源)。如果你通过互联网连接,或者你在共享数据中心中无法访问交换机本身,或者由于网络问题无法访问管理接口,则此选项被排除。
- 如果路由器确定你尝试连接的 IP 地址不可达,它可能会向你回复 ICMP 目标不可达数据包。然而,路由器也没有神奇的故障检测能力 —— 它受到与网络其他参与者相同的限制。
关于远程节点宕机的快速反馈很有用,但你不能指望它。如果出了问题,你可能会在堆栈的某个级别收到错误响应,但通常你必须假设你根本不会收到任何响应。你可以重试几次,等待超时过去,如果在超时内没有收到回复,最终宣布节点死亡。
超时和无界延迟
如果超时是检测故障的唯一可靠方法,那么超时应该多长?不幸的是,没有简单的答案。
长超时意味着在节点被宣布死亡之前需要长时间等待(在此期间,用户可能不得不等待或看到错误消息)。短超时可以更快地检测故障,但当节点实际上只是遭受暂时的减速(例如,由于节点或网络上的负载峰值)时,错误地宣布节点死亡的风险更高。
过早地宣布节点死亡是有问题的:如果节点实际上是活着的并且正在执行某些操作(例如,发送电子邮件),而另一个节点接管,该操作可能最终被执行两次。我们将在 “知识、真相与谎言” 以及第 10 章和后续章节中更详细地讨论这个问题。
当节点被宣布死亡时,其职责需要转移到其他节点,这会给其他节点和网络带来额外的负载。如果系统已经在高负载下挣扎,过早地宣布节点死亡可能会使问题变得更糟。特别是,可能发生的情况是,节点实际上并没有死亡,只是由于过载而响应缓慢;将其负载转移到其他节点可能会导致级联故障(在极端情况下,所有节点互相宣布对方死亡,一切都停止工作 —— 见 “当过载系统无法恢复时”)。
想象一个虚构的系统,其网络保证数据包的最大延迟 —— 每个数据包要么在某个时间 d 内交付,要么丢失,但交付从不会超过 d。此外,假设你可以保证未失效的节点总是在某个时间 r 内处理请求。在这种情况下,你可以保证每个成功的请求在时间 2d + r 内收到响应 —— 如果你在该时间内没有收到响应,你就知道网络或远程节点不工作。如果这是真的,2d + r 将是一个合理的超时时间。
不幸的是,我们使用的大多数系统都没有这些保证:异步网络具有 无界延迟(即,它们尝试尽快交付数据包,但数据包到达所需的时间没有上限),大多数服务器实现无法保证它们可以在某个最大时间内处理请求(见 “响应时间保证”)。对于故障检测,系统大部分时间快速运行是不够的:如果你的超时很低,往返时间的瞬时峰值就足以使系统失去平衡。
网络拥塞和排队
开车时,道路网络上的行驶时间通常因交通拥堵而变化最大。同样,计算机网络上数据包延迟的可变性最常是由于排队 27:
- 如果几个不同的节点同时尝试向同一目的地发送数据包,网络交换机必须将它们排队并逐个送入目标网络链路(如 图 9-2 所示)。在繁忙的网络链路上,数据包可能需要等待一段时间才能获得一个插槽(这称为 网络拥塞)。如果有太多的传入数据以至于交换机队列满了,数据包将被丢弃,因此需要重新发送 —— 即使网络运行正常。
- 当数据包到达目标机器时,如果所有 CPU 核心当前都很忙,来自网络的传入请求会被操作系统排队,直到应用程序准备处理它。根据机器上的负载,这可能需要任意长的时间 28。
- 在虚拟化环境中,正在运行的操作系统经常会暂停几十毫秒,而另一个虚拟机使用 CPU 核心。在此期间,VM 无法消耗来自网络的任何数据,因此传入数据由虚拟机监视器排队(缓冲)29,进一步增加了网络延迟的可变性。
- 如前所述,为了避免网络过载,TCP 限制发送数据的速率。这意味着在数据甚至进入网络之前,发送方就有额外的排队。
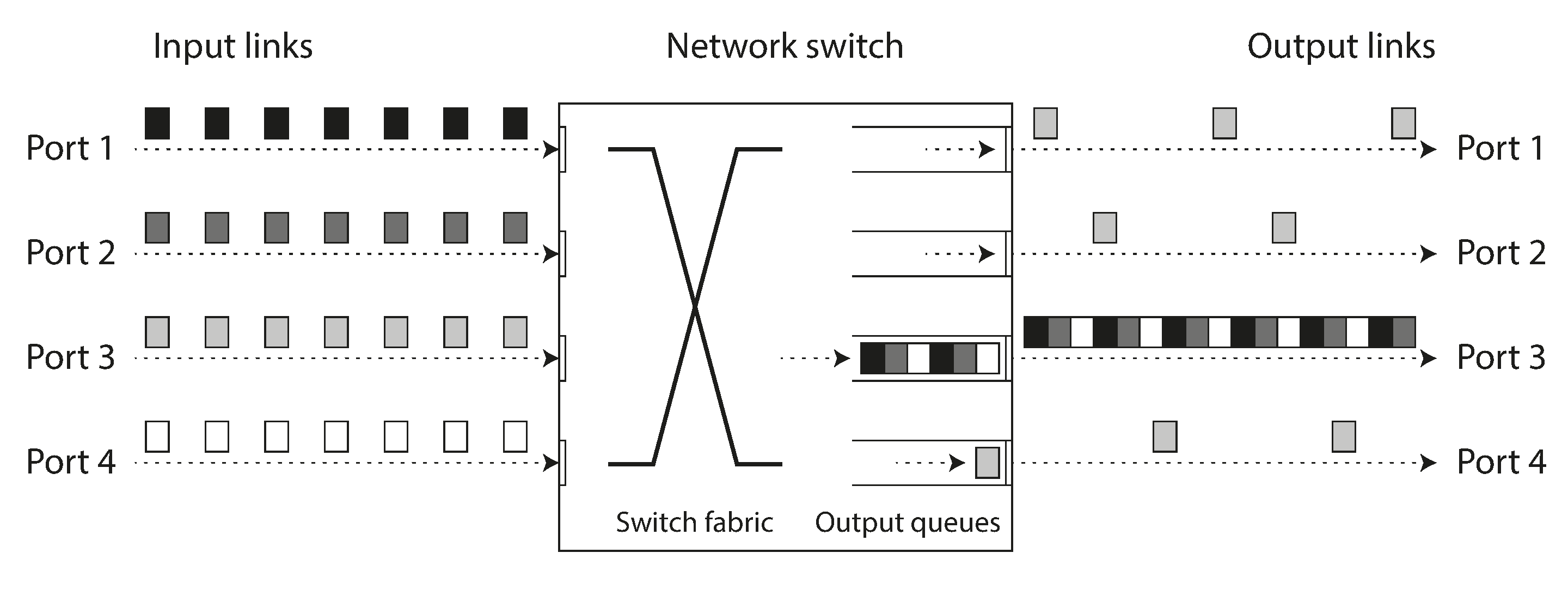
此外,当 TCP 检测到并自动重传丢失的数据包时,尽管应用程序不会直接看到数据包丢失,但它确实会看到由此产生的延迟(等待超时到期,然后等待重传的数据包被确认)。
TCP 与 UDP
一些对延迟敏感的应用程序,如视频会议和 IP 语音(VoIP),使用 UDP 而不是 TCP。这是可靠性和延迟可变性之间的权衡:由于 UDP 不执行流量控制并且不重传丢失的数据包,它避免了网络延迟可变的一些原因(尽管它仍然容易受到交换机队列和调度延迟的影响)。
UDP 是延迟数据无价值的情况下的好选择。例如,在 VoIP 电话通话中,在数据应该通过扬声器播放之前,可能没有足够的时间重传丢失的数据包。在这种情况下,重传数据包没有意义 —— 应用程序必须用静音填充缺失数据包的时间槽(导致声音短暂中断)并继续流。重试发生在人类层面。(“你能重复一下吗?声音刚刚中断了一会儿。")
所有这些因素都导致了网络延迟的可变性。当系统接近其最大容量时,排队延迟的范围特别大:具有充足备用容量的系统可以轻松排空队列,而在高度利用的系统中,长队列可以很快建立起来。
在公共云和多租户数据中心中,资源在许多客户之间共享:网络链路和交换机,甚至每台机器的网络接口和 CPU(在虚拟机上运行时)都是共享的。处理大量数据可以使用网络链路的全部容量(饱和 它们)。由于你无法控制或了解其他客户对共享资源的使用情况,如果你附近的某人(吵闹的邻居)正在使用大量资源,网络延迟可能会高度可变 30 31。
在这种环境中,你只能通过实验选择超时:在较长时间内和许多机器上测量网络往返时间的分布,以确定延迟的预期可变性。然后,考虑到你的应用程序的特征,你可以在故障检测延迟和过早超时风险之间确定适当的权衡。
更好的是,系统可以持续测量响应时间及其可变性(抖动),并根据观察到的响应时间分布自动调整超时,而不是使用配置的常量超时。Phi 累积故障检测器 32(例如在 Akka 和 Cassandra 中使用 33)就是这样做的一种方法。TCP 重传超时也以类似的方式工作 5。
同步与异步网络
如果我们可以依靠网络以某个固定的最大延迟交付数据包,并且不丢弃数据包,分布式系统将会简单得多。为什么我们不能在硬件级别解决这个问题,使网络可靠,这样软件就不需要担心它了?
要回答这个问题,比较数据中心网络与传统的固定电话网络(非蜂窝、非 VoIP)很有趣,后者极其可靠:延迟的音频帧和掉线非常罕见。电话通话需要持续的低端到端延迟和足够的带宽来传输你声音的音频样本。在计算机网络中拥有类似的可靠性和可预测性不是很好吗?
当你通过电话网络拨打电话时,它会建立一个 电路:在两个呼叫者之间的整个路线上分配固定、有保证的带宽量。该电路一直保持到通话结束 34。例如,ISDN 网络以每秒 4,000 帧的固定速率运行。建立呼叫时,它在每帧内(在每个方向上)分配 16 位空间。因此,在通话期间,每一方都保证能够每 250 微秒准确发送 16 位音频数据 35。
这种网络是 同步的:即使数据通过几个路由器,它也不会遭受排队,因为呼叫的 16 位空间已经在网络的下一跳中预留了。由于没有排队,网络的最大端到端延迟是固定的。我们称之为 有界延迟。
我们不能简单地使网络延迟可预测吗?
请注意,电话网络中的电路与 TCP 连接非常不同:电路是固定数量的预留带宽,在电路建立期间其他人无法使用,而 TCP 连接的数据包则机会主义地使用任何可用的网络带宽。你可以给 TCP 一个可变大小的数据块(例如,电子邮件或网页),它会尝试在尽可能短的时间内传输它。当 TCP 连接空闲时,它不使用任何带宽(除了偶尔的保活数据包)。
如果数据中心网络和互联网是电路交换网络,那么在建立电路时就可以建立有保证的最大往返时间。然而,它们不是:以太网和 IP 是分组交换协议,会遭受排队,因此在网络中有无界延迟。这些协议没有电路的概念。
为什么数据中心网络和互联网使用分组交换?答案是它们针对 突发流量 进行了优化。电路适合音频或视频通话,需要在通话期间传输相当恒定的每秒位数。另一方面,请求网页、发送电子邮件或传输文件没有任何特定的带宽要求 —— 我们只希望它尽快完成。
如果你想通过电路传输文件,你必须猜测带宽分配。如果你猜得太低,传输会不必要地慢,使网络容量未被使用。如果你猜得太高,电路无法建立(因为如果无法保证其带宽分配,网络无法允许创建电路)。因此,使用电路进行突发数据传输会浪费网络容量并使传输不必要地缓慢。相比之下,TCP 动态调整数据传输速率以适应可用的网络容量。
曾经有一些尝试构建既支持电路交换又支持分组交换的混合网络。异步传输模式(ATM)在 1980 年代是以太网的竞争对手,但除了电话网络核心交换机外,它没有获得太多采用。InfiniBand 有一些相似之处 36:它在链路层实现端到端流量控制,减少了网络中排队的需要,尽管它仍然可能因链路拥塞而遭受延迟 37。通过仔细使用 服务质量(QoS,数据包的优先级和调度)和 准入控制(对发送者的速率限制),可以在分组网络上模拟电路交换,或提供统计上有界的延迟 27 34。新的网络算法,如低延迟、低损耗和可扩展吞吐量(L4S)试图在客户端和路由器级别缓解一些排队和拥塞控制问题。Linux 的流量控制器(TC)也允许应用程序为 QoS 目的重新优先排序数据包。
延迟和资源利用率
更一般地说,你可以将可变延迟视为动态资源分区的结果。
假设你在两个电话交换机之间有一条可以承载多达 10,000 个同时呼叫的线路。通过此线路交换的每个电路都占用其中一个呼叫插槽。因此,你可以将该线路视为最多可由 10,000 个同时用户共享的资源。资源以 静态 方式划分:即使你现在是线路上唯一的呼叫,并且所有其他 9,999 个插槽都未使用,你的电路仍然分配与线路完全利用时相同的固定带宽量。
相比之下,互联网 动态 共享网络带宽。发送者互相推挤,尽可能快地通过线路发送数据包,网络交换机决定在每个时刻发送哪个数据包(即带宽分配)。这种方法的缺点是排队,但优点是它最大化了线路的利用率。线路有固定成本,所以如果你更好地利用它,你通过线路发送的每个字节都更便宜。
CPU 也会出现类似的情况:如果你在几个线程之间动态共享每个 CPU 核心,一个线程有时必须在操作系统的运行队列中等待,而另一个线程正在运行,因此线程可能会暂停不同的时间长度 38。然而,这比为每个线程分配静态数量的 CPU 周期更好地利用硬件(见 “响应时间保证”)。更好的硬件利用率也是云平台在同一物理机器上运行来自不同客户的多个虚拟机的原因。
如果资源是静态分区的(例如,专用硬件和独占带宽分配),则在某些环境中可以实现延迟保证。然而,这是以降低利用率为代价的 —— 换句话说,它更昂贵。另一方面,具有动态资源分区的多租户提供了更好的利用率,因此更便宜,但它有可变延迟的缺点。
网络中的可变延迟不是自然法则,而只是成本/收益权衡的结果。
然而,这种服务质量目前在多租户数据中心和公共云中未启用,或者在通过互联网通信时未启用。当前部署的技术不允许我们对网络的延迟或可靠性做出任何保证:我们必须假设网络拥塞、排队和无界延迟会发生。因此,超时没有 “正确” 的值 —— 它们需要通过实验确定。
互联网服务提供商之间的对等协议和通过边界网关协议(BGP)建立路由,比 IP 本身更接近电路交换。在这个级别,可以购买专用带宽。然而,互联网路由在网络级别而不是主机之间的单个连接上运行,并且时间尺度要长得多。
不可靠的时钟
时钟和时间很重要。应用程序以各种方式依赖时钟来回答如下问题:
- 这个请求超时了吗?
