6. 复制
可能出错的东西和“不可能”出错的东西之间,最大的区别在于:后者一旦出错,往往几乎无从下手,也难以修复。
道格拉斯·亚当斯,《基本无害》(1992)
复制 指的是在通过网络连接的多台机器上保留相同数据的副本。如 “分布式与单节点系统” 中所讨论的,你可能出于以下几个原因希望复制数据:
- 使数据在地理上更接近用户(从而减少访问延迟)
- 即使系统的部分组件出现故障,也能让系统继续工作(从而提高可用性)
- 扩展能够处理读查询的机器数量(从而提高读吞吐量)
本章假设你的数据集足够小,每台机器都可以保存整个数据集的副本。在 第 7 章 中,我们将放宽这一假设,讨论单台机器无法容纳的、过大数据集的 分片(分区)。在后续章节中,我们将讨论复制数据系统中可能发生的各种故障,以及如何处理它们。
如果需要复制的数据不会随时间变化,那么复制就很简单:只需要将数据复制到每个节点一次就大功告成。处理复制的所有困难都在于处理复制数据的 变更,这也是本章的主题。我们将讨论三类在节点之间复制变更的算法:单主、多主 和 无主 复制。几乎所有分布式数据库都使用这三种方法之一。它们各有利弊,我们将详细研究。
复制需要考虑许多权衡:例如,是使用同步还是异步复制,以及如何处理失败的副本。这些通常是数据库中的配置选项,尽管不同数据库的细节有所不同,但许多不同实现的通用原则是相似的。我们将在本章中讨论这些选择的后果。
数据库复制是一个古老的话题——自 20 世纪 70 年代研究以来,原理并没有太大变化 1,因为网络的基本约束保持不变。尽管如此古老,像 最终一致性 这样的概念仍然会引起困惑。在 “复制延迟的问题” 中,我们将更准确地了解最终一致性,并讨论诸如 读己之写 和 单调读 等保证。
备份与复制
你可能会想,如果有了复制,是否还需要备份。答案是肯定的,因为它们有不同的目的:副本会快速将一个节点的写入反映到其他节点上,但备份存储数据的旧快照,以便你可以回到过去的时间点。如果你不小心删除了一些数据,复制并不能帮助你,因为删除操作也会传播到副本,所以如果你想恢复被删除的数据,就需要备份。
事实上,复制和备份通常是相互补充的。备份有时是设置复制过程的一部分,正如我们将在 “设置新的副本” 中看到的。反过来,归档复制日志可以成为备份过程的一部分。
一些数据库在内部维护过去状态的不可变快照,作为一种内部备份。然而,这意味着在与当前状态相同的存储介质上保留数据的旧版本。如果你有大量数据,将旧数据的备份保存在针对不常访问数据优化的对象存储中可能会更便宜,而只在主存储中存储数据库的当前状态。
单主复制
存储数据库副本的每个节点称为 副本。有了多个副本,不可避免地会出现一个问题:我们如何确保所有数据最终都出现在所有副本上?
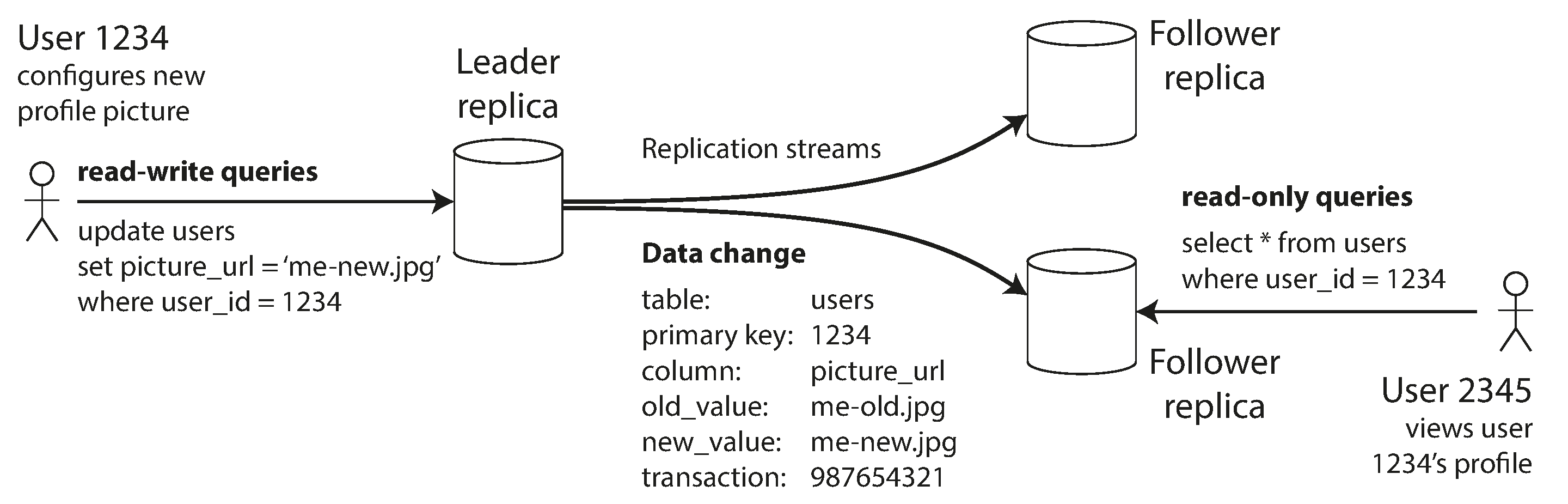
每次写入数据库都需要由每个副本处理;否则,副本将不再包含相同的数据。最常见的解决方案称为 基于领导者的复制、主备复制 或 主动/被动复制。它的工作原理如下(见 图 6-1):
- 其中一个副本被指定为 领导者(也称为 主库 或 源 2)。当客户端想要写入数据库时,他们必须将请求发送给领导者,领导者首先将新数据写入其本地存储。
- 其他副本称为 追随者(只读副本、从库 或 热备)。每当领导者将新数据写入其本地存储时,它也会将数据变更作为 复制日志 或 变更流 的一部分发送给所有追随者。每个追随者从领导者获取日志,并通过按照与领导者处理相同的顺序应用所有写入来相应地更新其本地数据库副本。
- 当客户端想要从数据库读取时,它可以查询领导者或任何追随者。然而,只有领导者接受写入(从客户端的角度来看,追随者是只读的)。
如果数据库是分片的(见 第 7 章),每个分片都有一个领导者。不同的分片可能在不同的节点上有其领导者,但每个分片仍必须有一个领导者。在 “多主复制” 中,我们将讨论一种替代模型,其中系统可能同时为同一分片拥有多个领导者。
单主复制被广泛使用。它是许多关系数据库的内置功能,如 PostgreSQL、MySQL、Oracle Data Guard 3 和 SQL Server 的 Always On 可用性组 4。它也用于一些文档数据库,如 MongoDB 和 DynamoDB 5,消息代理如 Kafka,复制块设备如 DRBD,以及一些网络文件系统。许多共识算法(如 Raft)也基于单个领导者,用于 CockroachDB 6、TiDB 7、etcd 和 RabbitMQ 仲裁队列(以及其他)中的复制,并在旧领导者失败时自动选举新领导者(我们将在 第 10 章 中更详细地讨论共识)。
Note
在较旧的文档中,你可能会看到术语 主从复制。它与基于领导者的复制含义相同,但应该避免使用该术语,因为它被广泛认为是冒犯性的 8。
同步复制与异步复制
复制系统的一个重要细节是复制是 同步 发生还是 异步 发生。(在关系数据库中,这通常是一个可配置选项;其他系统通常硬编码为其中之一。)
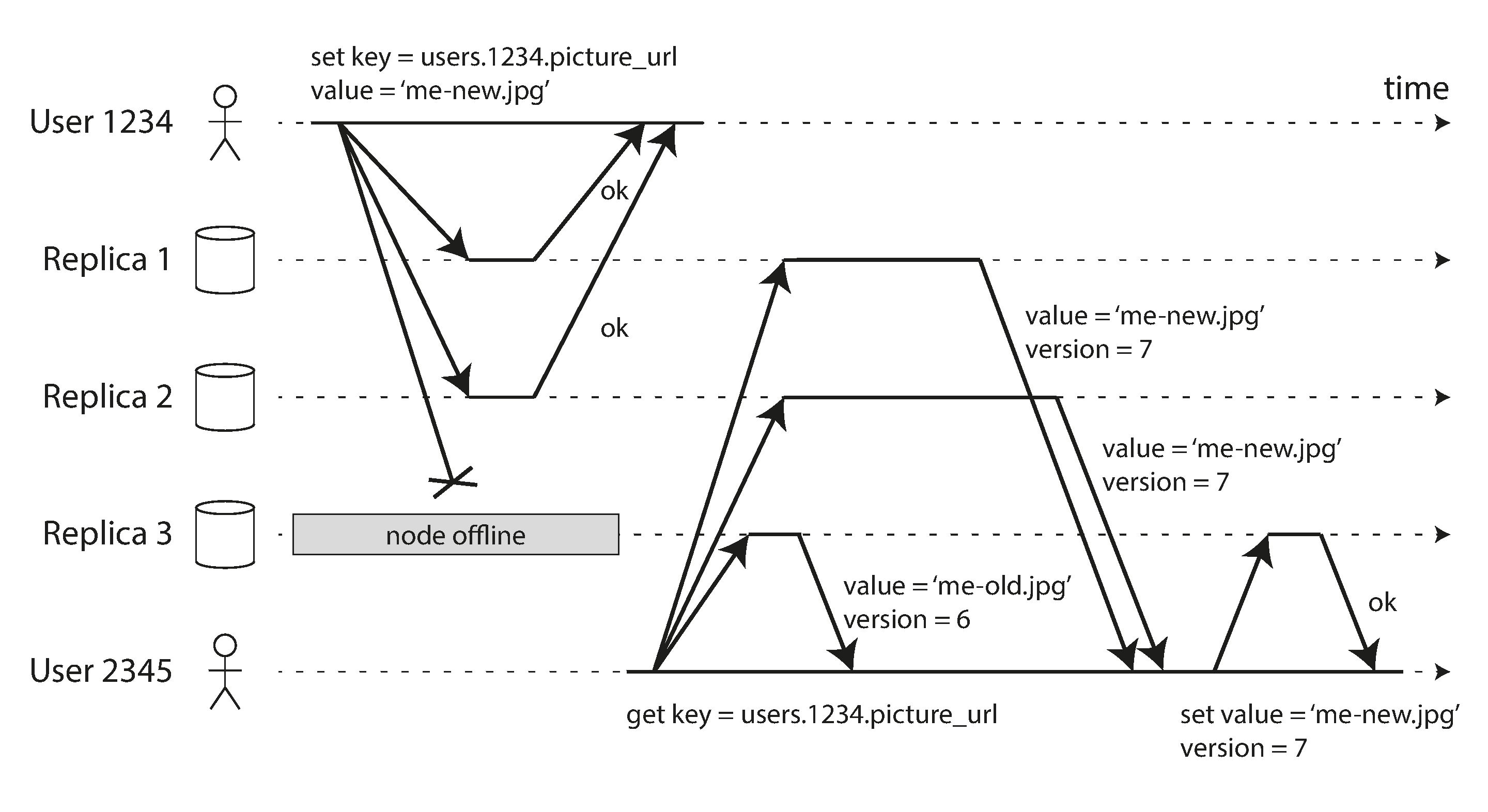
想想 图 6-1 中发生的情况,一个网站用户更新他们的个人资料图片。在某个时间点,客户端向领导者发送更新请求;不久之后,领导者收到了它。在某个时间点,领导者将数据变更转发给追随者。最终,领导者通知客户端更新成功。图 6-2 显示了时序可能的工作方式。
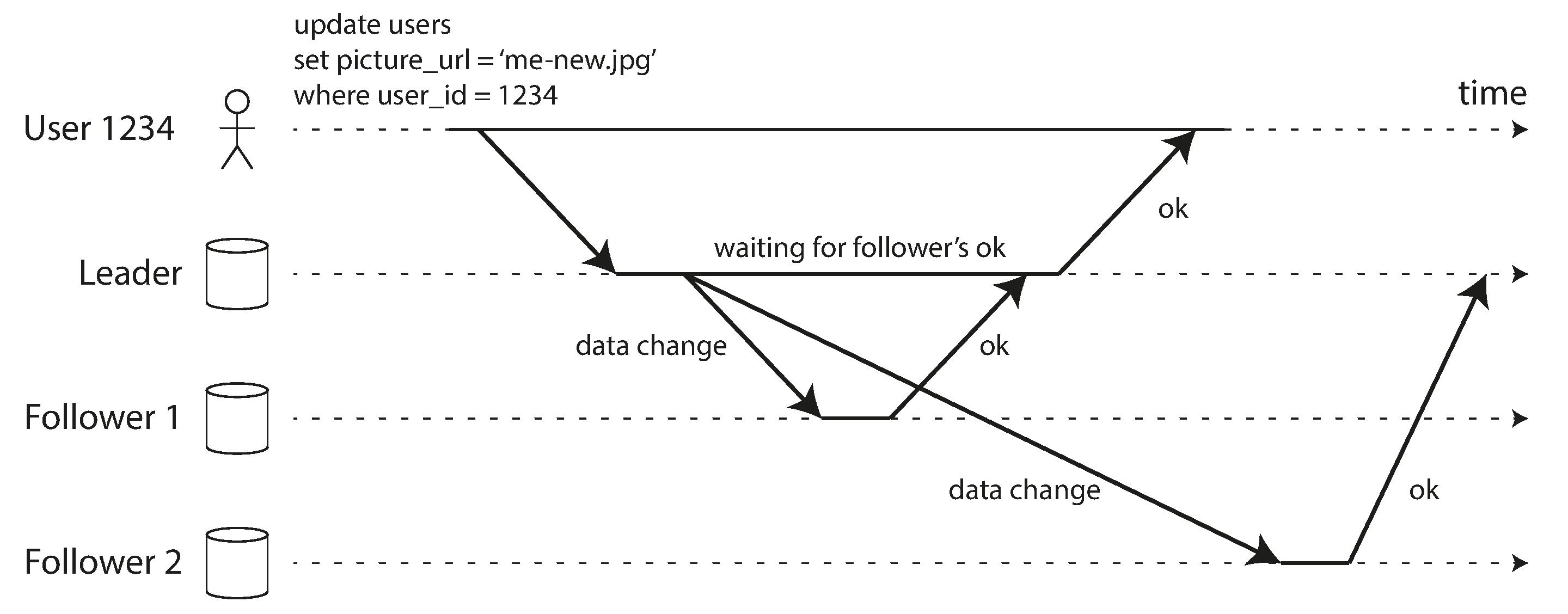
在 图 6-2 的示例中,对追随者 1 的复制是 同步的:领导者等待追随者 1 确认它已收到写入,然后才向用户报告成功,并使写入对其他客户端可见。对追随者 2 的复制是 异步的:领导者发送消息,但不等待追随者的响应。
图中显示,追随者 2 处理消息之前有相当大的延迟。通常,复制相当快:大多数数据库系统在不到一秒的时间内将变更应用到追随者。然而,不能保证需要多长时间。在某些情况下,追随者可能落后领导者几分钟或更长时间;例如,如果追随者正在从故障中恢复,如果系统正在接近最大容量运行,或者如果节点之间存在网络问题。
同步复制的优点是追随者保证拥有与领导者一致的最新数据副本。如果领导者突然失败,我们可以确信数据仍然在追随者上可用。缺点是,如果同步追随者没有响应(因为它已崩溃,或存在网络故障,或任何其他原因),写入就无法处理。领导者必须阻塞所有写入并等待同步副本再次可用。
因此,将所有追随者都设为同步是不切实际的:任何一个节点的中断都会导致整个系统停止。实际上,如果数据库提供同步复制,通常意味着 一个 追随者是同步的,其他的是异步的。如果同步追随者变得不可用或缓慢,异步追随者之一将变为同步。这保证了你至少在两个节点上拥有最新的数据副本:领导者和一个同步追随者。这种配置有时也称为 半同步。
在某些系统中,多数(例如,包括领导者在内的 5 个副本中的 3 个)副本被同步更新,其余少数是异步的。这是 仲裁 的一个例子,我们将在 “读写仲裁” 中进一步讨论。多数仲裁通常用于使用共识协议进行自动领导者选举的系统中,我们将在 第 10 章 中回到这个话题。
有时,基于领导者的复制被配置为完全异步。在这种情况下,如果领导者失败且无法恢复,任何尚未复制到追随者的写入都会丢失。这意味着即使已向客户端确认,写入也不能保证持久。然而,完全异步配置的优点是领导者可以继续处理写入,即使所有追随者都已落后。
弱化持久性可能听起来像是一个糟糕的权衡,但异步复制仍然被广泛使用,特别是如果有许多追随者或者它们在地理上分布广泛 9。我们将在 “复制延迟的问题” 中回到这个问题。
设置新的副本
不时地,你需要设置新的追随者——也许是为了增加副本的数量,或者替换失败的节点。如何确保新的追随者拥有领导者数据的准确副本?
简单地将数据文件从一个节点复制到另一个节点通常是不够的:客户端不断向数据库写入,数据总是在变化,所以标准文件复制会在不同的时间点看到数据库的不同部分。结果可能没有任何意义。
你可以通过锁定数据库(使其不可用于写入)来使磁盘上的文件保持一致,但这将违背我们的高可用性目标。幸运的是,设置追随者通常可以在不停机的情况下完成。从概念上讲,过程如下所示:
- 在某个时间点获取领导者数据库的一致快照——如果可能,不锁定整个数据库。大多数数据库都有此功能,因为备份也需要它。在某些情况下,需要第三方工具,例如用于 MySQL 的 Percona XtraBackup。
- 将快照复制到新的追随者。
- 追随者连接到领导者并请求自快照拍摄以来发生的所有数据变更。这要求快照与领导者复制日志中的确切位置相关联。该位置有各种名称:例如,PostgreSQL 称之为 日志序列号;MySQL 有两种机制,binlog 位点 和 全局事务标识符(GTID)。
- 当追随者处理了自快照以来的数据变更积压后,我们说它已经 追上进度。它现在可以继续处理领导者发生的数据变更。
设置追随者的实际步骤因数据库而异。在某些系统中,该过程是完全自动化的,而在其他系统中,它可能是需要管理员手动执行的有些神秘的多步骤工作流程。
你也可以将复制日志归档到对象存储;连同对象存储中整个数据库的定期快照,这是实现数据库备份和灾难恢复的好方法。你还可以通过从对象存储下载这些文件来执行设置新追随者的步骤 1 和 2。例如,WAL-G 为 PostgreSQL、MySQL 和 SQL Server 执行此操作,Litestream 为 SQLite 执行等效操作。
由对象存储支持的数据库
对象存储可用于存档数据之外的更多用途。许多数据库开始使用对象存储(如 Amazon Web Services S3、Google Cloud Storage 和 Azure Blob Storage)来为实时查询提供数据。在对象存储中存储数据库数据有许多好处:
- 与其他云存储选项相比,对象存储价格便宜,这使得云数据库可以将较少查询的数据存储在更便宜、更高延迟的存储上,同时从内存、SSD 和 NVMe 中提供工作集。
- 对象存储还提供具有非常高持久性保证的多区域、双区域或多区域复制。这也允许数据库绕过跨区域网络费用。
- 数据库可以使用对象存储的 条件写入 功能——本质上是 比较并设置(CAS)操作——来实现事务和领导者选举 10 11
- 将来自多个数据库的数据存储在同一对象存储中可以简化数据集成,特别是在使用 Apache Parquet 和 Apache Iceberg 等开放格式时。
这些好处通过将事务、领导者选举和复制的责任转移到对象存储,大大简化了数据库架构。
采用对象存储进行复制的系统必须应对一些权衡。值得注意的是,对象存储的读写延迟比本地磁盘或 EBS 等虚拟块设备要高得多。许多云提供商还收取每个 API 调用费用,这迫使系统批量读写以降低成本。这种批处理进一步增加了延迟。此外,许多对象存储不提供标准文件系统接口。这阻止了缺乏对象存储集成的系统利用对象存储。像 用户空间文件系统(FUSE)这样的接口允许操作员将对象存储桶挂载为文件系统,应用程序可以在不知道其数据存储在对象存储上的情况下使用。尽管如此,许多对象存储的 FUSE 接口缺乏系统可能依赖的 POSIX 功能,如非顺序写入或符号链接。
不同的系统以各种方式处理这些权衡。一些引入了 分层存储 架构,将较少访问的数据放在对象存储上,而新的或频繁访问的数据保存在更快的存储设备上,如 SSD、NVMe,甚至内存中。其他系统使用对象存储作为其主要存储层,但使用单独的低延迟存储系统(如 Amazon 的 EBS 或 Neon 的 Safekeepers 12)来存储其 WAL。最近,一些系统更进一步,采用了 零磁盘架构(ZDA)。基于 ZDA 的系统将所有数据持久化到对象存储,并严格将磁盘和内存用于缓存。这允许节点没有持久状态,这大大简化了运维。WarpStream、Confluent Freight、Buf 的 Bufstream 和 Redpanda Serverless 都是使用零磁盘架构构建的兼容 Kafka 的系统。几乎每个现代云数据仓库也采用这种架构,Turbopuffer(向量搜索引擎)和 SlateDB(云原生 LSM 存储引擎)也是如此。
处理节点故障
系统中的任何节点都可能发生故障,可能是由于故障意外发生,但同样可能是由于计划维护(例如,重新启动机器以安装内核安全补丁)。能够在不停机的情况下重新启动单个节点对于操作和维护来说是一个很大的优势。因此,我们的目标是尽管单个节点发生故障,但保持整个系统运行,并尽可能减小节点中断的影响。
如何通过基于领导者的复制实现高可用性?
追随者故障:追赶恢复
在其本地磁盘上,每个追随者保留从领导者接收的数据变更日志。如果追随者崩溃并重新启动,或者如果领导者和追随者之间的网络暂时中断,追随者可以很容易地恢复:从其日志中,它知道在故障发生之前处理的最后一个事务。因此,追随者可以连接到领导者并请求在追随者断开连接期间发生的所有数据变更。当它应用了这些变更后,它就赶上了领导者,可以像以前一样继续接收数据变更流。
尽管追随者恢复在概念上很简单,但在性能方面可能具有挑战性:如果数据库具有高写入吞吐量,或者如果追随者已离线很长时间,可能有很多写入需要赶上。在进行这种追赶时,恢复的追随者和领导者(需要将写入积压发送到追随者)都会有高负载。
一旦所有追随者都确认已处理了日志,领导者就可以删除其写入日志,但如果追随者长时间不可用,领导者面临选择:要么保留日志直到追随者恢复并赶上(冒着领导者磁盘空间耗尽的风险),要么删除不可用追随者尚未确认的日志(在这种情况下,追随者无法从日志中恢复,并且在它回来时必须从备份中恢复)。
领导者故障:故障转移
处理领导者故障更加棘手:其中一个追随者需要被提升为新的领导者,客户端需要重新配置以将其写入发送到新的领导者,其他追随者需要开始从新的领导者消费数据变更。这个过程称为 故障转移。
故障转移可以手动发生(管理员收到领导者失败的通知并采取必要步骤来创建新的领导者)或自动发生。自动故障转移过程通常包括以下步骤:
- 确定领导者已失效。 可能会出现许多问题:崩溃、停电、网络故障等。没有万无一失的方法能准确判断发生了什么,所以大多数系统只是依赖超时:节点之间会频繁来回发送消息,如果某个节点在一段时间内(例如 30 秒)没有响应,就认为它已经失效。(如果是计划维护而主动下线领导者,则不适用。)
- 选择新的领导者。 这可以通过选举过程完成(由剩余副本中的多数选出领导者),也可以由预先设定的 控制器节点 任命 13。最适合担任领导者的通常是那个拥有旧领导者最新数据变更的副本(以尽量减少数据丢失)。让所有节点就新领导者达成一致是一个共识问题,我们会在 第 10 章 详细讨论。
- 将系统重新配置为使用新的领导者。 客户端现在需要把写请求发送到新领导者(我们在 “请求路由” 中讨论这个问题)。如果旧领导者恢复,它可能仍然以为自己是领导者,并不知道其他副本已经让它下台。系统需要确保旧领导者降级为追随者,并识别新的领导者。
故障转移充满了可能出错的事情:
- 如果使用异步复制,新的领导者可能在失败之前没有收到来自旧领导者的所有写入。如果前领导者在选择了新领导者后重新加入集群,那些写入应该怎么办?新的领导者可能同时收到了冲突的写入。最常见的解决方案是简单地丢弃旧领导者未复制的写入,这意味着你认为已提交的写入实际上并不持久。