- 这项服务的第 99 百分位响应时间是多少?
- 这项服务在过去五分钟内平均每秒处理了多少查询?
- 用户在我们的网站上花了多长时间?
- 这篇文章是什么时候发表的?
- 提醒邮件应该在什么日期和时间发送?
- 这个缓存条目何时过期?
- 日志文件中此错误消息的时间戳是什么?
示例 1-4 测量 持续时间(例如,发送请求和接收响应之间的时间间隔),而示例 5-8 描述 时间点(在特定日期、特定时间发生的事件)。
在分布式系统中,时间是一件棘手的事情,因为通信不是瞬时的:消息从一台机器通过网络传输到另一台机器需要时间。接收消息的时间总是晚于发送消息的时间,但由于网络中的可变延迟,我们不知道晚了多少。当涉及多台机器时,这个事实有时会使确定事情发生的顺序变得困难。
此外,网络上的每台机器都有自己的时钟,这是一个实际的硬件设备:通常是石英晶体振荡器。这些设备并不完全准确,因此每台机器都有自己的时间概念,可能比其他机器稍快或稍慢。可以在某种程度上同步时钟:最常用的机制是网络时间协议(NTP),它允许根据一组服务器报告的时间调整计算机时钟 39。服务器反过来从更准确的时间源(如 GPS 接收器)获取时间。
单调时钟与日历时钟
现代计算机至少有两种不同类型的时钟:日历时钟 和 单调时钟。尽管它们都测量时间,但区分两者很重要,因为它们服务于不同的目的。
日历时钟
日历时钟做你直观期望时钟做的事情:它根据某个日历返回当前日期和时间(也称为 墙上时钟时间)。例如,Linux 上的 clock_gettime(CLOCK_REALTIME) 和 Java 中的 System.currentTimeMillis() 返回自 纪元 以来的秒数(或毫秒数):根据格里高利历,1970 年 1 月 1 日午夜 UTC,不计算闰秒。一些系统使用其他日期作为参考点。(尽管 Linux 时钟被称为 实时,但它与实时操作系统无关,如 “响应时间保证” 中所讨论的。)
日历时钟通常与 NTP 同步,这意味着来自一台机器的时间戳(理想情况下)与另一台机器上的时间戳意思相同。然而,日历时钟也有各种奇怪之处,如下一节所述。特别是,如果本地时钟远远超前于 NTP 服务器,它可能会被强制重置并显示跳回到以前的时间点。这些跳跃,以及闰秒引起的类似跳跃,使日历时钟不适合测量经过的时间 40。
日历时钟可能会因夏令时(DST)的开始和结束而经历跳跃;这些可以通过始终使用 UTC 作为时区来避免,UTC 没有 DST。日历时钟在历史上也具有相当粗粒度的分辨率,例如,在较旧的 Windows 系统上以 10 毫秒的步长前进 41。在最近的系统上,这不再是一个问题。
单调时钟
单调时钟适用于测量持续时间(时间间隔),例如超时或服务的响应时间:例如,Linux 上的 clock_gettime(CLOCK_MONOTONIC) 或 clock_gettime(CLOCK_BOOTTIME) 42 和 Java 中的 System.nanoTime() 是单调时钟。这个名字来源于它们保证始终向前移动的事实(而日历时钟可能会在时间上向后跳跃)。
你可以在某个时间点检查单调时钟的值,做一些事情,然后在稍后的时间再次检查时钟。两个值之间的 差值 告诉你两次检查之间经过了多少时间 —— 更像秒表而不是挂钟。然而,时钟的 绝对 值是没有意义的:它可能是自计算机启动以来的纳秒数,或类似的任意值。特别是,比较来自两台不同计算机的单调时钟值是没有意义的,因为它们不代表同样的东西。
在具有多个 CPU 插槽的服务器上,每个 CPU 可能有一个单独的计时器,它不一定与其他 CPU 同步 43。操作系统会补偿任何差异,并尝试向应用程序线程呈现时钟的单调视图,即使它们被调度到不同的 CPU 上。然而,明智的做法是对这种单调性保证持保留态度 44。
如果 NTP 检测到计算机的本地石英晶体比 NTP 服务器运行得更快或更慢,它可能会调整单调时钟前进的频率(这被称为 调整 时钟)。默认情况下,NTP 允许时钟速率加速或减速高达 0.05%,但 NTP 不能导致单调时钟向前或向后跳跃。单调时钟的分辨率通常相当好:在大多数系统上,它们可以测量微秒或更短的时间间隔。
在分布式系统中,使用单调时钟测量经过的时间(例如,超时)通常是可以的,因为它不假设不同节点的时钟之间有任何同步,并且对测量的轻微不准确不敏感。
时钟同步和准确性
单调时钟不需要同步,但日历时钟需要根据 NTP 服务器或其他外部时间源设置才能有用。不幸的是,我们让时钟显示正确时间的方法远不如你希望的那样可靠或准确 —— 硬件时钟和 NTP 可能是反复无常的野兽。仅举几个例子:
- 计算机中的石英时钟不是很准确:它会 漂移(比应该的运行得更快或更慢)。时钟漂移因机器的温度而异。Google 假设其服务器的时钟漂移高达 200 ppm(百万分之一)45,这相当于每 30 秒与服务器重新同步的时钟有 6 毫秒漂移,或每天重新同步一次的时钟有 17 秒漂移。即使一切正常工作,这种漂移也限制了你可以达到的最佳精度。
- 如果计算机的时钟与 NTP 服务器相差太多,它可能会拒绝同步,或者本地时钟将被强制重置 39。任何在重置前后观察时间的应用程序都可能看到时间倒退或突然向前跳跃。
- 如果节点意外地被防火墙与 NTP 服务器隔离,配置错误可能会在一段时间内未被注意到,在此期间漂移可能会累积成不同节点时钟之间的巨大差异。轶事证据表明,这在实践中确实会发生。
- NTP 同步只能与网络延迟一样好,因此当你在具有可变数据包延迟的拥塞网络上时,其准确性有限。一项实验表明,通过互联网同步时可以达到 35 毫秒的最小误差 46,尽管网络延迟的偶尔峰值会导致大约一秒的误差。根据配置,大的网络延迟可能导致 NTP 客户端完全放弃。
- 一些 NTP 服务器是错误的或配置错误的,报告的时间相差数小时 47 48。NTP 客户端通过查询多个服务器并忽略异常值来减轻此类错误。尽管如此,将系统的正确性押注在互联网上陌生人告诉你的时间上还是有些令人担忧的。
- 闰秒导致一分钟有 59 秒或 61 秒长,这会搞乱在设计时没有考虑闰秒的系统中的时序假设 49。闰秒已经导致许多大型系统崩溃的事实 40 50 表明,关于时钟的错误假设是多么容易潜入系统。处理闰秒的最佳方法可能是让 NTP 服务器 “撒谎”,通过在一天的过程中逐渐执行闰秒调整(这被称为 平滑)51 52,尽管实际的 NTP 服务器行为在实践中有所不同 53。从 2035 年起将不再使用闰秒,所以这个问题幸运地将会消失。
- 在虚拟机中,硬件时钟是虚拟化的,这为需要准确计时的应用程序带来了额外的挑战 54。当 CPU 核心在虚拟机之间共享时,每个 VM 在另一个 VM 运行时会暂停数十毫秒。从应用程序的角度来看,这种暂停表现为时钟突然向前跳跃 29。如果 VM 暂停几秒钟,时钟可能会比实际时间落后几秒钟,但 NTP 可能会继续报告时钟几乎完全同步 55。
- 如果你在不完全控制的设备上运行软件(例如,移动或嵌入式设备),你可能根本无法信任设备的硬件时钟。一些用户故意将他们的硬件时钟设置为不正确的日期和时间,例如在游戏中作弊 56。因此,时钟可能被设置为遥远的过去或未来的时间。
如果你足够关心时钟精度并愿意投入大量资源,就可以实现非常好的时钟精度。例如,欧洲金融机构的 MiFID II 法规要求所有高频交易基金将其时钟同步到 UTC 的 100 微秒以内,以帮助调试市场异常(如 “闪崩”)并帮助检测市场操纵 57。
这种精度可以通过一些特殊硬件(GPS 接收器和/或原子钟)、精确时间协议(PTP)以及仔细的部署和监控来实现 58 59。仅依赖 GPS 可能有风险,因为 GPS 信号很容易被干扰。在某些地方,这种情况经常发生,例如靠近军事设施 60。一些云提供商已经开始为其虚拟机提供高精度时钟同步 61。然而,时钟同步仍然需要很多注意。如果你的 NTP 守护进程配置错误,或者防火墙阻止了 NTP 流量,由于漂移导致的时钟误差可能会迅速变大。
对同步时钟的依赖
时钟的问题在于,虽然它们看起来简单易用,但它们有惊人数量的陷阱:一天可能没有正好 86,400 秒,日历时钟可能会在时间上向后移动,根据一个节点的时钟的时间可能与另一个节点的时钟相差很大。
本章前面我们讨论了网络丢弃和任意延迟数据包。即使网络大部分时间表现良好,软件也必须设计成假设网络偶尔会出现故障,软件必须优雅地处理此类故障。时钟也是如此:尽管它们大部分时间工作得很好,但强健的软件需要准备好处理不正确的时钟。
问题的一部分是不正确的时钟很容易被忽视。如果机器的 CPU 有缺陷或其网络配置错误,它很可能根本无法工作,因此会很快被注意到并修复。另一方面,如果它的石英时钟有缺陷或其 NTP 客户端配置错误,大多数事情看起来会正常工作,即使它的时钟逐渐偏离现实越来越远。如果某些软件依赖于准确同步的时钟,结果更可能是静默和微妙的数据丢失,而不是戏剧性的崩溃 62 63。
因此,如果你使用需要同步时钟的软件,你还必须仔细监控所有机器之间的时钟偏移。任何时钟偏离其他节点太远的节点都应该被宣布死亡并从集群中移除。这种监控确保你在损坏的时钟造成太多损害之前注意到它们。
用于事件排序的时间戳
让我们考虑一个特定的情况,其中依赖时钟是诱人但危险的:跨多个节点的事件排序 64。例如,如果两个客户端写入分布式数据库,谁先到达?哪个写入是更新的?
图 9-3 说明了在具有多主复制的数据库中日历时钟的危险使用(该示例类似于 图 6-8)。客户端 A 在节点 1 上写入 x = 1;写入被复制到节点 3;客户端 B 在节点 3 上递增 x(我们现在有 x = 2);最后,两个写入都被复制到节点 2。
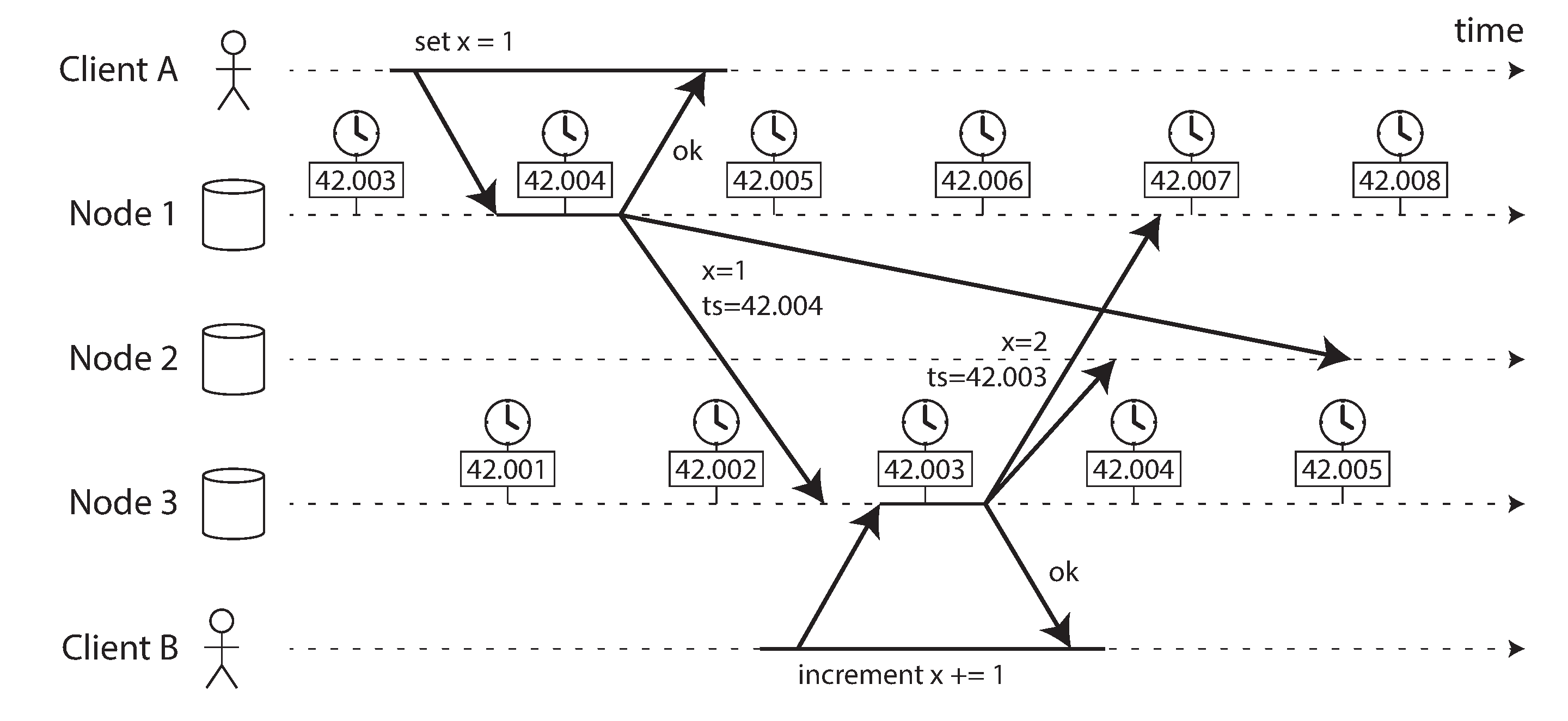
在 图 9-3 中,当写入被复制到其他节点时,它会根据写入起源节点上的日历时钟标记时间戳。此示例中的时钟同步非常好:节点 1 和节点 3 之间的偏差小于 3 毫秒,这可能比你在实践中可以期望的要好。
由于递增建立在 x = 1 的早期写入之上,我们可能期望 x = 2 的写入应该具有两者中更大的时间戳。不幸的是,图 9-3 中发生的并非如此:写入 x = 1 的时间戳为 42.004 秒,但写入 x = 2 的时间戳为 42.003 秒。
如 “最后写入胜利(丢弃并发写入)” 中所讨论的,解决不同节点上并发写入值之间冲突的一种方法是 最后写入胜利(LWW),这意味着保留给定键的具有最大时间戳的写入,并丢弃所有具有较旧时间戳的写入。在 图 9-3 的示例中,当节点 2 接收这两个事件时,它将错误地得出结论,认为 x = 1 是更新的值并丢弃写入 x = 2,因此递增丢失了。
可以通过确保当值被覆盖时,新值总是具有比被覆盖值更高的时间戳来防止这个问题,即使该时间戳超前于写入者的本地时钟。然而,这会产生额外的读取成本来查找最大的现有时间戳。一些系统,包括 Cassandra 和 ScyllaDB,希望在单次往返中写入所有副本,因此它们只是使用客户端时钟的时间戳以及最后写入胜利策略 62。这种方法有一些严重的问题:
- 数据库写入可能会神秘地消失:具有滞后时钟的节点无法覆盖先前由具有快速时钟的节点写入的值,直到节点之间的时钟偏差时间过去 63 65。这种情况可能导致任意数量的数据被静默丢弃,而不会向应用程序报告任何错误。
- LWW 无法区分快速连续发生的顺序写入(在 图 9-3 中,客户端 B 的递增肯定发生在客户端 A 的写入 之后)和真正并发的写入(两个写入者都不知道对方)。需要额外的因果关系跟踪机制,如版本向量,以防止违反因果关系(见 “检测并发写入”)。
- 两个节点可能独立生成具有相同时间戳的写入,特别是当时钟只有毫秒分辨率时。需要额外的决胜值(可以简单地是一个大的随机数)来解决此类冲突,但这种方法也可能导致违反因果关系 62。
因此,即使通过保留最 “新” 的值并丢弃其他值来解决冲突很诱人,但重要的是要意识到 “新” 的定义取决于本地日历时钟,它很可能是不正确的。即使使用紧密 NTP 同步的时钟,你也可能在时间戳 100 毫秒(根据发送者的时钟)发送数据包,并让它在时间戳 99 毫秒(根据接收者的时钟)到达 —— 因此看起来数据包在发送之前就到达了,这是不可能的。
NTP 同步能否足够准确以至于不会发生此类错误排序?可能不行,因为除了石英漂移等其他误差源之外,NTP 的同步精度本身受到网络往返时间的限制。要保证正确的排序,你需要时钟误差显著低于网络延迟,这是不可能的。
所谓的 逻辑时钟 66,基于递增计数器而不是振荡石英晶体,是排序事件的更安全替代方案(见 “检测并发写入”)。逻辑时钟不测量一天中的时间或经过的秒数,只测量事件的相对顺序(一个事件是在另一个事件之前还是之后发生)。相比之下,日历时钟和单调时钟测量实际经过的时间,也称为 物理时钟。我们将在 “ID 生成器和逻辑时钟” 中更详细地研究逻辑时钟。
带置信区间的时钟读数
你可能能够以微秒甚至纳秒分辨率读取机器的日历时钟。但即使你能获得如此细粒度的测量,也不意味着该值实际上精确到如此精度。事实上,它很可能不是 —— 如前所述,即使你每分钟与本地网络上的 NTP 服务器同步,不精确的石英时钟的漂移也很容易达到几毫秒。使用公共互联网上的 NTP 服务器,最佳可能精度可能是几十毫秒,当存在网络拥塞时,误差很容易超过 100 毫秒。
因此,将时钟读数视为时间点是没有意义的 —— 它更像是一个时间范围,在置信区间内:例如,系统可能有 95% 的信心认为现在的时间在分钟后的 10.3 到 10.5 秒之间,但它不知道比这更精确的时间 67。如果我们只知道时间 +/- 100 毫秒,时间戳中的微秒数字基本上是没有意义的。