- 如果数据库之外的其他存储系统需要与数据库内容协调,丢弃写入尤其危险。例如,在 GitHub 的一次事故中 14,一个过时的 MySQL 追随者被提升为领导者。数据库使用自增计数器为新行分配主键,但由于新领导者的计数器落后于旧领导者,它重用了旧领导者先前分配的一些主键。这些主键也在 Redis 存储中使用,因此主键的重用导致 MySQL 和 Redis 之间的不一致,这导致一些私人数据被错误地披露给错误的用户。
- 在某些故障场景中(见 第 9 章),可能会发生两个节点都认为自己是领导者的情况。这种情况称为 脑裂,这是危险的:如果两个领导者都接受写入,并且没有解决冲突的过程(见 “多主复制”),数据很可能会丢失或损坏。作为安全措施,一些系统在检测到两个领导者时有一种机制来关闭一个节点。然而,如果这种机制设计不当,你最终可能会关闭两个节点 15。此外,当检测到脑裂并关闭旧节点时,可能为时已晚,数据已经损坏。
- 在宣布领导者死亡之前,正确的超时是什么?更长的超时意味着在领导者失败的情况下恢复时间更长。然而,如果超时太短,可能会有不必要的故障转移。例如,临时负载峰值可能导致节点的响应时间增加到超时以上,或者网络故障可能导致数据包延迟。如果系统已经在高负载或网络问题上挣扎,不必要的故障转移可能会使情况变得更糟,而不是更好。
Note
通过限制或关闭旧领导者来防止脑裂,被称为 栅栏机制(fencing),或者更直白地说,爆彼之头(STONITH)。我们将在 “分布式锁和租约” 中更详细地讨论栅栏机制。
这些问题没有简单的解决方案。因此,一些运维团队更喜欢手动执行故障转移,即使软件支持自动故障转移。
故障转移最重要的是选择一个最新的追随者作为新的领导者——如果使用同步或半同步复制,这将是旧领导者在确认写入之前等待的追随者。使用异步复制,你可以选择具有最大日志序列号的追随者。这最小化了故障转移期间丢失的数据量:丢失几分之一秒的写入可能是可以容忍的,但选择落后几天的追随者可能是灾难性的。
这些问题——节点故障;不可靠的网络;以及围绕副本一致性、持久性、可用性和延迟的权衡——实际上是分布式系统中的基本问题。在 第 9 章 和 第 10 章 中,我们将更深入地讨论它们。
复制日志的实现
基于领导者的复制在底层是如何工作的?让我们简要地看看实践中使用的几种不同的复制方法。
基于语句的复制
在最简单的情况下,领导者记录它执行的每个写入请求(语句)并将该语句日志发送给其追随者。对于关系数据库,这意味着每个 INSERT、UPDATE 或 DELETE 语句都被转发到追随者,每个追随者解析并执行该 SQL 语句,就像它是从客户端接收的一样。
虽然这听起来合理,但这种复制方法可能会出现各种问题:
- 任何调用非确定性函数的语句,例如
NOW()获取当前日期和时间或RAND()获取随机数,可能会在每个副本上生成不同的值。 - 如果语句使用自增列,或者如果它们依赖于数据库中的现有数据(例如,
UPDATE … WHERE <某条件>),它们必须在每个副本上以完全相同的顺序执行,否则它们可能会产生不同的效果。当有多个并发执行的事务时,这可能会受到限制。 - 具有副作用的语句(例如,触发器、存储过程、用户定义的函数)可能会导致每个副本上发生不同的副作用,除非副作用是绝对确定的。
可以解决这些问题——例如,领导者可以在记录语句时用固定的返回值替换任何非确定性函数调用,以便追随者都获得相同的值。以固定顺序执行确定性语句的想法类似于我们之前在 “事件溯源与 CQRS” 中讨论的事件溯源模型。这种方法也称为 状态机复制,我们将在 “使用共享日志” 中讨论其背后的理论。
基于语句的复制在 MySQL 5.1 版本之前使用。它今天有时仍在使用,因为它相当紧凑,但默认情况下,如果语句中有任何非确定性,MySQL 现在会切换到基于行的复制(稍后讨论)。VoltDB 使用基于语句的复制,并通过要求事务是确定性的来使其安全 16。然而,确定性在实践中很难保证,因此许多数据库更喜欢其他复制方法。
预写日志(WAL)传输
在 第 4 章 中,我们看到预写日志是使 B 树存储引擎健壮所必需的:每个修改首先写入 WAL,以便在崩溃后可以将树恢复到一致状态。由于 WAL 包含将索引和堆恢复到一致状态所需的所有信息,我们可以使用完全相同的日志在另一个节点上构建副本:除了将日志写入磁盘外,领导者还通过网络将其发送给其追随者。当追随者处理此日志时,它构建了与领导者上找到的完全相同的文件副本。
此复制方法在 PostgreSQL 和 Oracle 等中使用 17 18。主要缺点是日志在非常低的级别描述数据:WAL 包含哪些字节在哪些磁盘块中被更改的详细信息。这使得复制与存储引擎紧密耦合。如果数据库从一个版本更改其存储格式到另一个版本,通常不可能在领导者和追随者上运行不同版本的数据库软件。
这可能看起来像是一个小的实现细节,但它可能会产生很大的操作影响。如果复制协议允许追随者使用比领导者更新的软件版本,你可以通过首先升级追随者然后执行故障转移以使其中一个升级的节点成为新的领导者来执行数据库软件的零停机升级。如果复制协议不允许此版本不匹配(如 WAL 传输的情况),此类升级需要停机。
逻辑(基于行)日志复制
另一种选择是为复制和存储引擎使用不同的日志格式,这允许复制日志与存储引擎内部解耦。这种复制日志称为 逻辑日志,以区别于存储引擎的(物理)数据表示。
关系数据库的逻辑日志通常是描述以行粒度对数据库表的写入的记录序列:
- 对于插入的行,日志包含所有列的新值。
- 对于删除的行,日志包含足够的信息来唯一标识被删除的行。通常这将是主键,但如果表上没有主键,则需要记录所有列的旧值。
- 对于更新的行,日志包含足够的信息来唯一标识更新的行,以及所有列的新值(或至少所有已更改的列的新值)。
修改多行的事务会生成多个这样的日志记录,后跟指示事务已提交的记录。MySQL 除了 WAL 之外还保留一个单独的逻辑复制日志,称为 binlog(当配置为使用基于行的复制时)。PostgreSQL 通过将物理 WAL 解码为行插入/更新/删除事件来实现逻辑复制 19。
由于逻辑日志与存储引擎内部解耦,因此可以更容易地保持向后兼容,允许领导者和追随者运行不同版本的数据库软件。这反过来又可以以最少的停机时间升级到新版本 20。
逻辑日志格式也更容易被外部应用解析。如果你想把数据库内容发送到外部系统(例如用于离线分析的数据仓库),或者构建自定义索引和缓存 21,这一点会很有用。这种技术称为 数据变更捕获,我们将在 “数据变更捕获” 一节再回到它。
复制延迟的问题
能够容忍节点故障只是想要复制的一个原因。如 “分布式与单节点系统” 中所述,其他原因是可伸缩性(处理比单台机器能够处理的更多请求)和延迟(将副本在地理上放置得更接近用户)。
基于领导者的复制要求所有写入都通过单个节点,但只读查询可以转到任何副本。对于主要由读取和只有少量写入组成的工作负载(这通常是在线服务的情况),有一个有吸引力的选择:创建许多追随者,并将读取请求分布在这些追随者上。这减轻了领导者的负载,并允许附近的副本提供读取请求。
在这种 读扩展 架构中,你可以通过添加更多追随者来简单地增加服务只读请求的容量。然而,这种方法只有在使用异步复制时才现实可行——如果你试图同步复制到所有追随者,单个节点故障或网络中断将使整个系统无法写入。而且你拥有的节点越多,其中一个节点宕机的可能性就越大,因此完全同步的配置将非常不可靠。