不确定性边界可以根据你的时间源计算。如果你有直接连接到计算机的 GPS 接收器或原子钟,预期误差范围由设备决定,对于 GPS,由来自卫星的信号质量决定。如果你从服务器获取时间,不确定性基于自上次与服务器同步以来的预期石英漂移,加上 NTP 服务器的不确定性,加上到服务器的网络往返时间(作为第一近似,并假设你信任服务器)。
不幸的是,大多数系统不暴露这种不确定性:例如,当你调用 clock_gettime() 时,返回值不会告诉你时间戳的预期误差,所以你不知道它的置信区间是五毫秒还是五年。
有例外:Google Spanner 中的 TrueTime API 45 和亚马逊的 ClockBound 明确报告本地时钟的置信区间。当你询问当前时间时,你会得到两个值:[earliest, latest],它们是 最早可能 和 最晚可能 的时间戳。基于其不确定性计算,时钟知道实际当前时间在该区间内的某处。区间的宽度取决于多种因素,包括本地石英时钟上次与更准确的时钟源同步以来已经过去了多长时间。
用于全局快照的同步时钟
在 “快照隔离和可重复读” 中,我们讨论了 多版本并发控制(MVCC),这是数据库中非常有用的功能,需要支持小型、快速的读写事务和大型、长时间运行的只读事务(例如,用于备份或分析)。它允许只读事务看到数据库的 快照,即特定时间点的一致状态,而不会锁定和干扰读写事务。
通常,MVCC 需要单调递增的事务 ID。如果写入发生在快照之后(即,写入的事务 ID 大于快照),则该写入对快照事务不可见。在单节点数据库上,简单的计数器就足以生成事务 ID。
然而,当数据库分布在许多机器上,可能在多个数据中心时,全局单调递增的事务 ID(跨所有分片)很难生成,因为它需要协调。事务 ID 必须反映因果关系:如果事务 B 读取或覆盖先前由事务 A 写入的值,则 B 必须具有比 A 更高的事务 ID —— 否则,快照将不一致。对于大量小型、快速的事务,在分布式系统中创建事务 ID 成为难以承受的瓶颈。(我们将在 “ID 生成器和逻辑时钟” 中讨论此类 ID 生成器。)
我们能否使用同步日历时钟的时间戳作为事务 ID?如果我们能够获得足够好的同步,它们将具有正确的属性:较晚的事务具有更高的时间戳。当然,问题是时钟精度的不确定性。
Spanner 以这种方式跨数据中心实现快照隔离 68 69。它使用 TrueTime API 报告的时钟置信区间,并基于以下观察:如果你有两个置信区间,每个都由最早和最晚可能的时间戳组成(A = [A最早, A最晚] 和 B = [B最早, B最晚]),并且这两个区间不重叠(即,A最早 < A最晚 < B最早 < B最晚),那么 B 肯定发生在 A 之后 —— 毫无疑问。只有当区间重叠时,我们才不确定 A 和 B 发生的顺序。
为了确保事务时间戳反映因果关系,Spanner 在提交读写事务之前故意等待置信区间的长度。通过这样做,它确保任何可能读取数据的事务都在足够晚的时间,因此它们的置信区间不会重叠。为了使等待时间尽可能短,Spanner 需要使时钟不确定性尽可能小;为此,Google 在每个数据中心部署 GPS 接收器或原子钟,使时钟能够同步到大约 7 毫秒以内 45。
原子钟和 GPS 接收器在 Spanner 中并不是严格必要的:重要的是要有一个置信区间,准确的时钟源只是帮助保持该区间较小。其他系统开始采用类似的方法:例如,YugabyteDB 在 AWS 上运行时可以利用 ClockBound 70,其他几个系统现在也在不同程度上依赖时钟同步 71 72。
进程暂停
让我们考虑分布式系统中危险使用时钟的另一个例子。假设你有一个每个分片都有单个主节点的数据库。只有主节点被允许接受写入。节点如何知道它仍然是主节点(它没有被其他节点宣布死亡),并且它可以安全地接受写入?
一种选择是让主节点从其他节点获取 租约,这类似于带有超时的锁 73。任何时候只有一个节点可以持有租约 —— 因此,当节点获得租约时,它知道在租约到期之前的一段时间内它是主节点。为了保持主节点身份,节点必须在租约到期之前定期续订租约。如果节点失效,它会停止续订租约,因此另一个节点可以在租约到期时接管。
你可以想象请求处理循环看起来像这样:
while (true) {
request = getIncomingRequest();
// 确保租约始终至少有 10 秒的剩余时间
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000) {
lease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
}这段代码有什么问题?首先,它依赖于同步时钟:租约的到期时间由不同的机器设置(到期时间可能计算为当前时间加 30 秒,例如),并且它与本地系统时钟进行比较。如果时钟相差超过几秒钟,这段代码将开始做奇怪的事情。
其次,即使我们更改协议以仅使用本地单调时钟,还有另一个问题:代码假设在检查时间(System.currentTimeMillis())和处理请求(process(request))之间经过的时间非常少。通常这段代码运行得非常快,所以 10 秒的缓冲时间足以确保租约不会在处理请求的过程中到期。
然而,如果程序执行中出现意外暂停会怎样?例如,想象线程在 lease.isValid() 行周围停止了 15 秒,然后才最终继续。在这种情况下,处理请求时租约很可能已经到期,另一个节点已经接管了主节点身份。然而,没有任何东西告诉这个线程它暂停了这么长时间,所以这段代码不会注意到租约已经到期,直到循环的下一次迭代 —— 到那时它可能已经通过处理请求做了一些不安全的事情。
假设线程可能暂停这么长时间是合理的吗?不幸的是,是的。有各种原因可能导致这种情况发生:
- 线程访问共享资源(如锁或队列)时的争用可能导致线程花费大量时间等待。转移到具有更多 CPU 核心的机器可能会使此类问题变得更糟,并且争用问题可能难以诊断 74。
- 许多编程语言运行时(如 Java 虚拟机)有 垃圾回收器(GC),偶尔需要停止所有正在运行的线程。过去,这种 “全局暂停” GC 暂停 有时会持续几分钟 75!使用现代 GC 算法,这不再是一个大问题,但 GC 暂停仍然可能很明显(见 “限制垃圾回收的影响”)。
- 在虚拟化环境中,虚拟机可以被 挂起(暂停所有进程的执行并将内存内容保存到磁盘)和 恢复(恢复内存内容并继续执行)。这种暂停可能发生在进程执行的任何时间,并且可能持续任意长的时间。这个功能有时用于虚拟机从一台主机到另一台主机的 实时迁移,无需重启,在这种情况下,暂停的长度取决于进程写入内存的速率 76。
- 在笔记本电脑和手机等终端用户设备上,执行也可能被任意挂起和恢复,例如,当用户合上笔记本电脑盖时。
- 当操作系统上下文切换到另一个线程时,或者当虚拟机管理程序切换到不同的虚拟机时(在虚拟机中运行时),当前运行的线程可能在代码的任何任意点暂停。在虚拟机的情况下,在其他虚拟机中花费的 CPU 时间称为 窃取时间。如果机器负载很重 —— 即,如果有长队列的线程等待运行 —— 暂停的线程可能需要一些时间才能再次运行。
- 如果应用程序执行同步磁盘访问,线程可能会暂停等待缓慢的磁盘 I/O 操作完成 77。在许多语言中,磁盘访问可能会令人惊讶地发生,即使代码没有明确提到文件访问 —— 例如,Java 类加载器在首次使用时会延迟加载类文件,这可能发生在程序执行的任何时间。I/O 暂停和 GC 暂停甚至可能共谋结合它们的延迟 78。如果磁盘实际上是网络文件系统或网络块设备(如亚马逊的 EBS),I/O 延迟还会受到网络延迟可变性的影响 31。
- 如果操作系统配置为允许 交换到磁盘(分页),简单的内存访问可能会导致页面错误,需要从磁盘加载页面到内存。线程在此缓慢的 I/O 操作进行时暂停。如果内存压力很高,这可能反过来需要将不同的页面交换到磁盘。在极端情况下,操作系统可能会花费大部分时间在内存中交换页面进出,而实际完成的工作很少(这被称为 抖动)。为了避免这个问题,服务器机器上通常禁用分页(如果你宁愿杀死进程以释放内存而不是冒抖动的风险)。
- Unix 进程可以通过向其发送
SIGSTOP信号来暂停,例如通过在 shell 中按 Ctrl-Z。此信号立即停止进程获取更多 CPU 周期,直到使用SIGCONT恢复它,此时它从停止的地方继续运行。即使你的环境通常不使用SIGSTOP,它也可能被运维工程师意外发送。
所有这些情况都可以在任何时候 抢占 正在运行的线程,并在稍后的某个时间恢复它,而线程甚至没有注意到。这个问题类似于在单台机器上使多线程代码线程安全:你不能对时序做任何假设,因为可能会发生任意的上下文切换和并行性。
在单台机器上编写多线程代码时,我们有相当好的工具来使其线程安全:互斥锁、信号量、原子计数器、无锁数据结构、阻塞队列等。不幸的是,这些工具不能直接转换到分布式系统,因为分布式系统没有共享内存 —— 只有通过不可靠网络发送的消息。
分布式系统中的节点必须假设其执行可以在任何时候暂停相当长的时间,即使在函数的中间。在暂停期间,世界的其余部分继续运行,甚至可能因为暂停的节点没有响应而宣布它死亡。最终,暂停的节点可能会继续运行,甚至没有注意到它在睡觉,直到它稍后某个时候检查其时钟。
响应时间保证
在许多编程语言和操作系统中,如所讨论的,线程和进程可能会暂停无限长的时间。如果你足够努力,这些暂停的原因 可以 被消除。
某些软件在环境中运行,如果未能在指定时间内响应可能会造成严重损害:控制飞机、火箭、机器人、汽车和其他物理对象的计算机必须快速且可预测地响应其传感器输入。在这些系统中,有一个指定的 截止时间,软件必须在此之前响应;如果它没有达到截止时间,可能会导致整个系统的故障。这些被称为 硬实时 系统。
Note
在嵌入式系统中,实时 意味着系统经过精心设计和测试,以在所有情况下满足指定的时序保证。这个含义与网络上更模糊的 实时 术语使用形成对比,后者描述服务器向客户端推送数据和流处理,没有硬响应时间约束(见后续章节)。
例如,如果你的汽车的车载传感器检测到你当前正在经历碰撞,你不希望安全气囊的释放因为安全气囊释放系统中不合时宜的 GC 暂停而延迟。
在系统中提供实时保证需要软件栈所有级别的支持:需要 实时操作系统(RTOS),它允许进程在指定的时间间隔内以有保证的 CPU 时间分配进行调度;库函数必须记录其最坏情况执行时间;动态内存分配可能受到限制或完全禁止(实时垃圾回收器存在,但应用程序仍必须确保它不会给 GC 太多工作);必须进行大量的测试和测量以确保满足保证。
所有这些都需要大量的额外工作,并严重限制了可以使用的编程语言、库和工具的范围(因为大多数语言和工具不提供实时保证)。由于这些原因,开发实时系统非常昂贵,它们最常用于安全关键的嵌入式设备。此外,“实时” 不同于 “高性能” —— 事实上,实时系统可能具有较低的吞吐量,因为它们必须优先考虑及时响应高于一切(另见 “延迟和资源利用率”)。
对于大多数服务器端数据处理系统,实时保证根本不经济或不合适。因此,这些系统必须承受在非实时环境中运行带来的暂停和时钟不稳定性。
限制垃圾回收的影响
垃圾回收曾经是进程暂停的最大原因之一 79,但幸运的是 GC 算法已经改进了很多:经过适当调整的回收器现在通常只会暂停几毫秒。Java 运行时提供了并发标记清除(CMS)、G1、Z 垃圾回收器(ZGC)、Epsilon 和 Shenandoah 等回收器。每个都针对不同的内存配置文件进行了优化,如高频对象创建、大堆等。相比之下,Go 提供了一个更简单的并发标记清除垃圾回收器,试图自我优化。
如果你需要完全避免 GC 暂停,一个选择是使用根本没有垃圾回收器的语言。例如,Swift 使用自动引用计数来确定何时可以释放内存;Rust 和 Mojo 使用类型系统跟踪对象的生命周期,以便编译器可以确定必须分配内存多长时间。
也可以使用垃圾回收语言,同时减轻暂停的影响。一种方法是将 GC 暂停视为节点的短暂计划中断,并让其他节点在一个节点收集垃圾时处理来自客户端的请求。如果运行时可以警告应用程序节点很快需要 GC 暂停,应用程序可以停止向该节点发送新请求,等待它完成处理未完成的请求,然后在没有请求进行时执行 GC。这个技巧从客户端隐藏了 GC 暂停,并减少了响应时间的高百分位数 80 81。
这个想法的一个变体是仅对短期对象使用垃圾回收器(快速收集),并定期重启进程,在它们积累足够的长期对象需要长期对象的完整 GC 之前 79 82。可以一次重启一个节点,并且可以在计划重启之前将流量从节点转移,就像滚动升级一样(见 第 5 章)。
这些措施不能完全防止垃圾回收暂停,但它们可以有效地减少对应用程序的影响。
知识、真相与谎言
到目前为止,在本章中,我们已经探讨了分布式系统与在单台计算机上运行的程序的不同之处:没有共享内存,只有通过不可靠的网络进行消息传递,具有可变延迟,系统可能会遭受部分失效、不可靠的时钟和处理暂停。
如果你不习惯分布式系统,这些问题的后果会令人深感迷惑。网络中的节点不能 确切地知道 关于其他节点的任何事情 —— 它只能根据它接收(或未接收)的消息进行猜测。节点只能通过与另一个节点交换消息来了解它处于什么状态(它存储了什么数据,它是否正常运行等)。如果远程节点没有响应,就无法知道它处于什么状态,因为网络中的问题无法与节点的问题可靠地区分开来。
这些系统的讨论接近哲学:在我们的系统中,我们知道什么是真或假?如果感知和测量的机制不可靠,我们对这些知识有多确定 83?软件系统是否应该遵守我们对物理世界的期望法则,如因果关系?