不幸的是,如果应用程序从 异步 追随者读取,如果追随者已落后,它可能会看到过时的信息。这导致数据库中出现明显的不一致:如果你同时在领导者和追随者上运行相同的查询,你可能会得到不同的结果,因为并非所有写入都已反映在追随者中。这种不一致只是一种临时状态——如果你停止向数据库写入并等待一段时间,追随者最终将赶上并与领导者保持一致。因此,这种效果被称为 最终一致性 22。
Note
术语"最终"是故意模糊的:一般来说,副本可以落后多远没有限制。在正常操作中,写入发生在领导者上并反映在追随者上之间的延迟——复制延迟——可能只是几分之一秒,在实践中不会被注意到。然而,如果系统在接近容量运行或网络中存在问题,延迟可以轻易增加到几秒甚至几分钟。
当延迟如此之大时,它引入的不一致不仅仅是一个理论问题,而是应用程序的真正问题。在本节中,我们将重点介绍复制延迟时可能发生的三个问题示例。我们还将概述解决它们的一些方法。
读己之写
许多应用程序让用户提交一些数据,然后查看他们提交的内容。这可能是客户数据库中的记录,或讨论线程上的评论,或其他类似的东西。提交新数据时,必须将其发送到领导者,但当用户查看数据时,可以从追随者读取。如果数据经常被查看但只是偶尔被写入,这尤其合适。
使用异步复制,存在一个问题,如 图 6-3 所示:如果用户在写入后不久查看数据,新数据可能尚未到达副本。对用户来说,看起来他们提交的数据丢失了,所以他们自然会不高兴。
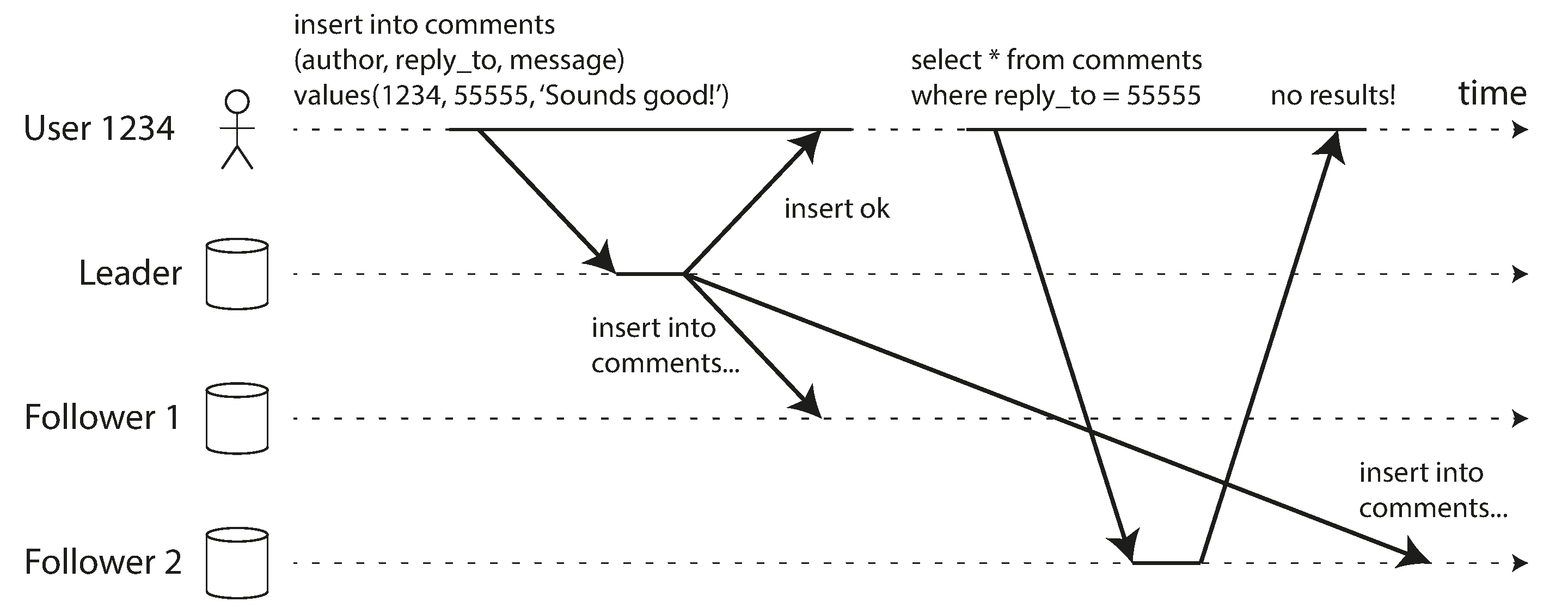
在这种情况下,我们需要 写后读一致性,也称为 读己之写一致性 23。这是一种保证,如果用户重新加载页面,他们将始终看到他们自己提交的任何更新。它不对其他用户做出承诺:其他用户的更新可能直到稍后才可见。然而,它向用户保证他们自己的输入已正确保存。
我们如何在基于领导者的复制系统中实现写后读一致性?有各种可能的技术。下面举几个例子:
- 当读取用户可能已修改的内容时,从领导者或同步更新的追随者读取;否则,从异步更新的追随者读取。这要求你有某种方法知道某物是否可能已被修改,而无需实际查询它。例如,社交网络上的用户个人资料信息通常只能由个人资料的所有者编辑,而不能由其他任何人编辑。因此,一个简单的规则是:始终从领导者读取用户自己的个人资料,从追随者读取任何其他用户的个人资料。
- 如果应用程序中的大多数东西都可能被用户编辑,那种方法将不会有效,因为大多数东西都必须从领导者读取(否定了读扩展的好处)。在这种情况下,可以使用其他标准来决定是否从领导者读取。例如,你可以跟踪上次更新的时间,并在上次更新后的一分钟内,使所有读取都来自领导者 25。你还可以监控追随者上的复制延迟,并防止在落后领导者超过一分钟的任何追随者上进行查询。
- 客户端可以记住其最近写入的时间戳——然后系统可以确保为该用户提供任何读取的副本至少反映该时间戳之前的更新。如果副本不够最新,则可以由另一个副本处理读取,或者查询可以等待直到副本赶上 26。时间戳可以是 逻辑时间戳(指示写入顺序的东西,例如日志序列号)或实际系统时钟(在这种情况下,时钟同步变得至关重要;见 “不可靠的时钟”)。
- 如果你的副本分布在各个地区(为了地理上接近用户或为了可用性),还有额外的复杂性。任何需要由领导者提供的请求都必须路由到包含领导者的地区。
当同一用户从多个设备访问你的服务时,会出现另一个复杂情况,例如桌面网络浏览器和移动应用程序。在这种情况下,你可能希望提供 跨设备 写后读一致性:如果用户在一个设备上输入一些信息,然后在另一个设备上查看它,他们应该看到他们刚刚输入的信息。
在这种情况下,需要考虑一些额外的问题:
- 需要记住用户上次更新的时间戳的方法变得更加困难,因为在一个设备上运行的代码不知道在另一个设备上发生了什么更新。此元数据将需要集中化。
- 如果你的副本分布在不同的地区,则无法保证来自不同设备的连接将路由到同一地区。(例如,如果用户的台式计算机使用家庭宽带连接,而他们的移动设备使用蜂窝数据网络,则设备的网络路由可能完全不同。)如果你的方法需要从领导者读取,你可能首先需要将来自用户所有设备的请求路由到同一地区。
地区和可用区
我们用 地区(region)来指代一个地理位置中的一组数据中心。云服务提供商通常会在同一地区部署多个数据中心,每个数据中心称为 可用区(availability zone,简称 AZ)。因此,一个地区由多个可用区组成;每个可用区都是独立的物理设施,具有自己的供电、制冷等基础设施。
同一地区内各可用区通常通过高速网络互联,延迟足够低,因此大多数分布式系统可以把同一地区内的多个可用区近似看作一个机房。多可用区部署可以抵御单个可用区故障,但无法抵御整个地区不可用。要应对地区级中断,系统必须跨多个地区部署,这通常会带来更高延迟、更低吞吐和更高的云网络费用。我们将在 “多主复制拓扑” 中进一步讨论这些权衡。这里你只需记住:本书所说的“地区”,是同一地理位置内多个可用区(数据中心)的集合。
单调读
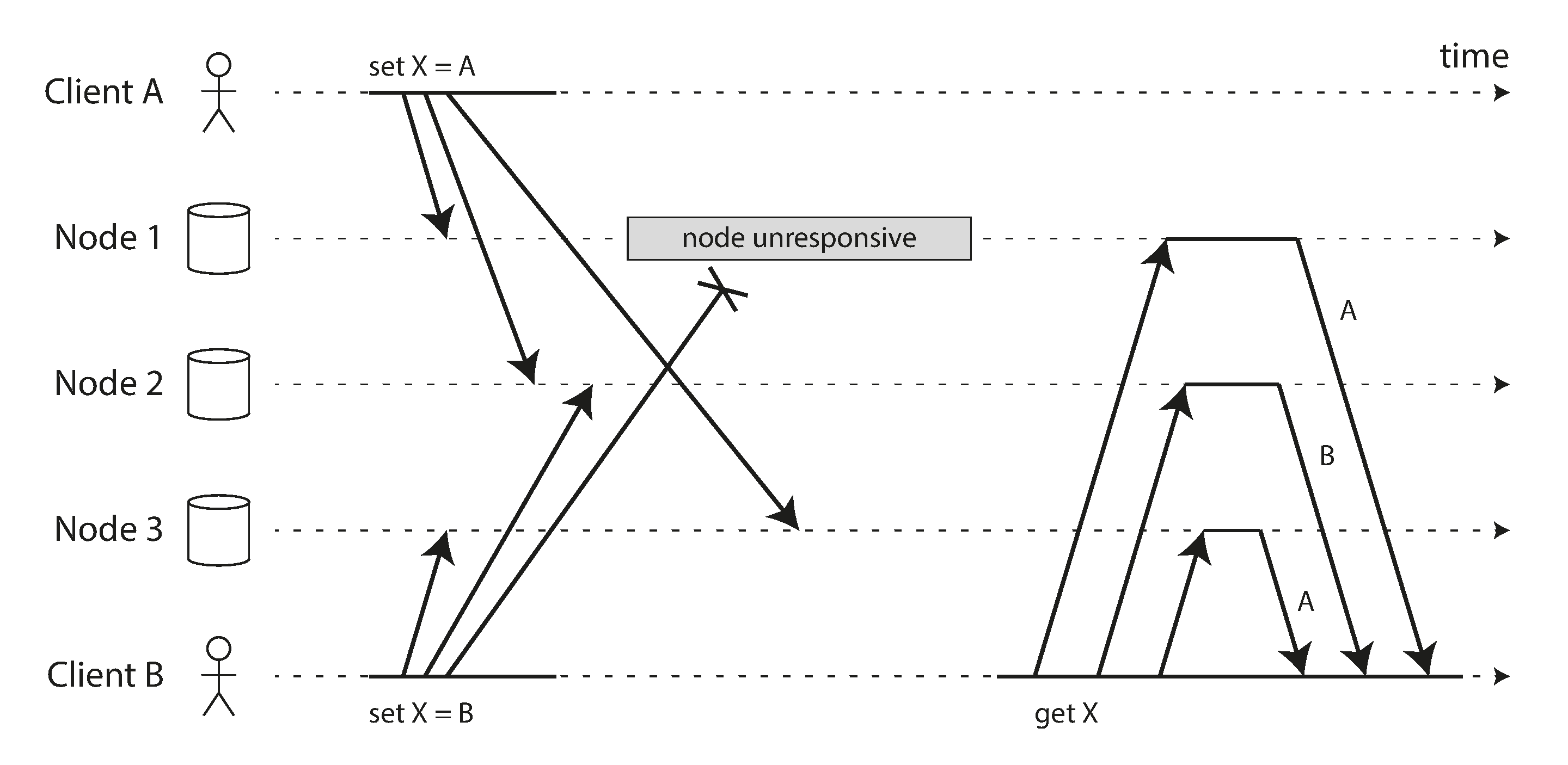
从异步追随者读取时可能发生的第二个异常示例是,用户可能会看到事物 在时间上倒退。
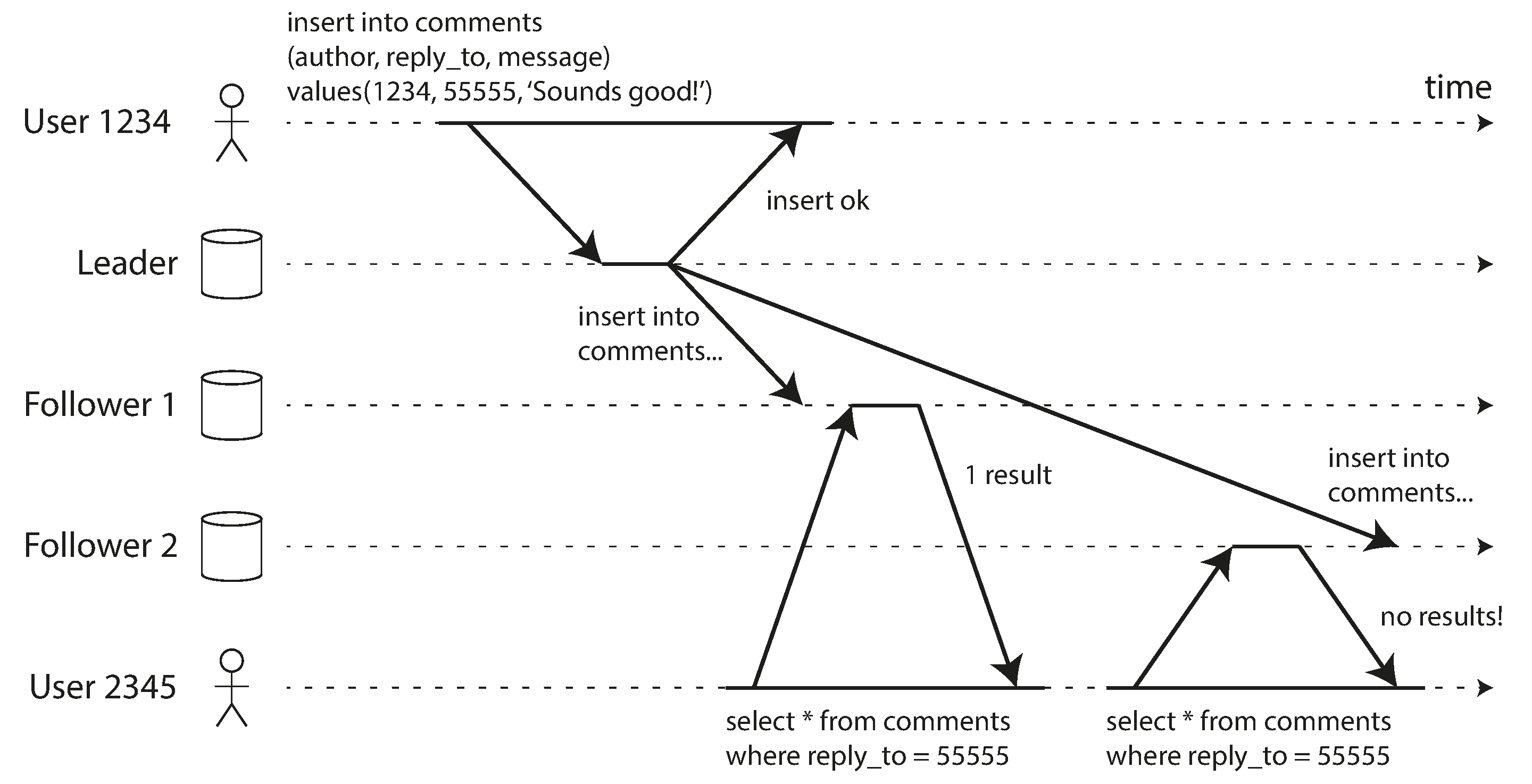
如果用户从不同的副本进行多次读取,就可能发生这种情况。例如,图 6-4 显示用户 2345 进行相同的查询两次,首先到延迟很小的追随者,然后到延迟更大的追随者。(如果用户刷新网页,并且每个请求都路由到随机服务器,这种情况很可能发生。)第一个查询返回用户 1234 最近添加的评论,但第二个查询没有返回任何内容,因为滞后的追随者尚未获取该写入。实际上,第二个查询观察到的系统状态比第一个查询更早的时间点。如果第一个查询没有返回任何内容,这不会那么糟糕,因为用户 2345 可能不知道用户 1234 最近添加了评论。然而,如果用户 2345 首先看到用户 1234 的评论出现,然后又看到它消失,这对用户 2345 来说非常令人困惑。
单调读 22 是一种保证这类异常不会发生的会话保证。它比强一致性弱,但比最终一致性强。当你读取数据时,仍可能看到旧值;单调读只保证同一用户按顺序进行多次读取时,不会出现“时间倒退”——也就是先读到新值,后又读到更旧的值。
实现单调读的一种方法是确保每个用户始终从同一副本进行读取(不同的用户可以从不同的副本读取)。例如,可以基于用户 ID 的哈希选择副本,而不是随机选择。然而,如果该副本失败,用户的查询将需要重新路由到另一个副本。
一致前缀读
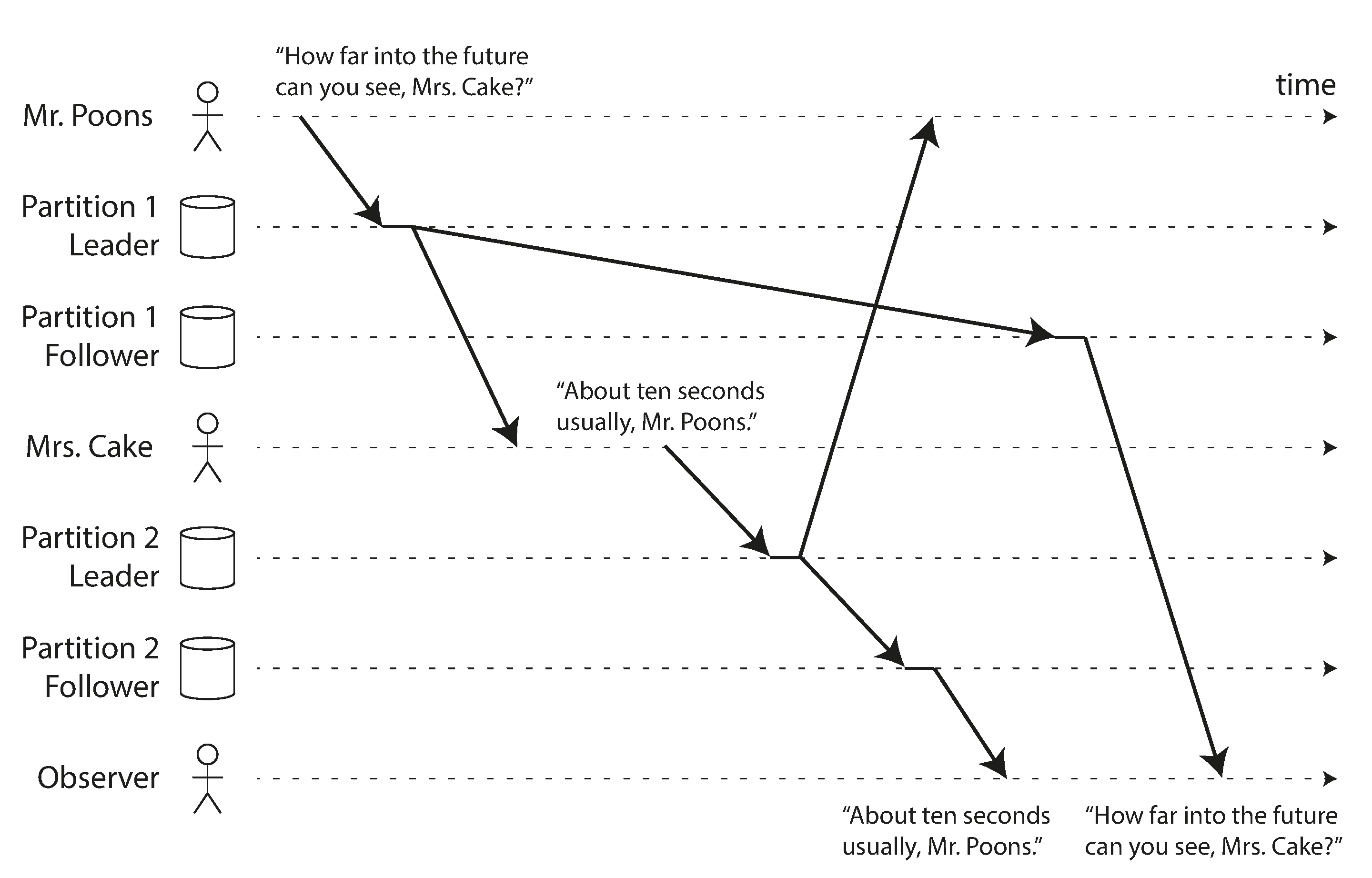
我们的第三个复制延迟异常示例涉及违反因果关系。想象一下 Poons 先生和 Cake 夫人之间的以下简短对话:
- Poons 先生
- 你能看到多远的未来,Cake 夫人?
- Cake 夫人
- 通常大约十秒钟,Poons 先生。
这两个句子之间存在因果依赖关系:Cake 夫人听到了 Poons 先生的问题并回答了它。
现在,想象第三个人通过追随者听这个对话。Cake 夫人说的话通过延迟很小的追随者,但 Poons 先生说的话有更长的复制延迟(见 图 6-5)。这个观察者会听到以下内容:
- Cake 夫人
- 通常大约十秒钟,Poons 先生。
- Poons 先生
- 你能看到多远的未来,Cake 夫人?
对观察者来说,看起来 Cake 夫人在 Poons 先生甚至提出问题之前就回答了问题。这种通灵能力令人印象深刻,但非常令人困惑 27。
防止这种异常需要另一种类型的保证:一致前缀读 22。这种保证说,如果一系列写入以某个顺序发生,那么任何读取这些写入的人都会看到它们以相同的顺序出现。
这是分片(分区)数据库中的一个特殊问题,我们将在 第 7 章 中讨论。如果数据库始终以相同的顺序应用写入,读取始终会看到一致的前缀,因此这种异常不会发生。然而,在许多分布式数据库中,不同的分片独立运行,因此没有全局的写入顺序:当用户从数据库读取时,他们可能会看到数据库的某些部分处于较旧状态,而某些部分处于较新状态。
一种解决方案是确保任何因果相关的写入都写入同一分片——但在某些应用程序中,这无法有效完成。还有一些算法明确跟踪因果依赖关系,这是我们将在 “先发生关系与并发” 中回到的主题。
复制延迟的解决方案
在使用最终一致系统时,值得思考:如果复制延迟上升到几分钟甚至几小时,应用程序会如何表现。如果答案是“没问题”,那很好;但如果这会造成糟糕的用户体验,就应当设计系统提供更强的保证(如写后读一致性)。把异步复制当作同步复制来假设,往往会在系统承压时暴露问题。
如前所述,应用程序可以提供比底层数据库更强的保证——例如,通过在领导者或同步更新的追随者上执行某些类型的读取。然而,在应用程序代码中处理这些问题很复杂且容易出错。
对于应用程序开发人员来说,最简单的编程模型是选择一个为副本提供强一致性保证的数据库,例如线性一致性(见 第 10 章)和 ACID 事务(见 第 8 章)。这允许你大部分忽略复制带来的挑战,并将数据库视为只有一个节点。在 2010 年代初期,NoSQL 运动推广了这样的观点,即这些功能限制了可伸缩性,大规模系统必须接受最终一致性。
然而,从那时起,许多数据库开始提供强一致性和事务,同时还提供分布式数据库的容错、高可用性和可伸缩性优势。如 “关系模型与文档模型” 中所述,这种趋势被称为 NewSQL,以与 NoSQL 形成对比(尽管它不太关于 SQL 本身,而更多关于可伸缩事务管理的新方法)。
尽管现在可以使用可伸缩、强一致的分布式数据库,但某些应用程序选择使用提供较弱一致性保证的不同形式的复制仍然有充分的理由:它们可以在面对网络中断时提供更强的韧性,并且与事务系统相比具有较低的开销。我们将在本章的其余部分探讨这些方法。
多主复制
到目前为止,本章中我们只考虑了使用单个领导者的复制架构。尽管这是一种常见的方法,但还有一些有趣的替代方案。
单主复制有一个主要缺点:所有写入都必须通过一个领导者。如果由于任何原因无法连接到领导者,例如你和领导者之间的网络中断,你就无法写入数据库。
单主复制模型的自然扩展是允许多个节点接受写入。复制仍然以相同的方式进行:每个处理写入的节点必须将该数据变更转发给所有其他节点。我们称之为 多主 配置(也称为 主动/主动 或 双向 复制)。在这种设置中,每个领导者同时充当其他领导者的追随者。
与单主复制一样,可以选择使其同步或异步。假设你有两个领导者,A 和 B,你正在尝试写入 A。如果写入从 A 同步复制到 B,并且两个节点之间的网络中断,你就无法写入 A 直到网络恢复。同步多主复制因此给你一个非常类似于单主复制的模型,即如果你让 B 成为领导者,A 只是将任何写入请求转发给 B 执行。
因此,我们不会进一步讨论同步多主复制,而只是将其视为等同于单主复制。本节的其余部分专注于异步多主复制,其中任何领导者都可以处理写入,即使其与其他领导者的连接中断。
跨地域运行
在单个地区内使用多主设置很少有意义,因为好处很少超过增加的复杂性。然而,在某些情况下,这种配置是合理的。
想象你有一个数据库,在几个不同的地区有副本(也许是为了能够容忍整个地区的故障,或者是为了更接近你的用户)。这被称为 地理分布式、地域分布式 或 地域复制 设置。使用单主复制,领导者必须在 一个 地区,所有写入都必须通过该地区。
在多主配置中,你可以在 每个 地区都部署一个领导者。图 6-6 展示了这种架构:在每个地区内使用常规单主复制(追随者可能位于与领导者不同的可用区);在地区之间,每个地区的领导者把变更复制给其他地区的领导者。
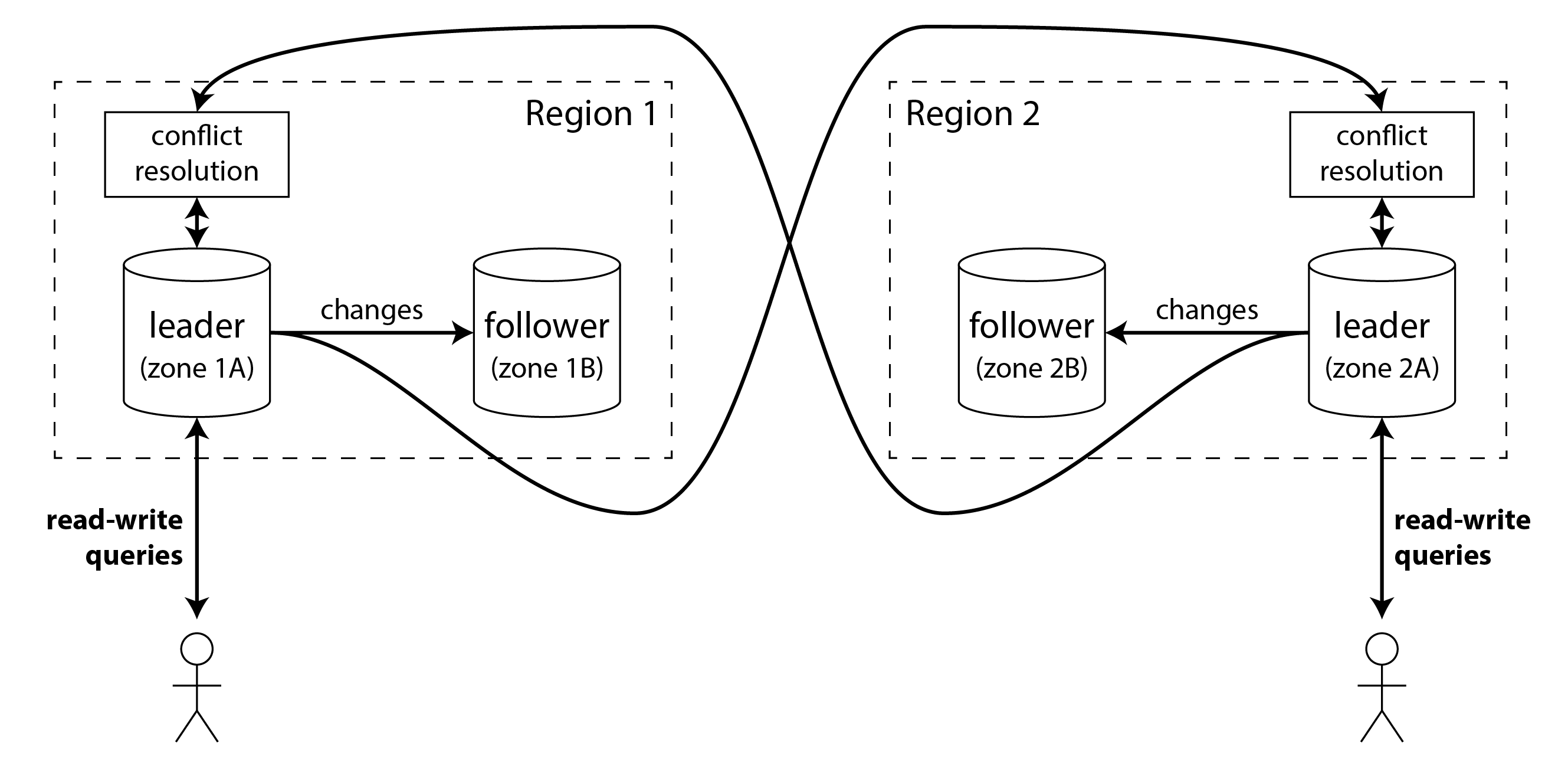
让我们比较单主和多主配置在多地区部署中的表现:
- 性能
- 在单主配置中,每次写入都必须通过互联网到拥有领导者的地区。这可能会给写入增加显著的延迟,并可能违背首先拥有多个地区的目的。在多主配置中,每次写入都可以在本地地区处理,并异步复制到其他地区。因此,跨地区网络延迟对用户是隐藏的,这意味着感知性能可能更好。
- 地区故障容忍
- 在单主配置中,如果拥有领导者的地区变得不可用,故障转移可以将另一个地区的追随者提升为领导者。在多主配置中,每个地区可以独立于其他地区继续运行,并在离线地区恢复上线时赶上复制。
- 网络问题容忍
- 即使有专用连接,地区之间的流量也可能比同一地区内或单个区域内的流量更不可靠。单主配置对这种跨地区链路中的问题非常敏感,因为当一个地区的客户端想要写入另一个地区的领导者时,它必须通过该链路发送其请求并等待响应才能完成。
具有异步复制的多主配置可以更好地容忍网络问题:在临时网络中断期间,每个地区的领导者可以继续独立处理写入。
- 一致性
- 单主系统可以提供强一致性保证,例如可串行化事务,我们将在 第 8 章 中讨论。多主系统的最大缺点是它们能够实现的一致性要弱得多。例如,你不能保证银行账户不会变成负数或用户名是唯一的:不同的领导者总是可能处理单独没问题的写入(从账户中支付一些钱,注册特定用户名),但当与另一个领导者上的另一个写入结合时违反了约束。
这只是分布式系统的基本限制 28。如果你必须强制执行这类约束,通常应选择单主系统。不过,正如我们将在 “处理写入冲突” 中看到的,多主系统在不需要这类约束的广泛应用里,仍然可以提供有用的一致性属性。
多主复制不如单主复制常见,但许多数据库仍然支持它,包括 MySQL、Oracle、SQL Server 和 YugabyteDB。在某些情况下,它是一个外部附加功能,例如在 Redis Enterprise、EDB Postgres Distributed 和 pglogical 中 29。
由于多主复制在许多数据库中是一个有点改装的功能,因此通常存在微妙的配置陷阱和与其他数据库功能的令人惊讶的交互。例如,自增键、触发器和完整性约束可能会有问题。因此,多主复制通常被认为是应该尽可能避免的危险领域 30。
多主复制拓扑
复制拓扑 描述了写入从一个节点传播到另一个节点的通信路径。如果你有两个领导者,如 图 6-9 中,只有一种合理的拓扑:领导者 1 必须将其所有写入发送到领导者 2,反之亦然。有了两个以上的领导者,各种不同的拓扑是可能的。图 6-7 中说明了一些示例。
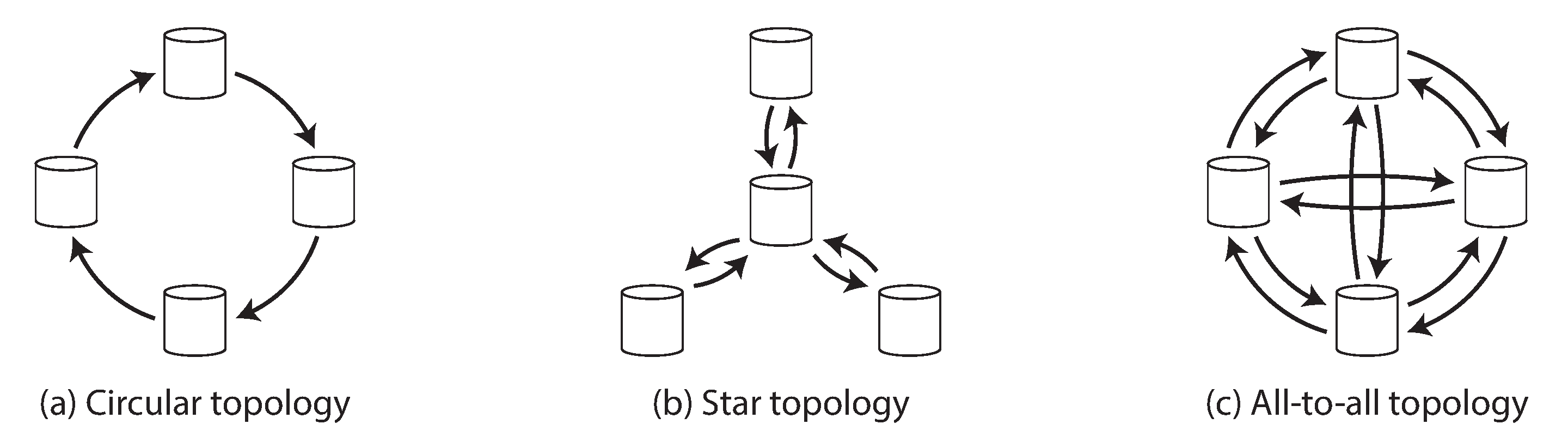
最通用的拓扑是 全对全,如 图 6-7(c) 所示,其中每个领导者将其写入发送到每个其他领导者。然而,也使用更受限制的拓扑:例如 环形拓扑,其中每个节点从一个节点接收写入并将这些写入(加上其自己的任何写入)转发到另一个节点。另一种流行的拓扑具有 星形 形状:一个指定的根节点将写入转发到所有其他节点。星形拓扑可以推广到树形。
Note
不要将星形网络拓扑与 星型模式 混淆(见 “星型与雪花型:分析模式”),后者描述了数据模型的结构。
在环形和星形拓扑中,写入可能需要通过几个节点才能到达所有副本。因此,节点需要转发它们从其他节点接收的数据变更。为了防止无限复制循环,每个节点都被赋予一个唯一标识符,并且在复制日志中,每个写入都用它经过的所有节点的标识符标记 31。当节点接收到用其自己的标识符标记的数据变更时,该数据变更将被忽略,因为节点知道它已经被处理过了。
不同拓扑的问题
环形和星形拓扑的一个问题是,如果只有一个节点发生故障,它可能会中断其他节点之间的复制消息流,使它们无法通信,直到节点被修复。可以重新配置拓扑以绕过故障节点,但在大多数部署中,这种重新配置必须手动完成。更密集连接的拓扑(如全对全)的容错性更好,因为它允许消息沿着不同的路径传播,避免单点故障。