幸运的是,我们不需要走到弄清生命意义的程度。在分布式系统中,我们可以陈述我们对行为(系统模型)的假设,并以这样的方式设计实际系统,使其满足这些假设。算法可以被证明在某个系统模型内正确运行。这意味着即使底层系统模型提供的保证很少,也可以实现可靠的行为。
然而,尽管可以在不可靠的系统模型中使软件表现良好,但这样做并不简单。在本章的其余部分,我们将进一步探讨分布式系统中知识和真相的概念,这将帮助我们思考我们可以做出的假设类型和我们可能希望提供的保证。在 第 10 章 中,我们将继续查看在特定假设下提供特定保证的分布式算法的一些示例。
多数派原则
想象一个具有不对称故障的网络:一个节点能够接收发送给它的所有消息,但该节点的任何传出消息都被丢弃或延迟 22。即使该节点运行得非常好,并且正在接收来自其他节点的请求,其他节点也无法听到它的响应。在一些超时之后,其他节点宣布它死亡,因为它们没有收到该节点的消息。情况展开就像一场噩梦:半断开的节点被拖到墓地,踢腿尖叫着 “我没死!” —— 但由于没人能听到它的尖叫,葬礼队伍以坚忍的决心继续前进。
在稍微不那么可怕的情况下,半断开的节点可能会注意到它发送的消息没有被其他节点确认,因此意识到网络中一定有故障。尽管如此,该节点被其他节点错误地宣布死亡,半断开的节点对此无能为力。
作为第三种情况,想象一个节点暂停执行一分钟。在此期间,没有请求被处理,也没有响应被发送。其他节点等待、重试、变得不耐烦,最终宣布该节点死亡并将其装上灵车。最后,暂停结束,节点的线程继续运行,就好像什么都没发生过。其他节点惊讶地看到据称已死的节点突然从棺材里抬起头来,健康状况良好,开始愉快地与旁观者聊天。起初,暂停的节点甚至没有意识到整整一分钟已经过去,它被宣布死亡 —— 从它的角度来看,自从它上次与其他节点交谈以来,几乎没有时间过去。
这些故事的寓意是,节点不一定能信任自己对情况的判断。分布式系统不能完全依赖单个节点,因为节点可能随时失效,可能使系统陷入困境并无法恢复。相反,许多分布式算法依赖于 仲裁,即节点之间的投票(见 “读写仲裁”):决策需要来自几个节点的最少票数,以减少对任何一个特定节点的依赖。
这包括关于宣布节点死亡的决定。如果节点的仲裁宣布另一个节点死亡,那么它必须被认为是死亡的,即使该节点仍然感觉自己非常活着。个别节点必须遵守仲裁决定并退出。
最常见的是,仲裁是超过半数节点的绝对多数(尽管其他类型的仲裁也是可能的)。多数仲裁允许系统在少数节点故障时继续工作(三个节点可以容忍一个故障节点;五个节点可以容忍两个故障节点)。然而,它仍然是安全的,因为系统中只能有一个多数 —— 不能同时有两个具有冲突决策的多数。当我们在 第 10 章 讨论 共识算法 时,我们将更详细地讨论仲裁的使用。
分布式锁和租约
分布式应用程序中的锁和租约容易被误用,并且是错误的常见来源 84。让我们看看它们如何出错的一个特定案例。
在 “进程暂停” 中,我们看到租约是一种超时的锁,如果旧所有者停止响应(可能是因为它崩溃了、暂停太久或与网络断开连接),可以分配给新所有者。你可以在系统需要只有一个某种东西的情况下使用租约。例如:
- 只允许一个节点成为数据库分片的主节点,以避免脑裂(见 “处理节点中断”)。
- 只允许一个事务或客户端更新特定资源或对象,以防止并发写入损坏它。
- 只有一个节点应该处理大型处理作业的给定输入文件,以避免由于多个节点冗余地执行相同工作而浪费精力。
值得仔细思考如果几个节点同时认为它们持有租约会发生什么,可能是由于进程暂停。在第三个例子中,后果只是一些浪费的计算资源,这不是什么大问题。但在前两种情况下,后果可能是数据丢失或损坏,这要严重得多。
例如,图 9-4 显示了由于锁的错误实现导致的数据损坏错误。(该错误不是理论上的:HBase 曾经有这个问题 85 86。)假设你想确保存储服务中的文件一次只能由一个客户端访问,因为如果多个客户端试图写入它,文件将被损坏。你尝试通过要求客户端在访问文件之前从锁服务获取租约来实现这一点。这种锁服务通常使用共识算法实现;我们将在 第 10 章 中进一步讨论这一点。
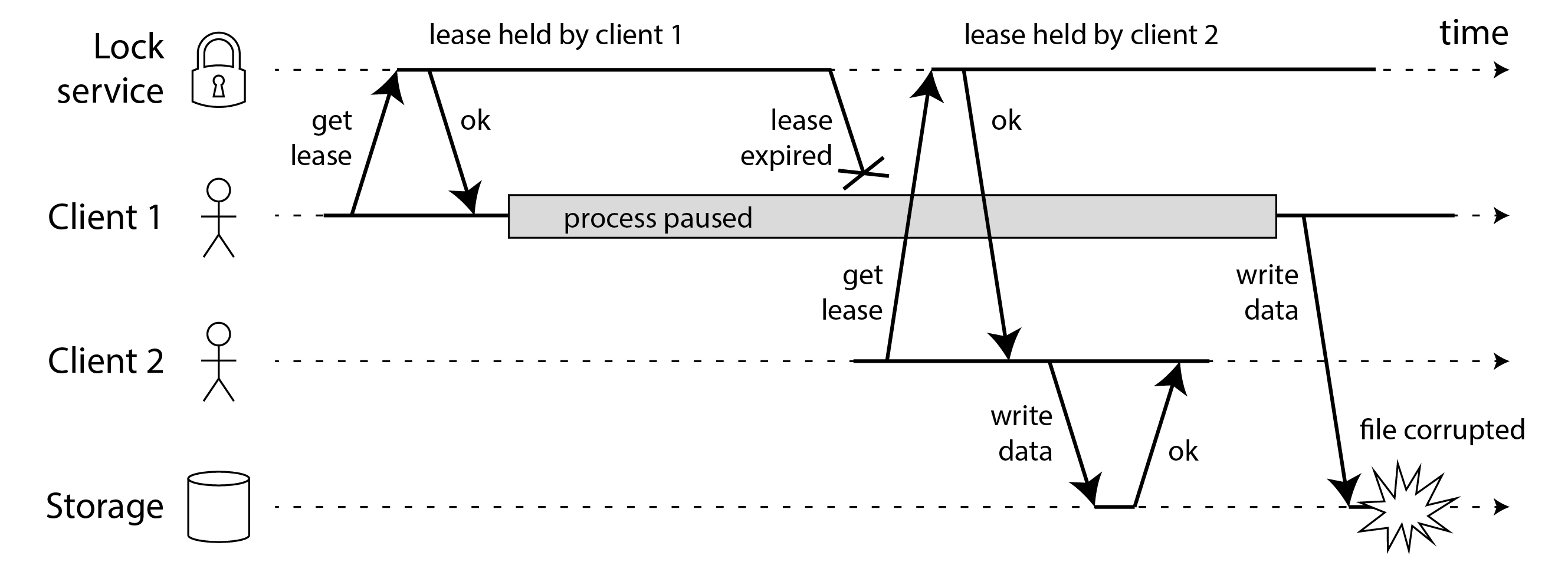
问题是我们在 “进程暂停” 中讨论的一个例子:如果持有租约的客户端暂停太久,其租约就会过期。另一个客户端可以获得同一文件的租约,并开始写入文件。当暂停的客户端回来时,它(错误地)认为它仍然有有效的租约,并继续写入文件。我们现在有了脑裂情况:客户端的写入冲突并损坏了文件。
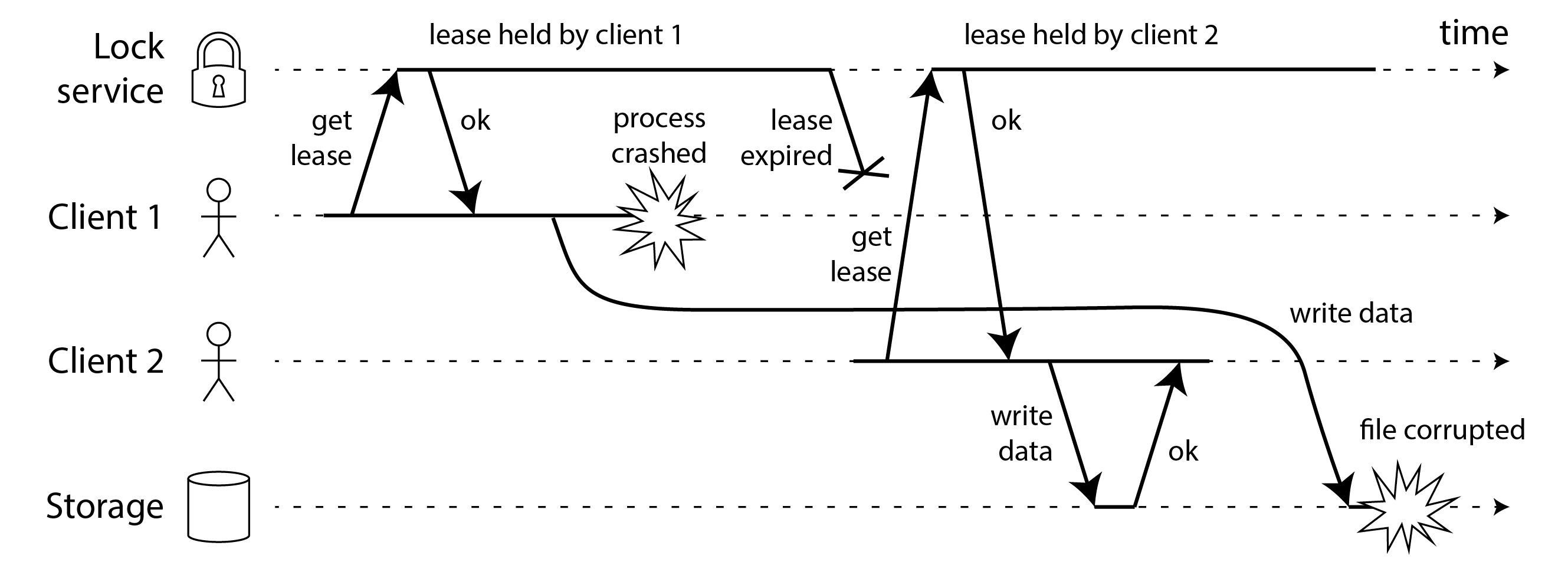
图 9-5 显示了具有类似后果的另一个问题。在这个例子中没有进程暂停,只有客户端 1 的崩溃。就在客户端 1 崩溃之前,它向存储服务发送了一个写请求,但这个请求在网络中被延迟了很长时间。(请记住 “实践中的网络故障”,数据包有时可能会延迟一分钟或更长时间。)当写请求到达存储服务时,租约已经超时,允许客户端 2 获取它并发出自己的写入。结果是类似于 图 9-4 的损坏。
隔离僵尸进程和延迟请求
术语 僵尸 有时用于描述尚未发现失去租约的前租约持有者,并且仍在充当当前租约持有者。由于我们不能完全排除僵尸,我们必须确保它们不能以脑裂的形式造成任何损害。这被称为 隔离 僵尸。
一些系统试图通过关闭僵尸来隔离它们,例如通过断开它们与网络的连接 9、通过云提供商的管理界面关闭 VM,甚至物理关闭机器 87。这种方法被称为 对端节点爆头(STONITH)。不幸的是,它存在一些问题:它不能防范像 图 9-5 中那样的大网络延迟;可能会发生所有节点相互关闭的情况 19;到检测到僵尸并关闭它时,可能已经太晚了,数据可能已经被损坏。
一个更强大的隔离解决方案,可以防范僵尸和延迟请求,如 图 9-6 所示。
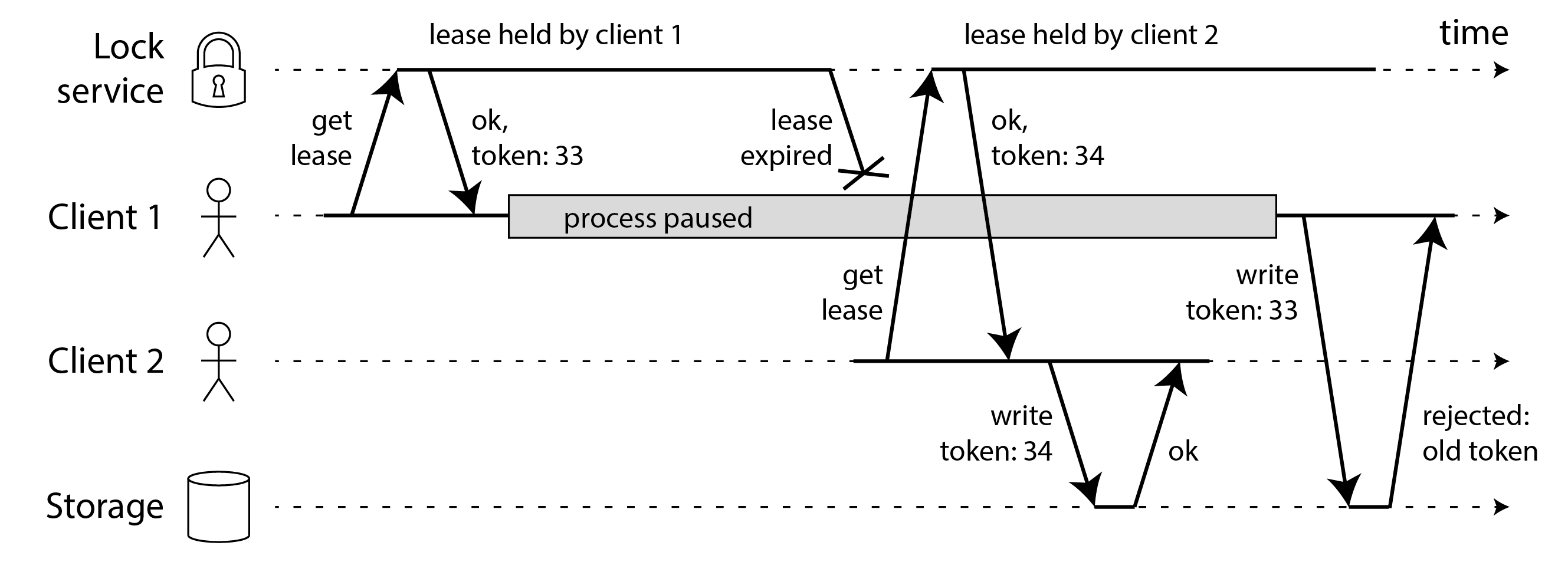
假设每次锁服务授予锁或租约时,它还返回一个 隔离令牌,这是一个每次授予锁时都会增加的数字(例如,由锁服务递增)。然后我们可以要求客户端每次向存储服务发送写请求时,都必须包含其当前的隔离令牌。
Note
在 图 9-6 中,客户端 1 获得带有令牌 33 的租约,但随后进入长时间暂停,租约过期。客户端 2 获得带有令牌 34 的租约(数字总是增加),然后将其写请求发送到存储服务,包括令牌 34。稍后,客户端 1 恢复执行并将其写入发送到存储服务,包括其令牌值 33。然而,存储服务记得它已经处理了具有更高令牌编号(34)的写入,因此它拒绝带有令牌 33 的请求。刚刚获得租约的客户端必须立即向存储服务进行写入,一旦该写入完成,任何僵尸都被隔离了。
如果 ZooKeeper 是你的锁服务,你可以使用事务 ID zxid 或节点版本 cversion 作为隔离令牌 85。使用 etcd,修订号与租约 ID 一起起着类似的作用 89。Hazelcast 中的 FencedLock API 明确生成隔离令牌 90。
这种机制要求存储服务有某种方法来检查写入是否基于过时的令牌。或者,服务支持仅在对象自当前客户端上次读取以来未被另一个客户端写入时才成功的写入就足够了,类似于原子比较并设置(CAS)操作。例如,对象存储服务支持这种检查:Amazon S3 称之为 条件写入,Azure Blob Storage 称之为 条件标头,Google Cloud Storage 称之为 请求前提条件。
多副本隔离
如果你的客户端只需要写入一个支持此类条件写入的存储服务,锁服务在某种程度上是多余的 91 92,因为租约分配本可以直接基于该存储服务实现 93。然而,一旦你有了隔离令牌,你也可以将其用于多个服务或副本,并确保旧的租约持有者在所有这些服务上都被隔离。
例如,想象存储服务是一个具有最后写入胜利冲突解决的无主复制键值存储(见 “无主复制”)。在这样的系统中,客户端直接向每个副本发送写入,每个副本根据客户端分配的时间戳独立决定是否接受写入。
如 图 9-7 所示,你可以将写入者的隔离令牌放在时间戳的最高有效位或数字中。然后你可以确保新租约持有者生成的任何时间戳都将大于旧租约持有者的任何时间戳,即使旧租约持有者的写入发生得更晚。
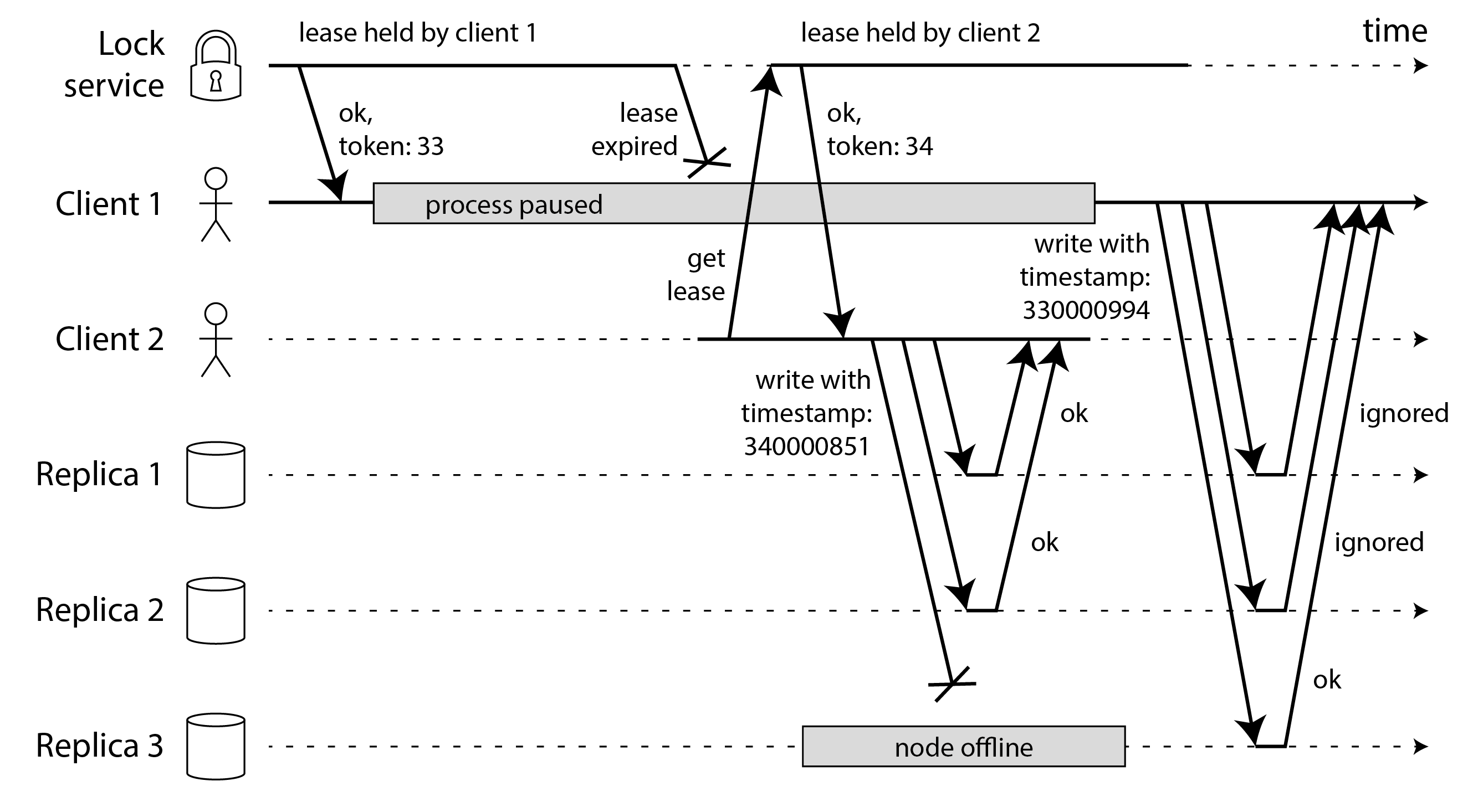
在 图 9-7 中,客户端 2 有隔离令牌 34,因此它所有以 34… 开头的时间戳都大于客户端 1 生成的任何以 33… 开头的时间戳。客户端 2 写入副本的仲裁,但它无法到达副本 3。这意味着当僵尸客户端 1 稍后尝试写入时,它的写入可能在副本 3 上成功,即使它被副本 1 和 2 忽略。这不是问题,因为后续的仲裁读取将更喜欢具有更大时间戳的客户端 2 的写入,读修复或反熵最终将覆盖客户端 1 写入的值。
从这些例子可以看出,假设任何时候只有一个节点持有租约是不安全的。幸运的是,通过一点小心,你可以使用隔离令牌来防止僵尸和延迟请求造成任何损害。
拜占庭故障
隔离令牌可以检测并阻止 无意中 出错的节点(例如,因为它尚未发现其租约已过期)。然而,如果节点故意想要破坏系统的保证,它可以通过发送带有虚假隔离令牌的消息轻松做到。
在本书中,我们假设节点是不可靠但诚实的:它们可能很慢或从不响应(由于故障),它们的状态可能已过时(由于 GC 暂停或网络延迟),但我们假设如果节点 确实 响应,它就是在说 “真话”:据它所知,它正在按协议规则行事。
如果节点可能 “撒谎”(发送任意错误或损坏的响应)的风险存在,分布式系统问题会变得更加困难 —— 例如,它可能在同一次选举中投出多个相互矛盾的票。这种行为被称为 拜占庭故障,在这种不信任环境中达成共识的问题被称为 拜占庭将军问题 94。
拜占庭将军问题
拜占庭将军问题是所谓 两将军问题 95 的推广,它想象了两个军队将军需要就战斗计划达成一致的情况。由于他们在两个不同的地点扎营,他们只能通过信使进行通信,信使有时会延迟或丢失(就像网络中的数据包)。我们将在 第 10 章 中讨论这个 共识 问题。
在问题的拜占庭版本中,有 n 个需要达成一致的将军,他们的努力受到他们中间有一些叛徒的阻碍。大多数将军是忠诚的,因此发送真实的消息,但叛徒可能试图通过发送虚假或不真实的消息来欺骗和混淆其他人。事先不知道谁是叛徒。
拜占庭是一个古希腊城市,后来成为君士坦丁堡,位于现在土耳其的伊斯坦布尔。没有任何历史证据表明拜占庭的将军比其他地方的将军更容易搞阴谋和密谋。相反,这个名字源自 拜占庭 一词在 过于复杂、官僚、狡猾 的意义上的使用,这个词在计算机出现之前很久就在政治中使用了 96。Lamport 想选择一个不会冒犯任何读者的国籍,他被建议称之为 阿尔巴尼亚将军问题 不是个好主意 97。
如果即使某些节点发生故障并且不遵守协议,或者恶意攻击者干扰网络,系统仍能继续正确运行,则该系统是 拜占庭容错 的。这种担忧在某些特定情况下是相关的。例如:
- 在航空航天环境中,计算机内存或 CPU 寄存器中的数据可能因辐射而损坏,导致它以任意不可预测的方式响应其他节点。由于系统故障的成本非常高昂(例如,飞机坠毁并杀死机上所有人,或火箭与国际空间站相撞),飞行控制系统必须容忍拜占庭故障 98 99。
- 在有多个参与方的系统中,一些参与者可能试图欺骗或欺诈其他人。在这种情况下,节点简单地信任另一个节点的消息是不安全的,因为它们可能是恶意发送的。例如,比特币等加密货币和其他区块链可以被认为是让相互不信任的各方就交易是否发生达成一致的一种方式,而无需依赖中央权威 100。
然而,在我们在本书中讨论的系统类型中,我们通常可以安全地假设没有拜占庭故障。在数据中心中,所有节点都由你的组织控制(因此它们有望被信任),辐射水平足够低,内存损坏不是主要问题(尽管正在考虑轨道数据中心 101)。多租户系统有相互不信任的租户,但它们使用防火墙、虚拟化和访问控制策略相互隔离,而不是使用拜占庭容错。使系统拜占庭容错的协议相当昂贵 102,容错嵌入式系统依赖于硬件级别的支持 98。在大多数服务器端数据系统中,部署拜占庭容错解决方案的成本使它们不切实际。
Web 应用程序确实需要预期客户端在最终用户控制下的任意和恶意行为,例如 Web 浏览器。这就是输入验证、清理和输出转义如此重要的原因:例如,防止 SQL 注入和跨站脚本攻击。然而,我们通常不在这里使用拜占庭容错协议,而只是让服务器成为决定什么客户端行为被允许和不被允许的权威。在没有这种中央权威的点对点网络中,拜占庭容错更相关 103 104。
软件中的错误可以被视为拜占庭故障,但如果你将相同的软件部署到所有节点,那么拜占庭容错算法无法拯救你。大多数拜占庭容错算法需要超过三分之二的节点的绝对多数才能正常运行(例如,如果你有四个节点,最多一个可能发生故障)。要使用这种方法对付错误,你必须有四个相同软件的独立实现,并希望错误只出现在四个实现中的一个。
同样,如果协议可以保护我们免受漏洞、安全妥协和恶意攻击,那将是很有吸引力的。不幸的是,这也不现实:在大多数系统中,如果攻击者可以破坏一个节点,他们可能可以破坏所有节点,因为它们可能运行相同的软件。因此,传统机制(身份验证、访问控制、加密、防火墙等)仍然是防范攻击者的主要保护。
弱形式的谎言
尽管我们假设节点通常是诚实的,但向软件添加防范弱形式 “谎言” 的机制可能是值得的 —— 例如,由于硬件问题、软件错误和配置错误导致的无效消息。这种保护机制不是完全的拜占庭容错,因为它们无法抵御坚定的对手,但它们仍然是朝着更好可靠性迈出的简单而务实的步骤。例如:
- 由于硬件问题或操作系统、驱动程序、路由器等中的错误,网络数据包有时确实会损坏。通常,损坏的数据包会被内置于 TCP 和 UDP 中的校验和捕获,但有时它们会逃避检测 105 106 107。简单的措施通常足以防范此类损坏,例如应用程序级协议中的校验和。TLS 加密连接也提供防损坏保护。
- 公开可访问的应用程序必须仔细清理来自用户的任何输入,例如检查值是否在合理范围内,并限制字符串的大小以防止通过大内存分配进行拒绝服务。防火墙后面的内部服务可能能够在输入上进行较少严格的检查,但协议解析器中的基本检查仍然是个好主意 105。
- NTP 客户端可以配置多个服务器地址。同步时,客户端联系所有服务器,估计它们的错误,并检查大多数服务器是否在某个时间范围内达成一致。只要大多数服务器都正常,报告不正确时间的配置错误的 NTP 服务器就会被检测为异常值并从同步中排除 39。使用多个服务器使 NTP 比仅使用单个服务器更强大。
系统模型与现实
许多算法被设计来解决分布式系统问题 —— 例如,我们将在 第 10 章 中研究共识问题的解决方案。为了有用,这些算法需要容忍我们在本章中讨论的分布式系统的各种故障。
算法需要以不过度依赖于它们运行的硬件和软件配置细节的方式编写。这反过来又要求我们以某种方式形式化我们期望在系统中发生的故障类型。我们通过定义 系统模型 来做到这一点,这是一个描述算法可能假设什么事情的抽象。
关于时序假设,三种系统模型常用:
- 同步模型
- 同步模型假设有界的网络延迟、有界的进程暂停和有界的时钟误差。这并不意味着精确同步的时钟或零网络延迟;它只是意味着你知道网络延迟、暂停和时钟漂移永远不会超过某个固定的上限 108。同步模型不是大多数实际系统的现实模型,因为(如本章所讨论的)无界延迟和暂停确实会发生。
- 部分同步模型
- 部分同步意味着系统 大部分时间 表现得像同步系统,但有时会超过网络延迟、进程暂停和时钟漂移的界限 108。这是许多系统的现实模型:大部分时间,网络和进程表现相当良好 —— 否则我们永远无法完成任何事情 —— 但我们必须考虑到任何时序假设偶尔可能会被打破的事实。发生这种情况时,网络延迟、暂停和时钟误差可能会变得任意大。
- 异步模型
- 在这个模型中,算法不允许做出任何时序假设 —— 事实上,它甚至没有时钟(因此它不能使用超时)。一些算法可以为异步模型设计,但它非常有限。
此外,除了时序问题,我们还必须考虑节点故障。节点的一些常见系统模型是:
- 崩溃停止故障
- 在 崩溃停止(或 故障停止)模型中,算法可以假设节点只能以一种方式失效,即崩溃 109。这意味着节点可能在任何时刻突然停止响应,此后该节点永远消失 —— 它永远不会回来。
- 崩溃恢复故障
- 我们假设节点可能在任何时刻崩溃,并且可能在某个未知时间后再次开始响应。在崩溃恢复模型中,假设节点具有跨崩溃保留的稳定存储(即非易失性磁盘存储),而内存中的状态假设丢失。
- 性能下降和部分功能
- 除了崩溃和重启之外,节点可能变慢:它们可能仍然能够响应健康检查请求,但速度太慢而无法完成任何实际工作。例如,千兆网络接口可能由于驱动程序错误突然降至 1 Kb/s 吞吐量 110;处于内存压力下的进程可能会花费大部分时间执行垃圾回收 111;磨损的 SSD 可能具有不稳定的性能;硬件可能受到高温、松动的连接器、机械振动、电源问题、固件错误等的影响 112。这种情况被称为 跛行节点、灰色故障 或 慢速故障 113,它可能比干净失效的节点更难处理。一个相关的问题是当进程停止执行它应该做的某些事情,而其他方面继续工作时,例如因为后台线程崩溃或死锁 114。
- 拜占庭(任意)故障
- 节点可能做任何事情,包括试图欺骗和欺骗其他节点,如上一节所述。
对于建模真实系统,具有崩溃恢复故障的部分同步模型通常是最有用的模型。它允许无界的网络延迟、进程暂停和慢节点。但是分布式算法如何应对该模型?