另一方面,全对全拓扑也可能有问题。特别是,一些网络链路可能比其他链路更快(例如,由于网络拥塞),结果是一些复制消息可能会"超越"其他消息,如 图 6-8 所示。
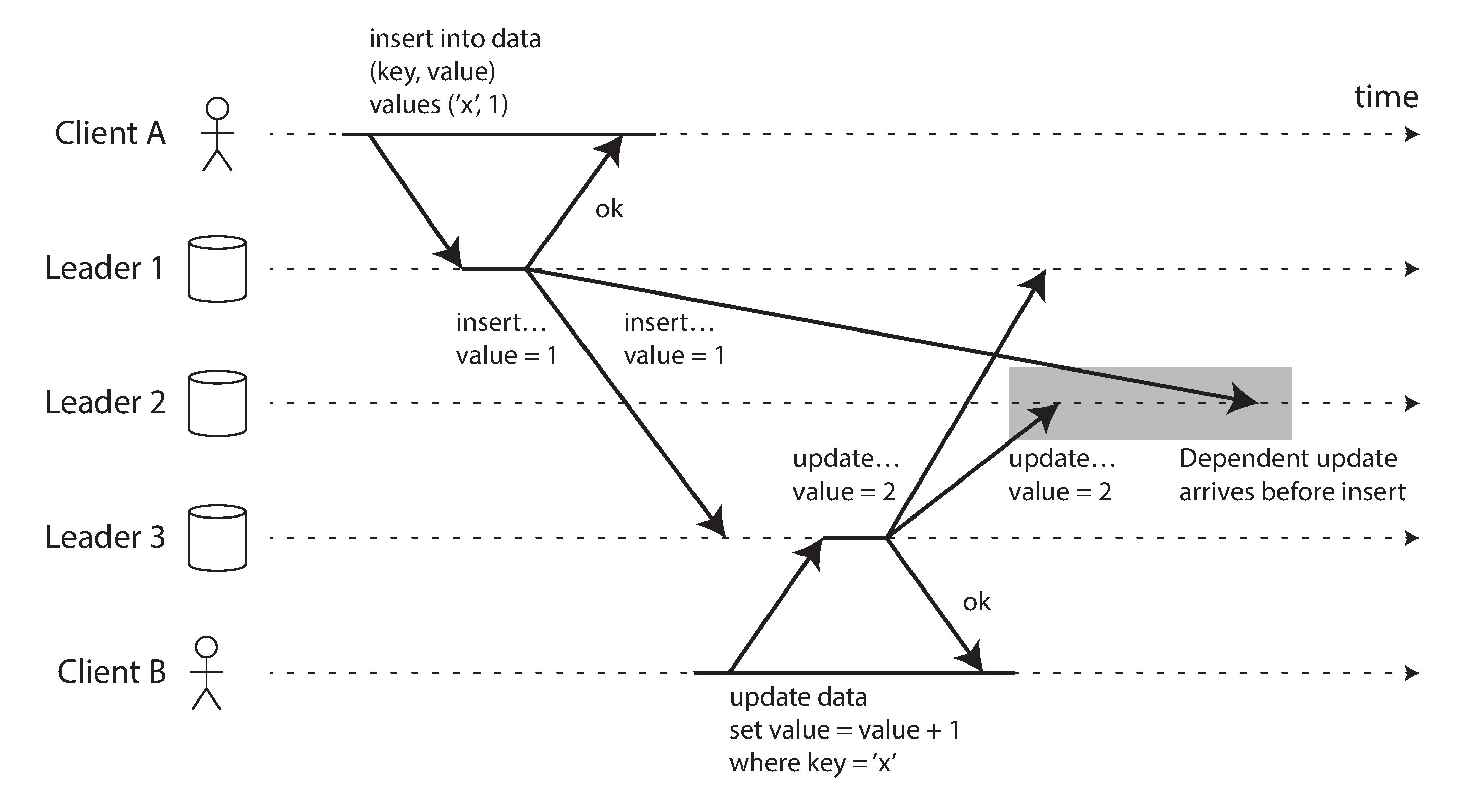
在 图 6-8 中,客户端 A 在领导者 1 上向表中插入一行,客户端 B 在领导者 3 上更新该行。然而,领导者 2 可能以不同的顺序接收写入:它可能首先接收更新(从其角度来看,这是对数据库中不存在的行的更新),然后才接收相应的插入(应该在更新之前)。
这是一个因果关系问题,类似于我们在 “一致前缀读” 中看到的问题:更新依赖于先前的插入,因此我们需要确保所有节点首先处理插入,然后处理更新。简单地为每个写入附加时间戳是不够的,因为时钟不能被信任足够同步以在领导者 2 上正确排序这些事件(见 第 9 章)。
为了正确排序这些事件,可以使用一种称为 版本向量 的技术,我们将在本章后面讨论(见 “检测并发写入”)。然而,许多多主复制系统不使用良好的技术来排序更新,使它们容易受到像 图 6-8 中的问题的影响。如果你使用多主复制,值得了解这些问题,仔细阅读文档,并彻底测试你的数据库,以确保它真正提供你认为它具有的保证。
同步引擎与本地优先软件
另一种适合多主复制的情况是,如果你有一个需要在与互联网断开连接时继续工作的应用程序。
例如,考虑你的手机、笔记本电脑和其他设备上的日历应用程序。你需要能够随时查看你的会议(进行读取请求)并输入新会议(进行写入请求),无论你的设备当前是否有互联网连接。如果你在离线时进行任何更改,它们需要在设备下次上线时与服务器和你的其他设备同步。
在这种情况下,每个设备都拥有一个充当领导者的本地数据库副本(可接受写入),并在你所有设备上的日历副本之间运行异步多主复制流程(即同步过程)。复制延迟可能是几小时甚至几天,具体取决于你何时能连上互联网。
从架构的角度来看,这种设置与地区之间的多主复制非常相似,达到了极端:每个设备是一个"地区",它们之间的网络连接极其不可靠。
实时协作、离线优先和本地优先应用
此外,许多现代 Web 应用程序提供 实时协作 功能,例如用于文本文档和电子表格的 Google Docs 和 Sheets,用于图形的 Figma,以及用于项目管理的 Linear。使这些应用程序如此响应的原因是用户输入立即反映在用户界面中,无需等待到服务器的网络往返,并且一个用户的编辑以低延迟显示给他们的协作者 32 33 34。
这再次导致多主架构:每个打开共享文件的 Web 浏览器选项卡都是一个副本,你对文件进行的任何更新都会异步复制到打开同一文件的其他用户的设备。即使应用程序不允许你在离线时继续编辑文件,多个用户可以进行编辑而无需等待服务器的响应这一事实已经使其成为多主。
离线编辑和实时协作都需要类似的复制基础设施:应用程序需要捕获用户对文件所做的任何更改,并立即将它们发送给协作者(如果在线),或本地存储它们以供稍后发送(如果离线)。此外,应用程序需要接收来自协作者的更改,将它们合并到用户的文件本地副本中,并更新用户界面以反映最新版本。如果多个用户同时更改了文件,可能需要冲突解决逻辑来合并这些更改。
支持此过程的软件库称为 同步引擎。尽管这个想法已经存在很长时间了,但这个术语最近才受到关注 35 36 37。允许用户在离线时继续编辑文件的应用程序(可能使用同步引擎实现)称为 离线优先 38。术语 本地优先软件 指的是不仅是离线优先的协作应用程序,而且即使制作软件的开发人员关闭了他们的所有在线服务,也被设计为继续工作 39。这可以通过使用具有开放标准同步协议的同步引擎来实现,该协议有多个服务提供商可用 40。例如,Git 是一个本地优先的协作系统(尽管不支持实时协作),因为你可以通过 GitHub、GitLab 或任何其他存储库托管服务进行同步。
同步引擎的利弊
今天构建 Web 应用程序的主导方式是在客户端保留很少的持久状态,并在需要显示新数据或需要更新某些数据时依赖向服务器发出请求。相比之下,当使用同步引擎时,你在客户端有持久状态,与服务器的通信被移到后台进程中。同步引擎方法有许多优点:
- 在本地拥有数据意味着用户界面的响应速度可以比必须等待服务调用获取某些数据时快得多。一些应用程序的目标是在图形系统的 下一帧 响应用户输入,这意味着在 60 Hz 刷新率的显示器上在 16 毫秒内渲染。
- 允许用户在离线时继续工作是有价值的,特别是在具有间歇性连接的移动设备上。使用同步引擎,应用程序不需要单独的离线模式:离线与具有非常大的网络延迟相同。
- 与在应用程序代码中执行显式服务调用相比,同步引擎简化了前端应用程序的编程模型。每个服务调用都需要错误处理,如 “远程过程调用(RPC)的问题” 中所讨论的:例如,如果更新服务器上的数据的请求失败,用户界面需要以某种方式反映该错误。同步引擎允许应用程序对本地数据执行读写,这几乎从不失败,导致更具声明性的编程风格 41。
- 为了实时显示其他用户的编辑,你需要接收这些编辑的通知并相应地有效更新用户界面。同步引擎与 响应式编程 模型相结合是实现此目的的好方法 42。
当用户可能需要的所有数据都提前下载并持久存储在客户端时,同步引擎效果最佳。这意味着数据可用于离线访问,但这也意味着如果用户可以访问非常大量的数据,同步引擎就不适合。例如,下载用户自己创建的所有文件可能很好(一个用户通常不会生成那么多数据),但下载电子商务网站的整个目录可能没有意义。
同步引擎由 Lotus Notes 在 20 世纪 80 年代开创 43(没有使用该术语),特定应用程序(如日历)的同步也已经存在很长时间了。今天有许多通用同步引擎,其中一些使用专有后端服务(例如,Google Firestore、Realm 或 Ditto),有些具有开源后端,使它们适合创建本地优先软件(例如,PouchDB/CouchDB、Automerge 或 Yjs)。
多人视频游戏有类似的需求,需要立即响应用户的本地操作,并将它们与通过网络异步接收的其他玩家的操作协调。在游戏开发术语中,同步引擎的等效物称为 网络代码。网络代码中使用的技术非常特定于游戏的要求 44,并且不能直接应用于其他类型的软件,因此我们不会在本书中进一步考虑它们。
处理写入冲突
多主复制的最大问题——无论是在地域分布式服务器端数据库中还是在终端用户设备上的本地优先同步引擎中——是不同领导者上的并发写入可能导致需要解决的冲突。
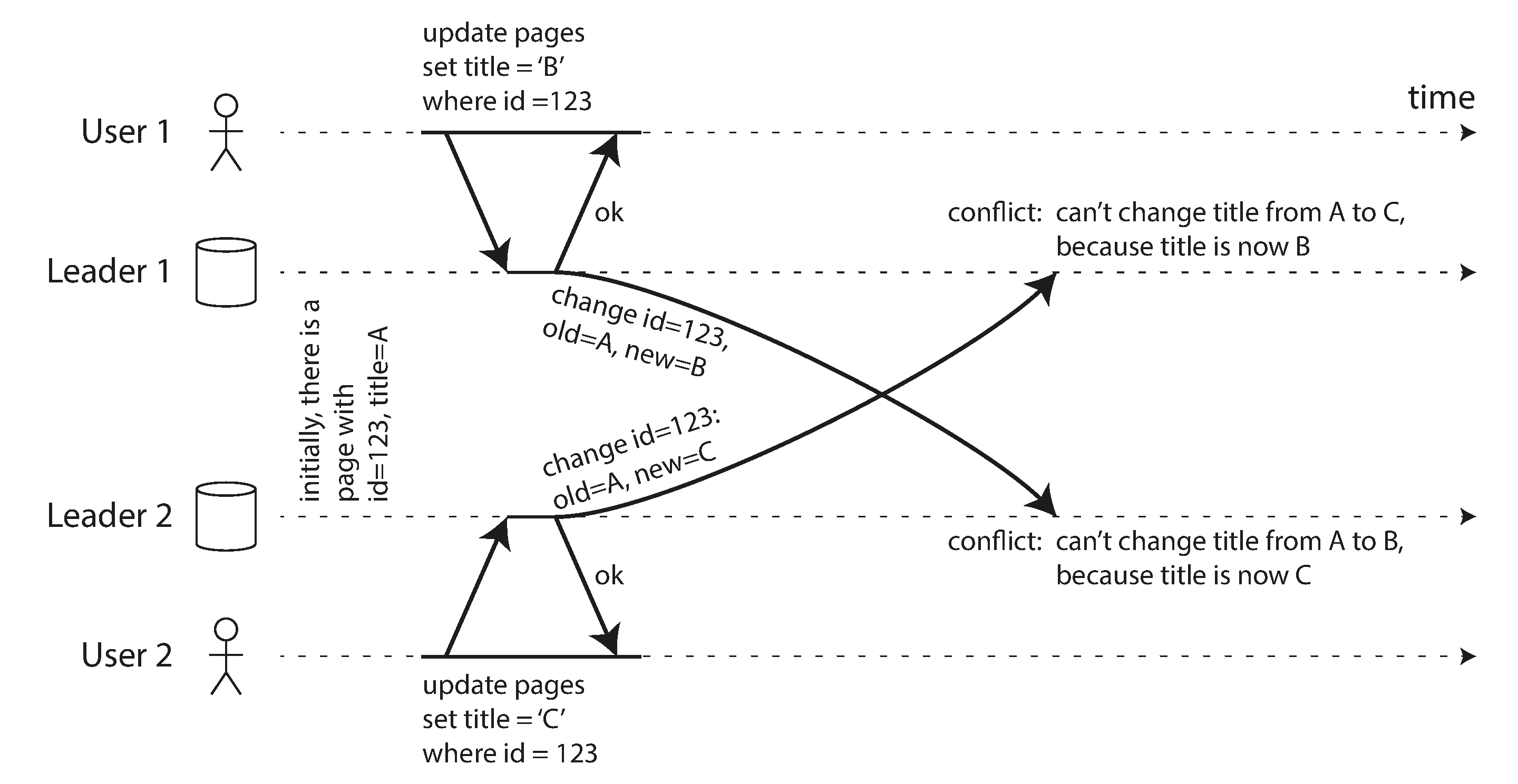
例如,考虑一个维基页面同时被两个用户编辑,如 图 6-9 所示。用户 1 将页面标题从 A 更改为 B,用户 2 独立地将标题从 A 更改为 C。每个用户的更改成功应用于其本地领导者。然而,当更改异步复制时,检测到冲突。这个问题在单主数据库中不会发生。
Note
我们说 图 6-9 中的两个写入是 并发的,因为在最初进行写入时,两者都不“知道”对方。写入是否真的在同一时刻发生并不重要;实际上,如果写入发生在离线状态,它们在物理时间上可能相隔很久。关键在于:一个写入是否发生在另一个写入已经生效的状态之上。
在 “检测并发写入” 中,我们将解决数据库如何确定两个写入是否并发的问题。现在我们假设我们可以检测冲突,并且我们想找出解决它们的最佳方法。
冲突避免
冲突的一种策略是首先避免它们发生。例如,如果应用程序可以确保特定记录的所有写入都通过同一领导者,那么即使整个数据库是多主的,也不会发生冲突。这种方法在同步引擎客户端离线更新的情况下是不可能的,但在地域复制的服务器系统中有时是可能的 30。
例如,在一个用户只能编辑自己数据的应用程序中,你可以确保来自特定用户的请求始终路由到同一地区,并使用该地区的领导者进行读写。不同的用户可能有不同的"主"地区(可能基于与用户的地理接近程度选择),但从任何一个用户的角度来看,配置本质上是单主的。
然而,有时你可能想要更改记录的指定领导者——也许是因为一个地区不可用,你需要将流量重新路由到另一个地区,或者也许是因为用户已经移动到不同的位置,现在更接近不同的地区。现在存在风险,即用户在指定领导者更改正在进行时执行写入,导致必须使用下面的方法之一解决的冲突。因此,如果你允许更改领导者,冲突避免就会失效。