定义算法的正确性
为了定义算法 正确 的含义,我们可以描述它的 属性。例如,排序算法的输出具有这样的属性:对于输出列表的任何两个不同元素,左边的元素小于右边的元素。这只是定义列表排序含义的正式方式。
同样,我们可以写下我们希望分布式算法具有的属性,以定义正确的含义。例如,如果我们为锁生成隔离令牌(见 “隔离僵尸进程和延迟请求”),我们可能要求算法具有以下属性:
- 唯一性
- 没有两个隔离令牌请求返回相同的值。
- 单调序列
- 如果请求 x 返回令牌 t**x,请求 y 返回令牌 t**y,并且 x 在 y 开始之前完成,则 t**x < t**y。
- 可用性
- 请求隔离令牌且不崩溃的节点最终会收到响应。
如果算法在我们假设该系统模型中可能发生的所有情况下始终满足其属性,则该算法在某个系统模型中是正确的。然而,如果所有节点崩溃,或者所有网络延迟突然变得无限长,那么没有算法能够完成任何事情。即使在允许完全失效的系统模型中,我们如何仍然做出有用的保证?
安全性与活性
为了澄清情况,值得区分两种不同类型的属性:安全性 和 活性 属性。在刚才给出的例子中,唯一性 和 单调序列 是安全属性,但 可用性 是活性属性。
什么区分这两种属性?一个迹象是活性属性通常在其定义中包含 “最终” 一词。(是的,你猜对了 —— 最终一致性 是一个活性属性 115。)
安全性通常被非正式地定义为 没有坏事发生,活性被定义为 好事最终会发生。然而,最好不要过多地解读这些非正式定义,因为 “好” 和 “坏” 是价值判断,不能很好地应用于算法。安全性和活性的实际定义更精确 116:
- 如果违反了安全属性,我们可以指出它被破坏的特定时间点(例如,如果违反了唯一性属性,我们可以识别返回重复隔离令牌的特定操作)。在违反安全属性之后,违规无法撤消 —— 损害已经造成。
- 活性属性以相反的方式工作:它可能在某个时间点不成立(例如,节点可能已发送请求但尚未收到响应),但总有希望它将来可能得到满足(即通过接收响应)。
区分安全性和活性属性的一个优点是它有助于我们处理困难的系统模型。对于分布式算法,通常要求安全属性在系统模型的所有可能情况下 始终 成立 108。也就是说,即使所有节点崩溃,或整个网络失效,算法也必须确保它不会返回错误的结果(即,安全属性保持满足)。
然而,对于活性属性,我们可以做出警告:例如,我们可以说请求只有在大多数节点没有崩溃时才需要收到响应,并且只有在网络最终从中断中恢复时才需要响应。部分同步模型的定义要求系统最终返回到同步状态 —— 也就是说,任何网络中断期只持续有限的时间,然后被修复。
将系统模型映射到现实世界
安全性和活性属性以及系统模型对于推理分布式算法的正确性非常有用。然而,在实践中实现算法时,现实的混乱事实又会回来咬你一口,很明显系统模型是现实的简化抽象。
例如,崩溃恢复模型中的算法通常假设稳定存储中的数据在崩溃后幸存。然而,如果磁盘上的数据损坏了,或者由于硬件错误或配置错误而擦除了数据,会发生什么 117?如果服务器有固件错误并且在重启时无法识别其硬盘驱动器,即使驱动器正确连接到服务器,会发生什么 118?
仲裁算法(见 “读写仲裁”)依赖于节点记住它声称已存储的数据。如果节点可能患有健忘症并忘记先前存储的数据,那会破坏仲裁条件,从而破坏算法的正确性。也许需要一个新的系统模型,其中我们假设稳定存储大多在崩溃后幸存,但有时可能会丢失。但该模型随后变得更难推理。
算法的理论描述可以声明某些事情被简单地假设不会发生 —— 在非拜占庭系统中,我们确实必须对可能和不可能发生的故障做出一些假设。然而,真正的实现可能仍然必须包含代码来处理被假设为不可能的事情发生的情况,即使该处理归结为 printf("Sucks to be you") 和 exit(666) —— 即,让人类操作员清理烂摊子 119。(这是计算机科学和软件工程之间的一个区别。)
这并不是说理论上的、抽象的系统模型是无用的 —— 恰恰相反。它们非常有助于将真实系统的复杂性提炼为我们可以推理的可管理的故障集,以便我们可以理解问题并尝试系统地解决它。
形式化方法和随机测试
我们如何知道算法满足所需的属性?由于并发性、部分失效和网络延迟,存在大量潜在状态。我们需要保证属性在每个可能的状态下都成立,并确保我们没有忘记任何边界情况。
一种方法是通过数学描述算法来形式验证它,并使用证明技术来表明它在系统模型允许的所有情况下都满足所需的属性。证明算法正确并不意味着它在真实系统上的 实现 必然总是正确运行。但这是一个非常好的第一步,因为理论分析可以发现算法中的问题,这些问题可能在真实系统中长时间隐藏,并且只有当你的假设(例如,关于时序)由于不寻常的情况而失败时才会咬你一口。
将理论分析与经验测试相结合以验证实现按预期运行是明智的。基于属性的测试、模糊测试和确定性模拟测试(DST)等技术使用随机化来在各种情况下测试系统。亚马逊网络服务等公司已成功地在其许多产品上使用了这些技术的组合 120 121。
模型检查与规范语言
模型检查器 是帮助验证算法或系统按预期运行的工具。算法规范是用专门构建的语言编写的,如 TLA+、Gallina 或 FizzBee。这些语言使得更容易专注于算法的行为,而不必担心代码实现细节。然后,模型检查器使用这些模型通过系统地尝试所有可能发生的事情来验证不变量在算法的所有状态中都成立。
模型检查实际上不能证明算法的不变量对每个可能的状态都成立,因为大多数现实世界的算法都有无限的状态空间。对所有状态的真正验证需要形式证明,这是可以做到的,但通常比运行模型检查器更困难。相反,模型检查器鼓励你将算法的模型减少到可以完全验证的近似值,或者将执行限制到某个上限(例如,通过设置可以发送的最大消息数)。任何只在更长执行时发生的错误将不会被发现。
尽管如此,模型检查器在易用性和查找非显而易见错误的能力之间取得了很好的平衡。CockroachDB、TiDB、Kafka 和许多其他分布式系统使用模型规范来查找和修复错误 122 123 124。例如,使用 TLA+,研究人员能够证明由算法的散文描述中的歧义引起的视图戳复制(VR)中数据丢失的可能性 125。
按设计,模型检查器不运行你的实际代码,而是运行一个简化的模型,该模型仅指定你的协议的核心思想。这使得系统地探索状态空间更易处理,但有风险是你的规范和你的实现彼此不同步 126。可以检查模型和真实实现是否具有等效行为,但这需要在真实实现中进行仪器化 127。
故障注入
许多错误是在机器和网络故障发生时触发的。故障注入是一种有效(有时令人恐惧)的技术,用于验证系统的实现在出错时是否按预期工作。这个想法很简单:将故障注入到正在运行的系统环境中,看看它如何表现。故障可以是网络故障、机器崩溃、磁盘损坏、暂停的进程 —— 你能想象到的计算机出错的任何事情。
故障注入测试通常在与系统将运行的生产环境非常相似的环境中运行。有些甚至直接将故障注入到他们的生产环境中。Netflix 通过他们的 Chaos Monkey 工具推广了这种方法 128。生产故障注入通常被称为 混沌工程,我们在 “可靠性与容错” 中讨论过。
要运行故障注入测试,首先部署被测系统以及故障注入协调器和脚本。协调器负责决定执行什么故障以及何时执行它们。本地或远程脚本负责将故障注入到单个节点或进程中。注入脚本使用许多不同的工具来触发故障。可以使用 Linux 的 kill 命令暂停或杀死 Linux 进程,可以使用 umount 卸载磁盘,可以通过防火墙设置中断网络连接。你可以在注入故障期间和之后检查系统行为,以确保事情按预期工作。
触发故障所需的无数工具使故障注入测试编写起来很麻烦。采用像 Jepsen 这样的故障注入框架来运行故障注入测试以简化过程是常见的。这些框架带有各种操作系统的集成和许多预构建的故障注入器 129。Jepsen 在许多广泛使用的系统中发现关键错误方面非常有效 130 131。
确定性模拟测试
确定性模拟测试(DST)也已成为模型检查和故障注入的流行补充。它使用与模型检查器类似的状态空间探索过程,但它测试你的实际代码,而不是模型。
在 DST 中,模拟自动运行系统的大量随机执行。模拟期间的网络通信、I/O 和时钟时序都被模拟替换,允许模拟器控制事情发生的确切顺序,包括各种时序和故障场景。这允许模拟器探索比手写测试或故障注入更多的情况。如果测试失败,它可以重新运行,因为模拟器知道触发故障的确切操作顺序 —— 与故障注入相比,后者对系统没有如此细粒度的控制。
DST 要求模拟器能够控制所有非确定性来源,例如网络延迟。通常采用三种策略之一来使代码确定性:
- 应用程序级
- 一些系统从头开始构建,以便于确定性地执行代码。例如,DST 领域的先驱之一 FoundationDB 是使用称为 Flow 的异步通信库构建的。Flow 为开发人员提供了将确定性网络模拟注入系统的点 132。类似地,TigerBeetle 是一个具有一流 DST 支持的在线事务处理(OLTP)数据库。系统的状态被建模为状态机,所有突变都发生在单个事件循环中。当与模拟确定性原语(如时钟)结合时,这种架构能够确定性地运行 133。
- 运行时级
- 具有异步运行时和常用库的语言提供了引入确定性的插入点。使用单线程运行时强制所有异步代码按顺序运行。例如,FrostDB 修补 Go 的运行时以按顺序执行 goroutine 134。Rust 的 madsim 库以类似的方式工作。Madsim 提供了 Tokio 的异步运行时 API、AWS 的 S3 库、Kafka 的 Rust 库等的确定性实现。应用程序可以交换确定性库和运行时以获得确定性测试执行,而无需更改其代码。
- 机器级
- 与其在运行时修补代码,不如使整个机器确定性。这是一个微妙的过程,需要机器对所有通常非确定性的调用响应确定性响应。Antithesis 等工具通过构建自定义虚拟机管理程序来做到这一点,该虚拟机管理程序用确定性操作替换通常的非确定性操作。从时钟到网络和存储的一切都需要考虑。不过,一旦完成,开发人员可以在虚拟机管理程序内的容器集合中运行其整个分布式系统,并获得完全确定性的分布式系统。
DST 提供了超越可重放性的几个优势。Antithesis 等工具试图通过在发现不太常见的行为时将测试执行分支为多个子执行来探索应用程序代码中的许多不同代码路径。由于确定性测试通常使用模拟时钟和网络调用,因此此类测试可以比挂钟时间运行得更快。例如,TigerBeetle 的时间抽象允许模拟模拟网络延迟和超时,而实际上不需要触发超时的全部时间长度。这些技术允许模拟器更快地探索更多代码路径。
确定性的力量
非确定性是我们在本章中讨论的所有分布式系统挑战的核心:并发性、网络延迟、进程暂停、时钟跳跃和崩溃都以不可预测的方式发生,从系统的一次运行到下一次运行都不同。相反,如果你能使系统确定性,那可以极大地简化事情。
事实上,使事物确定性是一个简单但强大的想法,在分布式系统设计中一再出现。除了确定性模拟测试,我们在过去的章节中已经看到了几种使用确定性的方法:
- 事件溯源的一个关键优势(见 “事件溯源和 CQRS”)是你可以确定性地重放事件日志以重建派生的物化视图。
- 工作流引擎(见 “持久执行和工作流”)依赖于工作流定义是确定性的,以提供持久执行语义。
- 状态机复制,我们将在 “使用共享日志” 中讨论,通过在每个副本上独立执行相同的确定性事务序列来复制数据。我们已经看到了这个想法的两个变体:基于语句的复制(见 “复制日志的实现”)和使用存储过程的串行事务执行(见 “存储过程的利弊”)。
然而,使代码完全确定性需要小心。即使你已经删除了所有并发性并用确定性模拟替换了 I/O、网络通信、时钟和随机数生成器,非确定性元素可能仍然存在。例如,在某些编程语言中,迭代哈希表元素的顺序可能是非确定性的。是否遇到资源限制(内存分配失败、堆栈溢出)也是非确定性的。
总结
在本章中,我们讨论了分布式系统中可能发生的各种问题,包括:
- 每当你尝试通过网络发送数据包时,它可能会丢失或任意延迟。同样,回复可能会丢失或延迟,所以如果你没有得到回复,你不知道消息是否送达。
- 节点的时钟可能与其他节点严重不同步(尽管你尽最大努力设置了 NTP),它可能会突然向前或向后跳跃,而依赖它是危险的,因为你很可能没有一个好的时钟置信区间度量。
- 进程可能在其执行的任何时刻暂停相当长的时间,被其他节点宣告死亡,然后再次恢复活动而没有意识到它曾暂停。
这种 部分失效 可能发生的事实是分布式系统的决定性特征。每当软件尝试做任何涉及其他节点的事情时,都有可能偶尔失败、随机变慢或根本没有响应(并最终超时)。在分布式系统中,我们尝试将对部分失效的容忍构建到软件中,这样即使某些组成部分出现故障,整个系统也可以继续运行。
要容忍故障,第一步是 检测 它们,但即使这样也很困难。大多数系统没有准确的机制来检测节点是否已失败,因此大多数分布式算法依赖超时来确定远程节点是否仍然可用。然而,超时无法区分网络和节点故障,可变的网络延迟有时会导致节点被错误地怀疑崩溃。处理跛行节点(limping nodes)更加困难,这些节点正在响应但速度太慢而无法做任何有用的事情。
一旦检测到故障,让系统容忍它也不容易:没有全局变量、没有共享内存、没有公共知识或机器之间任何其他类型的共享状态 83。节点甚至无法就现在是什么时间达成一致,更不用说任何更深刻的事情了。信息从一个节点流向另一个节点的唯一方式是通过不可靠的网络发送。单个节点无法安全地做出重大决策,因此我们需要协议来征求其他节点的帮助并尝试获得法定人数的同意。
如果你习惯于在单台计算机的理想数学完美环境中编写软件,其中相同的操作总是确定性地返回相同的结果,那么转向分布式系统混乱的物理现实可能会有点震惊。相反,分布式系统工程师通常会认为如果一个问题可以在单台计算机上解决,那它就是微不足道的 4,而且单台计算机现在确实可以做很多事情。如果你可以避免打开潘多拉的盒子,只需将事情保持在单台机器上,例如使用嵌入式存储引擎(见 “嵌入式存储引擎”),通常值得这样做。
然而,正如在 “分布式系统与单节点系统” 中讨论的,可伸缩性并不是使用分布式系统的唯一原因。容错和低延迟(通过将数据在地理上放置在靠近用户的位置)是同样重要的目标,而这些事情无法通过单个节点实现。分布式系统的力量在于,原则上它们可以在服务层面永远运行而不被中断,因为所有故障和维护都可以在节点层面处理。(实际上,如果错误的配置更改被推送到所有节点,仍然会让分布式系统崩溃。)
在本章中,我们还探讨了网络、时钟和进程的不可靠性是否是不可避免的自然法则。我们看到它不是:可以在网络中提供硬实时响应保证和有界延迟,但这样做非常昂贵,并导致硬件资源利用率降低。大多数非安全关键系统选择便宜和不可靠而不是昂贵和可靠。
本章一直在讨论问题,给了我们一个暗淡的前景。在下一章中,我们将转向解决方案,并讨论一些为应对分布式系统中的问题而设计的算法。
参考
Mark Cavage. There’s Just No Getting Around It: You’re Building a Distributed System. ACM Queue, volume 11, issue 4, pages 80-89, April 2013. doi:10.1145/2466486.2482856 ↩︎
Jay Kreps. Getting Real About Distributed System Reliability. blog.empathybox.com, March 2012. Archived at perma.cc/9B5Q-AEBW ↩︎
Coda Hale. You Can’t Sacrifice Partition Tolerance. codahale.com, October 2010. https://perma.cc/6GJU-X4G5 ↩︎
Jeff Hodges. Notes on Distributed Systems for Young Bloods. somethingsimilar.com, January 2013. Archived at perma.cc/B636-62CE ↩︎ ↩︎
Van Jacobson. Congestion Avoidance and Control. At ACM Symposium on Communications Architectures and Protocols (SIGCOMM), August 1988. doi:10.1145/52324.52356 ↩︎ ↩︎
Bert Hubert. The Ultimate SO_LINGER Page, or: Why Is My TCP Not Reliable. blog.netherlabs.nl, January 2009. Archived at perma.cc/6HDX-L2RR ↩︎ ↩︎
Jerome H. Saltzer, David P. Reed, and David D. Clark. End-To-End Arguments in System Design. ACM Transactions on Computer Systems, volume 2, issue 4, pages 277–288, November 1984. doi:10.1145/357401.357402 ↩︎
Peter Bailis and Kyle Kingsbury. The Network Is Reliable. ACM Queue, volume 12, issue 7, pages 48-55, July 2014. doi:10.1145/2639988.2639988 ↩︎ ↩︎
Joshua B. Leners, Trinabh Gupta, Marcos K. Aguilera, and Michael Walfish. Taming Uncertainty in Distributed Systems with Help from the Network. At 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741976 ↩︎ ↩︎
Phillipa Gill, Navendu Jain, and Nachiappan Nagappan. Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications. At ACM SIGCOMM Conference, August 2011. doi:10.1145/2018436.2018477 ↩︎
Urs Hölzle. But recently a farmer had started grazing a herd of cows nearby. And whenever they stepped on the fiber link, they bent it enough to cause a blip. x.com, May 2020. Archived at perma.cc/WX8X-ZZA5 ↩︎
CBC News. Hundreds lose internet service in northern B.C. after beaver chews through cable. cbc.ca, April 2021. Archived at perma.cc/UW8C-H2MY ↩︎
Will Oremus. The Global Internet Is Being Attacked by Sharks, Google Confirms. slate.com, August 2014. Archived at perma.cc/P6F3-C6YG ↩︎
Jess Auerbach Jahajeeah. Down to the wire: The ship fixing our internet. continent.substack.com, November 2023. Archived at perma.cc/DP7B-EQ7S ↩︎
Santosh Janardhan. More details about the October 4 outage. engineering.fb.com, October 2021. Archived at perma.cc/WW89-VSXH ↩︎
Tom Parfitt. Georgian woman cuts off web access to whole of Armenia. theguardian.com, April 2011. Archived at perma.cc/KMC3-N3NZ ↩︎
Antonio Voce, Tural Ahmedzade and Ashley Kirk. ‘Shadow fleets’ and subaquatic sabotage: are Europe’s undersea internet cables under attack? theguardian.com, March 2025. Archived at perma.cc/HA7S-ZDBV ↩︎
Shengyun Liu, Paolo Viotti, Christian Cachin, Vivien Quéma, and Marko Vukolić. XFT: Practical Fault Tolerance beyond Crashes. At 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), November 2016. ↩︎
Mark Imbriaco. Downtime last Saturday. github.blog, December 2012. Archived at perma.cc/M7X5-E8SQ ↩︎ ↩︎
Tom Lianza and Chris Snook. A Byzantine failure in the real world. blog.cloudflare.com, November 2020. Archived at perma.cc/83EZ-ALCY ↩︎ ↩︎
Mohammed Alfatafta, Basil Alkhatib, Ahmed Alquraan, and Samer Al-Kiswany. Toward a Generic Fault Tolerance Technique for Partial Network Partitioning. At 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI), November 2020. ↩︎
Marc A. Donges. Re: bnx2 cards Intermittantly Going Offline. Message to Linux netdev mailing list, spinics.net, September 2012. Archived at perma.cc/TXP6-H8R3 ↩︎ ↩︎
Troy Toman. Inside a CODE RED: Network Edition. signalvnoise.com, September 2020. Archived at perma.cc/BET6-FY25 ↩︎
Kyle Kingsbury. Call Me Maybe: Elasticsearch. aphyr.com, June 2014. perma.cc/JK47-S89J ↩︎
Salvatore Sanfilippo. A Few Arguments About Redis Sentinel Properties and Fail Scenarios. antirez.com, October 2014. perma.cc/8XEU-CLM8 ↩︎
Nicolas Liochon. CAP: If All You Have Is a Timeout, Everything Looks Like a Partition. blog.thislongrun.com, May 2015. Archived at perma.cc/FS57-V2PZ ↩︎
Matthew P. Grosvenor, Malte Schwarzkopf, Ionel Gog, Robert N. M. Watson, Andrew W. Moore, Steven Hand, and Jon Crowcroft. Queues Don’t Matter When You Can JUMP Them! At 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015. ↩︎ ↩︎
Theo Julienne. Debugging network stalls on Kubernetes. github.blog, November 2019. Archived at perma.cc/K9M8-XVGL ↩︎
Guohui Wang and T. S. Eugene Ng. The Impact of Virtualization on Network Performance of Amazon EC2 Data Center. At 29th IEEE International Conference on Computer Communications (INFOCOM), March 2010. doi:10.1109/INFCOM.2010.5461931 ↩︎ ↩︎
Brandon Philips. etcd: Distributed Locking and Service Discovery. At Strange Loop, September 2014. ↩︎
Steve Newman. A Systematic Look at EC2 I/O. blog.scalyr.com, October 2012. Archived at perma.cc/FL4R-H2VE ↩︎ ↩︎
Naohiro Hayashibara, Xavier Défago, Rami Yared, and Takuya Katayama. The ϕ Accrual Failure Detector. Japan Advanced Institute of Science and Technology, School of Information Science, Technical Report IS-RR-2004-010, May 2004. Archived at perma.cc/NSM2-TRYA ↩︎
Jeffrey Wang. Phi Accrual Failure Detector. ternarysearch.blogspot.co.uk, August 2013. perma.cc/L452-AMLV ↩︎
Srinivasan Keshav. An Engineering Approach to Computer Networking: ATM Networks, the Internet, and the Telephone Network. Addison-Wesley Professional, May 1997. ISBN: 978-0-201-63442-6 ↩︎ ↩︎
Othmar Kyas. ATM Networks. International Thomson Publishing, 1995. ISBN: 978-1-850-32128-6 ↩︎
Mellanox Technologies. InfiniBand FAQ, Rev 1.3. network.nvidia.com, December 2014. Archived at perma.cc/LQJ4-QZVK ↩︎
Jose Renato Santos, Yoshio Turner, and G. (John) Janakiraman. End-to-End Congestion Control for InfiniBand. At 22nd Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM), April 2003. Also published by HP Laboratories Palo Alto, Tech Report HPL-2002-359. doi:10.1109/INFCOM.2003.1208949 ↩︎
Jialin Li, Naveen Kr. Sharma, Dan R. K. Ports, and Steven D. Gribble. Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency. At ACM Symposium on Cloud Computing (SOCC), November 2014. doi:10.1145/2670979.2670988 ↩︎
Ulrich Windl, David Dalton, Marc Martinec, and Dale R. Worley. The NTP FAQ and HOWTO. ntp.org, November 2006. ↩︎ ↩︎ ↩︎
John Graham-Cumming. How and why the leap second affected Cloudflare DNS. blog.cloudflare.com, January 2017. Archived at archive.org ↩︎ ↩︎
David Holmes. Inside the Hotspot VM: Clocks, Timers and Scheduling Events – Part I – Windows. blogs.oracle.com, October 2006. Archived at archive.org ↩︎
Joran Dirk Greef. Three Clocks are Better than One. tigerbeetle.com, August 2021. Archived at perma.cc/5RXG-EU6B ↩︎
Oliver Yang. Pitfalls of TSC usage. oliveryang.net, September 2015. Archived at perma.cc/Z2QY-5FRA ↩︎
Steve Loughran. Time on Multi-Core, Multi-Socket Servers. steveloughran.blogspot.co.uk, September 2015. Archived at perma.cc/7M4S-D4U6 ↩︎
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. Spanner: Google’s Globally-Distributed Database. At 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012. ↩︎ ↩︎ ↩︎
M. Caporaloni and R. Ambrosini. How Closely Can a Personal Computer Clock Track the UTC Timescale Via the Internet? European Journal of Physics, volume 23, issue 4, pages L17–L21, June 2012. doi:10.1088/0143-0807/23/4/103 ↩︎
Nelson Minar. A Survey of the NTP Network. alumni.media.mit.edu, December 1999. Archived at perma.cc/EV76-7ZV3 ↩︎
Viliam Holub. Synchronizing Clocks in a Cassandra Cluster Pt. 1 – The Problem. blog.rapid7.com, March 2014. Archived at perma.cc/N3RV-5LNL ↩︎
Poul-Henning Kamp. The One-Second War (What Time Will You Die?) ACM Queue, volume 9, issue 4, pages 44–48, April 2011. doi:10.1145/1966989.1967009 ↩︎
Nelson Minar. Leap Second Crashes Half the Internet. somebits.com, July 2012. Archived at perma.cc/2WB8-D6EU ↩︎
Christopher Pascoe. Time, Technology and Leaping Seconds. googleblog.blogspot.co.uk, September 2011. Archived at perma.cc/U2JL-7E74 ↩︎
Mingxue Zhao and Jeff Barr. Look Before You Leap – The Coming Leap Second and AWS. aws.amazon.com, May 2015. Archived at perma.cc/KPE9-XMFM ↩︎
Darryl Veitch and Kanthaiah Vijayalayan. Network Timing and the 2015 Leap Second. At 17th International Conference on Passive and Active Measurement (PAM), April 2016. doi:10.1007/978-3-319-30505-9_29 ↩︎
VMware, Inc. Timekeeping in VMware Virtual Machines. vmware.com, October 2008. Archived at perma.cc/HM5R-T5NF ↩︎
Victor Yodaiken. Clock Synchronization in Finance and Beyond. yodaiken.com, November 2017. Archived at perma.cc/9XZD-8ZZN ↩︎
Mustafa Emre Acer, Emily Stark, Adrienne Porter Felt, Sascha Fahl, Radhika Bhargava, Bhanu Dev, Matt Braithwaite, Ryan Sleevi, and Parisa Tabriz. Where the Wild Warnings Are: Root Causes of Chrome HTTPS Certificate Errors. At ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 1407–1420, October 2017. doi:10.1145/3133956.3134007 ↩︎
European Securities and Markets Authority. MiFID II / MiFIR: Regulatory Technical and Implementing Standards – Annex I. esma.europa.eu, Report ESMA/2015/1464, September 2015. Archived at perma.cc/ZLX9-FGQ3 ↩︎
Luke Bigum. Solving MiFID II Clock Synchronisation With Minimum Spend (Part 1). catach.blogspot.com, November 2015. Archived at perma.cc/4J5W-FNM4 ↩︎
Oleg Obleukhov and Ahmad Byagowi. How Precision Time Protocol is being deployed at Meta. engineering.fb.com, November 2022. Archived at perma.cc/29G6-UJNW ↩︎
John Wiseman. gpsjam.org, July 2022. ↩︎
Josh Levinson, Julien Ridoux, and Chris Munns. It’s About Time: Microsecond-Accurate Clocks on Amazon EC2 Instances. aws.amazon.com, November 2023. Archived at perma.cc/56M6-5VMZ ↩︎
Kyle Kingsbury. Call Me Maybe: Cassandra. aphyr.com, September 2013. Archived at perma.cc/4MBR-J96V ↩︎ ↩︎ ↩︎
John Daily. Clocks Are Bad, or, Welcome to the Wonderful World of Distributed Systems. riak.com, November 2013. Archived at perma.cc/4XB5-UCXY ↩︎ ↩︎
Marc Brooker. It’s About Time! brooker.co.za, November 2023. Archived at perma.cc/N6YK-DRPA ↩︎
Kyle Kingsbury. The Trouble with Timestamps. aphyr.com, October 2013. Archived at perma.cc/W3AM-5VAV ↩︎
Leslie Lamport. Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, volume 21, issue 7, pages 558–565, July 1978. doi:10.1145/359545.359563 ↩︎
Justin Sheehy. There Is No Now: Problems With Simultaneity in Distributed Systems. ACM Queue, volume 13, issue 3, pages 36–41, March 2015. doi:10.1145/2733108 ↩︎
Murat Demirbas. Spanner: Google’s Globally-Distributed Database. muratbuffalo.blogspot.co.uk, July 2013. Archived at perma.cc/6VWR-C9WB ↩︎
Dahlia Malkhi and Jean-Philippe Martin. Spanner’s Concurrency Control. ACM SIGACT News, volume 44, issue 3, pages 73–77, September 2013. doi:10.1145/2527748.2527767 ↩︎
Franck Pachot. Achieving Precise Clock Synchronization on AWS. yugabyte.com, December 2024. Archived at perma.cc/UYM6-RNBS ↩︎
Spencer Kimball. Living Without Atomic Clocks: Where CockroachDB and Spanner diverge. cockroachlabs.com, January 2022. Archived at perma.cc/AWZ7-RXFT ↩︎
Murat Demirbas. Use of Time in Distributed Databases (part 4): Synchronized clocks in production databases. muratbuffalo.blogspot.com, January 2025. Archived at perma.cc/9WNX-Q9U3 ↩︎
Cary G. Gray and David R. Cheriton. Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency. At 12th ACM Symposium on Operating Systems Principles (SOSP), December 1989. doi:10.1145/74850.74870 ↩︎
Daniel Sturman, Scott Delap, Max Ross, et al. Roblox Return to Service. corp.roblox.com, January 2022. Archived at perma.cc/8ALT-WAS4 ↩︎
Todd Lipcon. Avoiding Full GCs with MemStore-Local Allocation Buffers. slideshare.net, February 2011. Archived at https://perma.cc/CH62-2EWJ ↩︎
Christopher Clark, Keir Fraser, Steven Hand, Jacob Gorm Hansen, Eric Jul, Christian Limpach, Ian Pratt, and Andrew Warfield. Live Migration of Virtual Machines. At 2nd USENIX Symposium on Symposium on Networked Systems Design & Implementation (NSDI), May 2005. ↩︎
Mike Shaver. fsyncers and Curveballs. shaver.off.net, May 2008. Archived at archive.org ↩︎