冲突避免的另一个例子:想象你想要插入新记录并基于自增计数器为它们生成唯一 ID。如果你有两个领导者,你可以设置它们,使得一个领导者只生成奇数,另一个只生成偶数。这样你可以确保两个领导者不会同时为不同的记录分配相同的 ID。我们将在 “ID 生成器和逻辑时钟” 中讨论其他 ID 分配方案。
最后写入胜利(丢弃并发写入)
如果无法避免冲突,解决它们的最简单方法是为每个写入附加时间戳,并始终使用具有最大时间戳的值。例如,在 图 6-9 中,假设用户 1 的写入时间戳大于用户 2 的写入时间戳。在这种情况下,两个领导者都将确定页面的新标题应该是 B,并丢弃将其设置为 C 的写入。如果写入巧合地具有相同的时间戳,可以通过比较值来选择获胜者(例如,在字符串的情况下,取字母表中较早的那个)。
这种方法称为 最后写入胜利(LWW),因为具有最大时间戳的写入可以被认为是"最后"的。然而,这个术语是误导性的,因为当两个写入像 图 6-9 中那样并发时,哪个更旧,哪个更新是未定义的,因此并发写入的时间戳顺序本质上是随机的。
因此,LWW 的真正含义是:当同一记录在不同的领导者上并发写入时,其中一个写入被随机选择为获胜者,其他写入被静默丢弃,即使它们在各自的领导者上成功处理。这实现了最终所有副本都处于一致状态的目标,但代价是数据丢失。
如果你可以避免冲突——例如,通过只插入具有唯一键(如 UUID)的记录,而从不更新它们——那么 LWW 没有问题。但是,如果你更新现有记录,或者如果不同的领导者可能插入具有相同键的记录,那么你必须决定丢失的更新对你的应用程序是否是个问题。如果丢失的更新是不可接受的,你需要使用下面描述的冲突解决方法之一。
LWW 的另一个问题是,如果使用实时时钟(例如 Unix 时间戳)作为写入的时间戳,系统对时钟同步变得非常敏感。如果一个节点的时钟领先于其他节点,并且你尝试覆盖该节点写入的值,你的写入可能会被忽略,因为它可能具有较低的时间戳,即使它明显发生得更晚。这个问题可以通过使用 逻辑时钟 来解决,我们将在 “ID 生成器和逻辑时钟” 中讨论。
手动冲突解决
如果随机丢弃你的一些写入是不可取的,下一个选择是手动解决冲突。你可能熟悉 Git 和其他版本控制系统中的手动冲突解决:如果两个不同分支上的提交编辑同一文件的相同行,并且你尝试合并这些分支,你将得到一个需要在合并完成之前解决的合并冲突。
在数据库里,让冲突阻塞整个复制流程、直到人工处理,通常并不现实。更常见的是,数据库会保留某条记录的所有并发写入值——例如 图 6-9 中的 B 和 C。这些值有时称为 兄弟。下次查询该记录时,数据库会返回 所有 这些值,而不只是最新值。随后你可以按需要解决这些值:要么在应用代码里自动处理(例如把 B 和 C 合并成 “B/C”),要么让用户参与处理;最后再把新值写回数据库以消解冲突。
这种冲突解决方法在某些系统中使用,例如 CouchDB。然而,它也存在许多问题:
- 数据库的 API 发生变化:例如,以前维基页面的标题只是一个字符串,现在它变成了一组字符串,通常包含一个元素,但如果有冲突,有时可能包含多个元素。这可能使应用程序代码中的数据难以处理。
- 要求用户手动合并兄弟,会带来很大负担:开发者需要构建冲突解决界面,用户也可能不明白自己为何要做这件事。在很多场景下,自动合并比打扰用户更合适。
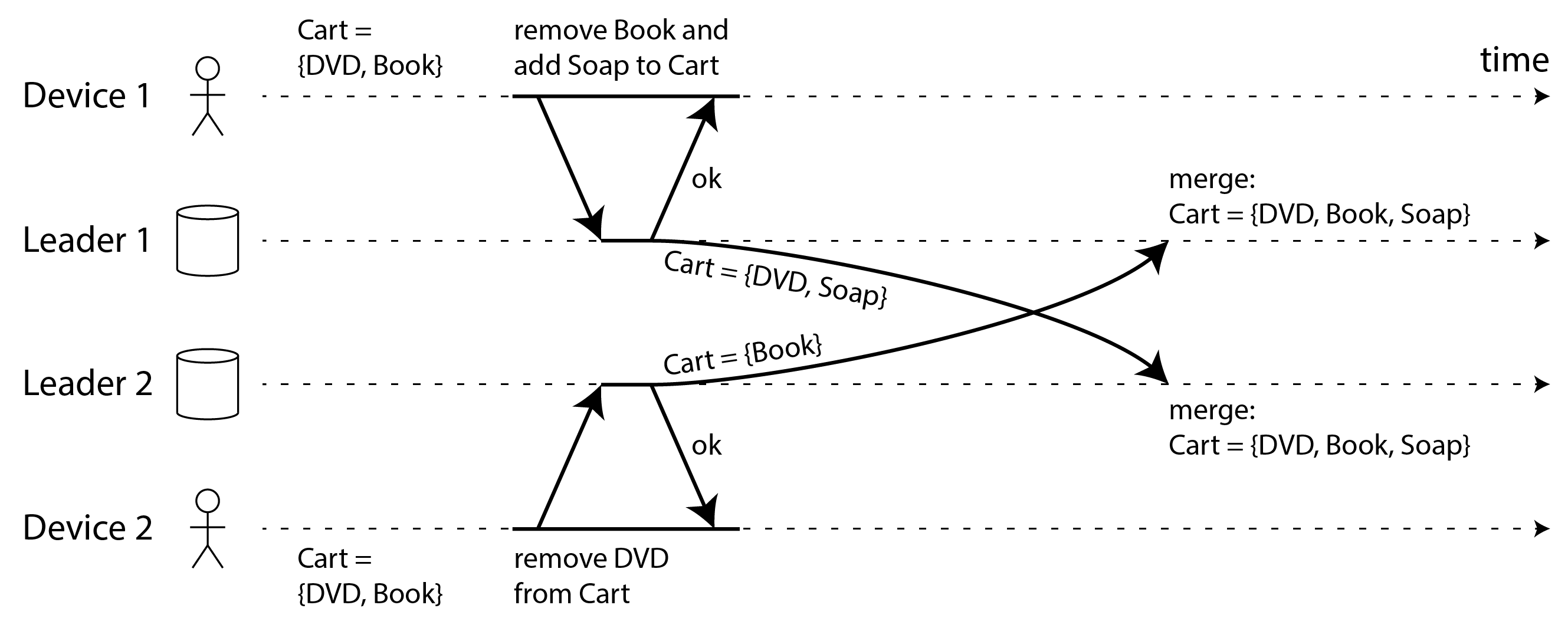
- 如果不够谨慎,自动合并兄弟也可能产生反直觉行为。例如,亚马逊购物车曾允许并发更新,并用“并集”策略合并(保留出现在任一兄弟中的所有商品)。这意味着:若用户在一个兄弟里删除了某商品,但另一个兄弟仍保留它,该商品会“复活”回购物车 45。图 6-10 就是一个例子:设备 1 删除 Book,设备 2 并发删除 DVD,冲突合并后两个商品都回来了。
- 如果多个节点观察到冲突并并发解决它,冲突解决过程本身可能会引入新的冲突。这些解决方案甚至可能不一致:例如,如果你不小心一致地排序它们,一个节点可能将 B 和 C 合并为"B/C",另一个可能将它们合并为"C/B"。当"B/C"和"C/B"之间的冲突被合并时,它可能导致"B/C/C/B"或类似令人惊讶的东西。
自动冲突解决
对于许多应用程序,处理冲突的最佳方法是使用自动将并发写入合并为一致状态的算法。自动冲突解决确保所有副本 收敛 到相同的状态——即,处理了相同写入集的所有副本都具有相同的状态,无论写入到达的顺序如何。
LWW 是冲突解决算法的一个简单示例。已经为不同类型的数据开发了更复杂的合并算法,目标是尽可能保留所有更新的预期效果,从而避免数据丢失:
- 如果数据是文本(例如维基页面标题或正文),我们可以检测每次版本演进中的字符插入和删除。合并结果会保留任一兄弟中的所有插入和删除。如果多个用户并发在同一位置插入文本,还可以用确定性顺序来排序,以确保所有节点得到同样的合并结果。
- 如果数据是项目集合(像待办事项列表那样有序,或像购物车那样无序),我们可以通过跟踪插入和删除类似于文本来合并它。为了避免 图 6-10 中的购物车问题,算法跟踪 Book 和 DVD 被删除的事实,因此合并的结果是 Cart = {Soap}。
- 如果数据是可增可减的整数计数器(例如社交媒体帖子的点赞数),合并算法可以统计每个兄弟上的递增和递减次数,并正确求和,既不重复计数,也不丢更新。
- 如果数据是键值映射,我们可以通过将其他冲突解决算法之一应用于该键下的值来合并对同一键的更新。对不同键的更新可以相互独立处理。
冲突解决的可能性是有限的。例如,如果你想强制一个列表不包含超过五个项目,并且多个用户并发地向列表添加项目,使得总共有五个以上,你唯一的选择是丢弃一些项目。尽管如此,自动冲突解决足以构建许多有用的应用程序。如果你从想要构建协作离线优先或本地优先应用程序的要求开始,那么冲突解决是不可避免的,自动化它通常是最好的方法。
CRDT 与操作变换
两个算法族通常用于实现自动冲突解决:无冲突复制数据类型(CRDT)46 和 操作变换(OT)47。它们具有不同的设计理念和性能特征,但都能够为前面提到的所有类型的数据执行自动合并。
图 6-11 显示了 OT 和 CRDT 如何合并对文本的并发更新的示例。假设你有两个副本,都从文本"ice"开始。一个副本在前面添加字母"n"以制作"nice",而另一个副本并发地附加感叹号以制作"ice!"。
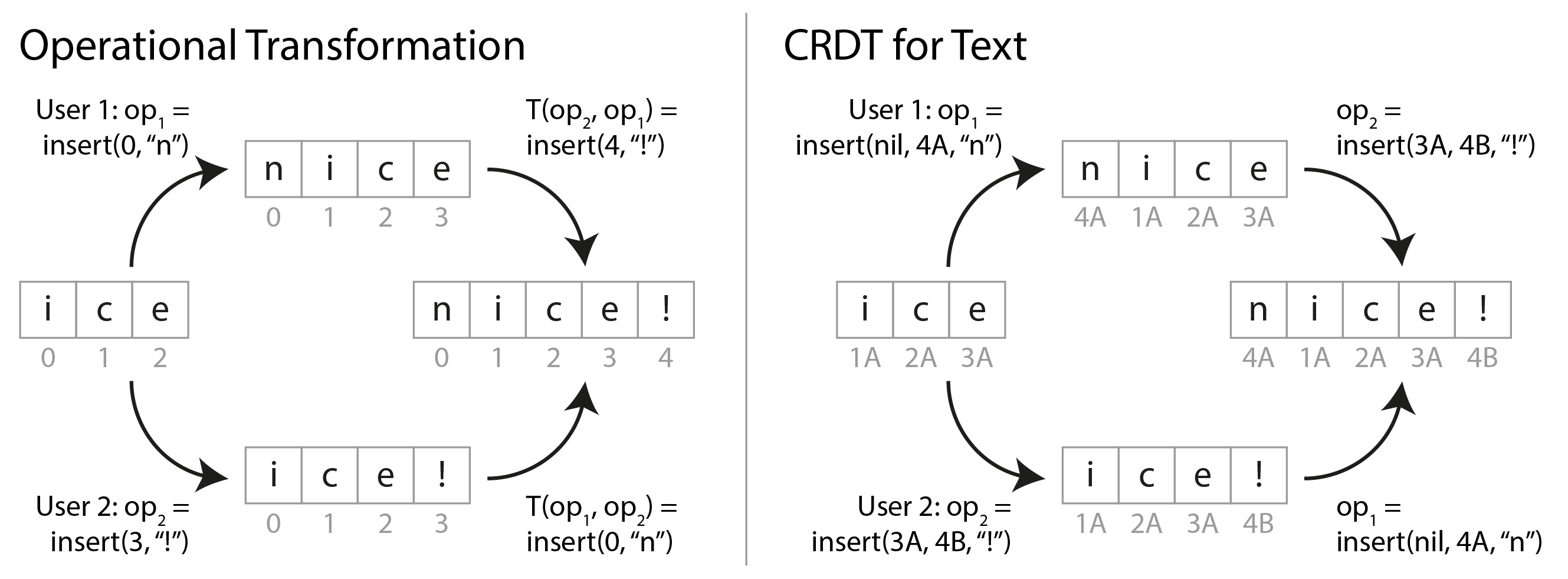
合并的结果"nice!“由两种类型的算法以不同的方式实现:
- OT
- 我们记录插入或删除字符的索引:“n"插入在索引 0,”!“插入在索引 3。接下来,副本交换它们的操作。在 0 处插入"n"可以按原样应用,但如果在 3 处插入”!“应用于状态"nice”,我们将得到"nic!e”,这是不正确的。因此,我们需要转换每个操作的索引以考虑已经应用的并发操作;在这种情况下,"!“的插入被转换为索引 4 以考虑在较早索引处插入"n”。
- CRDT
- 大多数 CRDT 为每个字符提供唯一的、不可变的 ID,并使用这些 ID 来确定插入/删除的位置,而不是索引。例如,在 图 6-11 中,我们将 ID 1A 分配给"i",ID 2A 分配给"c"等。插入感叹号时,我们生成一个包含新字符的 ID(4B)和我们想要在其后插入的现有字符的 ID(3A)的操作。要在字符串的开头插入,我们将"nil"作为前面的字符 ID。在同一位置的并发插入按字符的 ID 排序。这确保副本收敛而不执行任何转换。
有许多基于这些想法变体的算法。列表/数组可以类似地支持,使用列表元素而不是字符,其他数据类型(如键值映射)可以很容易地添加。OT 和 CRDT 之间存在一些性能和功能权衡,但可以在一个算法中结合 CRDT 和 OT 的优点 48。
OT 最常用于文本的实时协作编辑,例如在 Google Docs 中 32,而 CRDT 可以在分布式数据库中找到,例如 Redis Enterprise、Riak 和 Azure Cosmos DB 49。JSON 数据的同步引擎可以使用 CRDT(例如,Automerge 或 Yjs)和 OT(例如,ShareDB)实现。
什么是冲突?