Zhenyun Zhuang and Cuong Tran. Eliminating Large JVM GC Pauses Caused by Background IO Traffic. engineering.linkedin.com, February 2016. Archived at perma.cc/ML2M-X9XT ↩︎
Martin Thompson. Java Garbage Collection Distilled. mechanical-sympathy.blogspot.co.uk, July 2013. Archived at perma.cc/DJT3-NQLQ ↩︎ ↩︎
David Terei and Amit Levy. Blade: A Data Center Garbage Collector. arXiv:1504.02578, April 2015. ↩︎
Martin Maas, Tim Harris, Krste Asanović, and John Kubiatowicz. Trash Day: Coordinating Garbage Collection in Distributed Systems. At 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015. ↩︎
Martin Fowler. The LMAX Architecture. martinfowler.com, July 2011. Archived at perma.cc/5AV4-N6RJ ↩︎
Joseph Y. Halpern and Yoram Moses. Knowledge and common knowledge in a distributed environment. Journal of the ACM (JACM), volume 37, issue 3, pages 549–587, July 1990. doi:10.1145/79147.79161 ↩︎ ↩︎
Chuzhe Tang, Zhaoguo Wang, Xiaodong Zhang, Qianmian Yu, Binyu Zang, Haibing Guan, and Haibo Chen. Ad Hoc Transactions in Web Applications: The Good, the Bad, and the Ugly. At ACM International Conference on Management of Data (SIGMOD), June 2022. doi:10.1145/3514221.3526120 ↩︎
Flavio P. Junqueira and Benjamin Reed. ZooKeeper: Distributed Process Coordination. O’Reilly Media, 2013. ISBN: 978-1-449-36130-3 ↩︎ ↩︎
Enis Söztutar. HBase and HDFS: Understanding Filesystem Usage in HBase. At HBaseCon, June 2013. Archived at perma.cc/4DXR-9P88 ↩︎
SUSE LLC. SUSE Linux Enterprise High Availability 15 SP6 Administration Guide, Section 12: Fencing and STONITH. documentation.suse.com, March 2025. Archived at perma.cc/8LAR-EL9D ↩︎
Mike Burrows. The Chubby Lock Service for Loosely-Coupled Distributed Systems. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006. ↩︎
Kyle Kingsbury. etcd 3.4.3. jepsen.io, January 2020. Archived at perma.cc/2P3Y-MPWU ↩︎
Ensar Basri Kahveci. Distributed Locks are Dead; Long Live Distributed Locks! hazelcast.com, April 2019. Archived at perma.cc/7FS5-LDXE ↩︎
Martin Kleppmann. How to do distributed locking. martin.kleppmann.com, February 2016. Archived at perma.cc/Y24W-YQ5L ↩︎
Salvatore Sanfilippo. Is Redlock safe? antirez.com, February 2016. Archived at perma.cc/B6GA-9Q6A ↩︎
Gunnar Morling. Leader Election With S3 Conditional Writes. www.morling.dev, August 2024. Archived at perma.cc/7V2N-J78Y ↩︎
Leslie Lamport, Robert Shostak, and Marshall Pease. The Byzantine Generals Problem. ACM Transactions on Programming Languages and Systems (TOPLAS), volume 4, issue 3, pages 382–401, July 1982. doi:10.1145/357172.357176 ↩︎
Jim N. Gray. Notes on Data Base Operating Systems. in Operating Systems: An Advanced Course, Lecture Notes in Computer Science, volume 60, edited by R. Bayer, R. M. Graham, and G. Seegmüller, pages 393–481, Springer-Verlag, 1978. ISBN: 978-3-540-08755-7. Archived at perma.cc/7S9M-2LZU ↩︎
Brian Palmer. How Complicated Was the Byzantine Empire? slate.com, October 2011. Archived at perma.cc/AN7X-FL3N ↩︎
Leslie Lamport. My Writings. lamport.azurewebsites.net, December 2014. Archived at perma.cc/5NNM-SQGR ↩︎
John Rushby. Bus Architectures for Safety-Critical Embedded Systems. At 1st International Workshop on Embedded Software (EMSOFT), October 2001. doi:10.1007/3-540-45449-7_22 ↩︎ ↩︎
Jake Edge. ELC: SpaceX Lessons Learned. lwn.net, March 2013. Archived at perma.cc/AYX8-QP5X ↩︎
Shehar Bano, Alberto Sonnino, Mustafa Al-Bassam, Sarah Azouvi, Patrick McCorry, Sarah Meiklejohn, and George Danezis. SoK: Consensus in the Age of Blockchains. At 1st ACM Conference on Advances in Financial Technologies (AFT), October 2019. doi:10.1145/3318041.3355458 ↩︎
Ezra Feilden, Adi Oltean, and Philip Johnston. Why we should train AI in space. White Paper, starcloud.com, September 2024. Archived at perma.cc/7Y3S-8UB6 ↩︎
James Mickens. The Saddest Moment. USENIX ;login, May 2013. Archived at perma.cc/T7BZ-XCFR ↩︎
Martin Kleppmann and Heidi Howard. Byzantine Eventual Consistency and the Fundamental Limits of Peer-to-Peer Databases. arxiv.org, December 2020. doi:10.48550/arXiv.2012.00472 ↩︎
Martin Kleppmann. Making CRDTs Byzantine Fault Tolerant. At 9th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC), April 2022. doi:10.1145/3517209.3524042 ↩︎
Evan Gilman. The Discovery of Apache ZooKeeper’s Poison Packet. pagerduty.com, May 2015. Archived at perma.cc/RV6L-Y5CQ ↩︎ ↩︎
Jonathan Stone and Craig Partridge. When the CRC and TCP Checksum Disagree. At ACM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (SIGCOMM), August 2000. doi:10.1145/347059.347561 ↩︎
Evan Jones. How Both TCP and Ethernet Checksums Fail. evanjones.ca, October 2015. Archived at perma.cc/9T5V-B8X5 ↩︎
Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer. Consensus in the Presence of Partial Synchrony. Journal of the ACM, volume 35, issue 2, pages 288–323, April 1988. doi:10.1145/42282.42283 ↩︎ ↩︎ ↩︎
Richard D. Schlichting and Fred B. Schneider. Fail-stop processors: an approach to designing fault-tolerant computing systems. ACM Transactions on Computer Systems (TOCS), volume 1, issue 3, pages 222–238, August 1983. doi:10.1145/357369.357371 ↩︎
Thanh Do, Mingzhe Hao, Tanakorn Leesatapornwongsa, Tiratat Patana-anake, and Haryadi S. Gunawi. Limplock: Understanding the Impact of Limpware on Scale-out Cloud Systems. At 4th ACM Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523627 ↩︎
Josh Snyder and Joseph Lynch. Garbage collecting unhealthy JVMs, a proactive approach. Netflix Technology Blog, netflixtechblog.medium.com, November 2019. Archived at perma.cc/8BTA-N3YB ↩︎
Haryadi S. Gunawi, Riza O. Suminto, Russell Sears, Casey Golliher, Swaminathan Sundararaman, Xing Lin, Tim Emami, Weiguang Sheng, Nematollah Bidokhti, Caitie McCaffrey, Gary Grider, Parks M. Fields, Kevin Harms, Robert B. Ross, Andree Jacobson, Robert Ricci, Kirk Webb, Peter Alvaro, H. Birali Runesha, Mingzhe Hao, and Huaicheng Li. Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems. At 16th USENIX Conference on File and Storage Technologies, February 2018. ↩︎
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. At 16th Workshop on Hot Topics in Operating Systems (HotOS), May 2017. doi:10.1145/3102980.3103005 ↩︎
Chang Lou, Peng Huang, and Scott Smith. Understanding, Detecting and Localizing Partial Failures in Large System Software. At 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), February 2020. ↩︎
Peter Bailis and Ali Ghodsi. Eventual Consistency Today: Limitations, Extensions, and Beyond. ACM Queue, volume 11, issue 3, pages 55-63, March 2013. doi:10.1145/2460276.2462076 ↩︎
Bowen Alpern and Fred B. Schneider. Defining Liveness. Information Processing Letters, volume 21, issue 4, pages 181–185, October 1985. doi:10.1016/0020-0190(85)90056-0 ↩︎
Flavio P. Junqueira. Dude, Where’s My Metadata? fpj.me, May 2015. Archived at perma.cc/D2EU-Y9S5 ↩︎
Scott Sanders. January 28th Incident Report. github.com, February 2016. Archived at perma.cc/5GZR-88TV ↩︎
Jay Kreps. A Few Notes on Kafka and Jepsen. blog.empathybox.com, September 2013. perma.cc/XJ5C-F583 ↩︎
Marc Brooker and Ankush Desai. Systems Correctness Practices at AWS. Queue, Volume 22, Issue 6, November/December 2024. doi:10.1145/3712057 ↩︎
Andrey Satarin. Testing Distributed Systems: Curated list of resources on testing distributed systems. asatarin.github.io. Archived at perma.cc/U5V8-XP24 ↩︎
Jack Vanlightly. Verifying Kafka transactions - Diary entry 2 - Writing an initial TLA+ spec. jack-vanlightly.com, December 2024. Archived at perma.cc/NSQ8-MQ5N ↩︎
Siddon Tang. From Chaos to Order — Tools and Techniques for Testing TiDB, A Distributed NewSQL Database. pingcap.com, April 2018. Archived at perma.cc/5EJB-R29F ↩︎
Nathan VanBenschoten. Parallel Commits: An atomic commit protocol for globally distributed transactions. cockroachlabs.com, November 2019. Archived at perma.cc/5FZ7-QK6J ↩︎
Jack Vanlightly. Paper: VR Revisited - State Transfer (part 3). jack-vanlightly.com, December 2022. Archived at perma.cc/KNK3-K6WS ↩︎
Hillel Wayne. What if the spec doesn’t match the code? buttondown.com, March 2024. Archived at perma.cc/8HEZ-KHER ↩︎
Lingzhi Ouyang, Xudong Sun, Ruize Tang, Yu Huang, Madhav Jivrajani, Xiaoxing Ma, Tianyin Xu. Multi-Grained Specifications for Distributed System Model Checking and Verification. At 20th European Conference on Computer Systems (EuroSys), March 2025. doi:10.1145/3689031.3696069 ↩︎
Yury Izrailevsky and Ariel Tseitlin. The Netflix Simian Army. netflixtechblog.com, July, 2011. Archived at perma.cc/M3NY-FJW6 ↩︎
Kyle Kingsbury. Jepsen: On the perils of network partitions. aphyr.com, May, 2013. Archived at perma.cc/W98G-6HQP ↩︎
Kyle Kingsbury. Jepsen Analyses. jepsen.io, 2024. Archived at perma.cc/8LDN-D2T8 ↩︎
Rupak Majumdar and Filip Niksic. Why is random testing effective for partition tolerance bugs? Proceedings of the ACM on Programming Languages (PACMPL), volume 2, issue POPL, article no. 46, December 2017. doi:10.1145/3158134 ↩︎
FoundationDB project authors. Simulation and Testing. apple.github.io. Archived at perma.cc/NQ3L-PM4C ↩︎
Alex Kladov. Simulation Testing For Liveness. tigerbeetle.com, July 2023. Archived at perma.cc/RKD4-HGCR ↩︎
Alfonso Subiotto Marqués. (Mostly) Deterministic Simulation Testing in Go. polarsignals.com, May 2024. Archived at perma.cc/ULD6-TSA4 ↩︎