某些类型的冲突是显而易见的。在 图 6-9 的示例中,两个写入并发修改了同一记录中的同一字段,将其设置为两个不同的值。毫无疑问,这是一个冲突。
其他类型的冲突可能更难以检测。例如,考虑一个会议室预订系统:它跟踪哪个房间由哪组人在什么时间预订。此应用程序需要确保每个房间在任何时间只由一组人预订(即,同一房间不得有任何重叠的预订)。在这种情况下,如果为同一房间同时创建两个不同的预订,可能会出现冲突。即使应用程序在允许用户进行预订之前检查可用性,如果两个预订是在两个不同的领导者上进行的,也可能会发生冲突。
没有现成的快速答案,不过在后续章节中,我们会逐步建立对这个问题的理解。我们将在 第 8 章 看到更多冲突案例,并在 “通过事件顺序捕获因果关系” 中讨论在复制系统里可伸缩地检测和解决冲突的方法。
无主复制
到目前为止,我们在本章中讨论的复制方法——单主和多主复制——都基于这样的想法:客户端向一个节点(领导者)发送写入请求,数据库系统负责将该写入复制到其他副本。领导者确定写入应该处理的顺序,追随者以相同的顺序应用领导者的写入。
一些数据存储系统采用不同的方法,放弃领导者的概念,并允许任何副本直接接受来自客户端的写入。一些最早的复制数据系统是无主的 1 50,但在关系数据库主导的时代,这个想法基本上被遗忘了。在亚马逊于 2007 年将其用于其内部 Dynamo 系统后,它再次成为数据库的时尚架构 45。Riak、Cassandra 和 ScyllaDB 是受 Dynamo 启发的具有无主复制模型的开源数据存储,因此这种数据库也被称为 Dynamo 风格。
Note
在某些无主实现中,客户端直接将其写入发送到多个副本,而在其他实现中,协调器节点代表客户端执行此操作。然而,与领导者数据库不同,该协调器不强制执行特定的写入顺序。正如我们将看到的,这种设计差异对数据库的使用方式产生了深远的影响。
当节点故障时写入数据库
想象你有一个具有三个副本的数据库,其中一个副本当前不可用——也许它正在重新启动以安装系统更新。在单主配置中,如果你想继续处理写入,你可能需要执行故障转移(见 “处理节点故障”)。
另一方面,在无主配置中,故障转移不存在。图 6-12 显示了发生的情况:客户端(用户 1234)将写入并行发送到所有三个副本,两个可用副本接受写入,但不可用副本错过了它。假设三个副本中有两个确认写入就足够了:在用户 1234 收到两个 ok 响应后,我们认为写入成功。客户端只是忽略了其中一个副本错过写入的事实。
现在想象不可用节点恢复上线,客户端开始从它读取。在节点宕机期间发生的任何写入都从该节点丢失。因此,如果你从该节点读取,你可能会得到 陈旧(过时)值作为响应。
为了解决这个问题,当客户端从数据库读取时,它不只是将其请求发送到一个副本:读取请求也并行发送到多个节点。客户端可能会从不同的节点获得不同的响应;例如,从一个节点获得最新值,从另一个节点获得陈旧值。
为了区分哪些响应是最新的,哪些是过时的,写入的每个值都需要用版本号或时间戳标记,类似于我们在 “最后写入胜利(丢弃并发写入)” 中看到的。当客户端收到对读取的多个值响应时,它使用具有最大时间戳的值(即使该值仅由一个副本返回,而其他几个副本返回较旧的值)。有关更多详细信息,请参见 “检测并发写入”。
追赶错过的写入
复制系统应确保最终所有数据都复制到每个副本。在不可用节点恢复上线后,它如何赶上它错过的写入?在 Dynamo 风格的数据存储中使用了几种机制:
- 读修复
- 当客户端并行从多个节点读取时,它可以检测任何陈旧响应。例如,在 图 6-12 中,用户 2345 从副本 3 获得版本 6 的值,从副本 1 和 2 获得版本 7 的值。客户端发现副本 3 陈旧后,会把较新的值写回该副本。这种方法适用于经常被读取的值。
- 提示移交
- 如果一个副本不可用,另一个副本可能会以 提示 的形式代表其存储写入。当应该接收这些写入的副本恢复时,存储提示的副本将它们发送到恢复的副本,然后删除提示。这个 移交 过程有助于使副本保持最新,即使对于从未读取的值也是如此,因此不由读修复处理。
- 反熵
- 此外,还有一个后台进程定期查找副本之间数据的差异,并将任何缺失的数据从一个副本复制到另一个。与基于领导者的复制中的复制日志不同,这个 反熵进程 不以任何特定顺序复制写入,并且在复制数据之前可能会有显著的延迟。
读写仲裁
在 图 6-12 的例子中,即使写入仅在三个副本中的两个上处理,我们也认为写入成功。如果三个副本中只有一个接受了写入呢?我们能推多远?
如果我们知道每次成功的写入都保证至少存在于三个副本中的两个上,这意味着最多一个副本可能是陈旧的。因此,如果我们从至少两个副本读取,我们可以确信两个中至少有一个是最新的。如果第三个副本宕机或响应缓慢,读取仍然可以继续返回最新值。
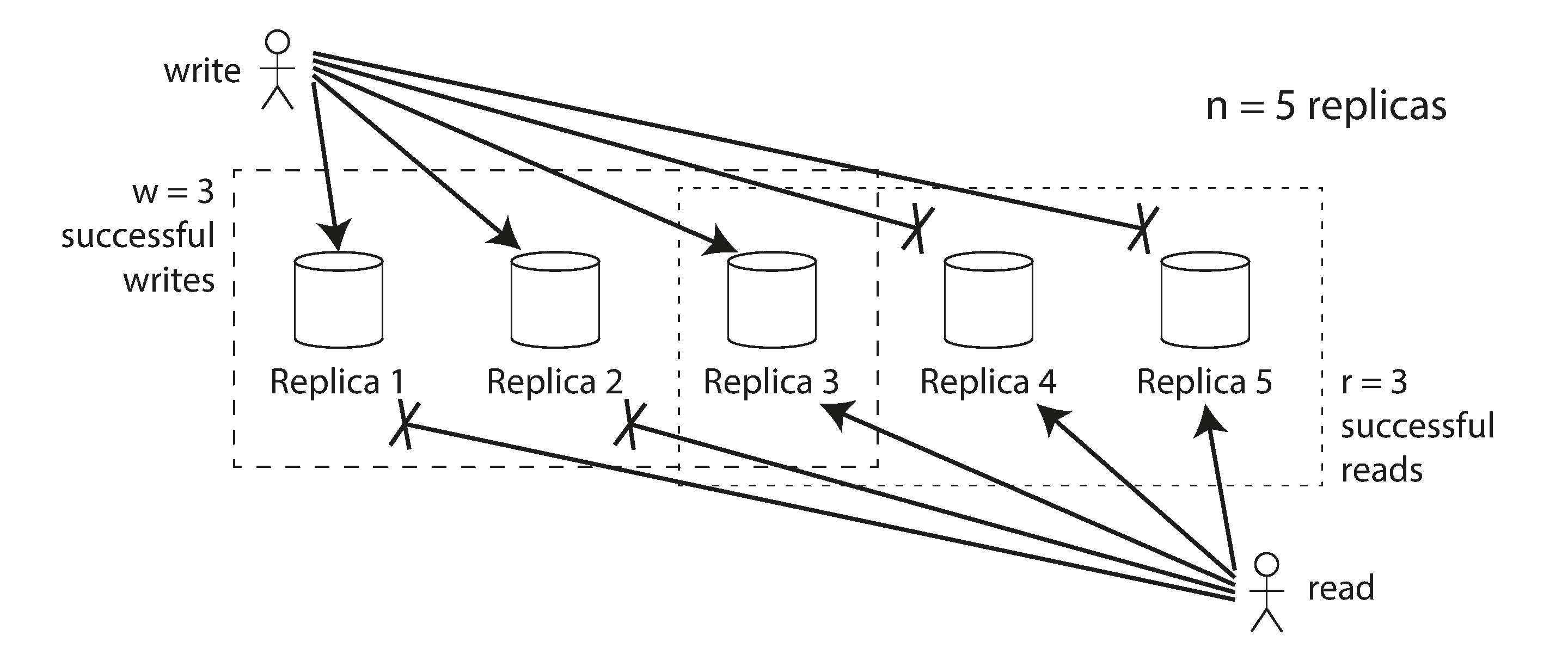
更一般地说,如果有 n 个副本,每次写入必须由 w 个节点确认才能被认为成功,并且我们必须为每次读取查询至少 r 个节点。(在我们的例子中,n = 3,w = 2,r = 2。)只要 w + r > n,我们在读取时期望获得最新值,因为我们读取的 r 个节点中至少有一个必须是最新的。遵守这些 r 和 w 值的读取和写入称为 仲裁 读取和写入 50。你可以将 r 和 w 视为读取或写入有效所需的最小投票数。
在 Dynamo 风格的数据库中,参数 n、w 和 r 通常是可配置的。常见的选择是使 n 为奇数(通常为 3 或 5),并设置 w = r = (n + 1) / 2(向上舍入)。然而,你可以根据需要更改数字。例如,写入很少而读取很多的工作负载可能受益于设置 w = n 和 r = 1。这使读取更快,但缺点是仅一个失败的节点就会导致所有数据库写入失败。
Note
集群中可能有超过 n 个节点,但任何给定值仅存储在 n 个节点上。这允许数据集进行分片,支持比单个节点能容纳的更大的数据集。我们将在 第 7 章 中回到分片。
仲裁条件 w + r > n 允许系统容忍不可用节点,如下所示:
- 如果 w < n,如果节点不可用,我们仍然可以处理写入。
- 如果 r < n,如果节点不可用,我们仍然可以处理读取。
- 使用 n = 3,w = 2,r = 2,我们可以容忍一个不可用节点,如 图 6-12 中所示。
- 使用 n = 5,w = 3,r = 3,我们可以容忍两个不可用节点。这种情况在 图 6-13 中说明。
通常,读取和写入总是并行发送到所有 n 个副本。参数 w 和 r 确定我们等待多少个节点——即,在我们认为读取或写入成功之前,n 个节点中有多少个需要报告成功。
如果少于所需的 w 或 r 个节点可用,写入或读取将返回错误。节点可能因许多原因不可用:因为节点宕机(崩溃、断电)、由于执行操作时出错(无法写入因为磁盘已满)、由于客户端和节点之间的网络中断,或任何其他原因。我们只关心节点是否返回了成功响应,不需要区分不同类型的故障。
仲裁一致性的局限
如果你有 n 个副本,并且你选择 w 和 r 使得 w + r > n,你通常可以期望每次读取都返回为键写入的最新值。这是因为你写入的节点集和你读取的节点集必须重叠。也就是说,在你读取的节点中,必须至少有一个具有最新值的节点(如 图 6-13 所示)。
通常,r 和 w 被选择为多数(超过 n/2)节点,因为这确保了 w + r > n,同时仍然容忍最多 n/2(向下舍入)个节点故障。但仲裁不一定是多数——重要的是读取和写入操作使用的节点集至少在一个节点中重叠。其他仲裁分配是可能的,这允许分布式算法设计中的一些灵活性 51。
你也可以将 w 和 r 设置为较小的数字,使得 w + r ≤ n(即,不满足仲裁条件)。在这种情况下,读取和写入仍将发送到 n 个节点,但需要较少的成功响应数才能使操作成功。
使用较小的 w 和 r,你更有可能读取陈旧值,因为你的读取更可能没有包含具有最新值的节点。从好的方面来说,这种配置允许更低的延迟和更高的可用性:如果存在网络中断并且许多副本变得无法访问,你继续处理读取和写入的机会更高。只有在可访问副本的数量低于 w 或 r 之后,数据库才分别变得无法写入或读取。
然而,即使使用 w + r > n,在某些边缘情况下,一致性属性可能会令人困惑。一些场景包括:
- 如果携带新值的节点失败,并且其数据从携带旧值的副本恢复,存储新值的副本数量可能低于 w,破坏仲裁条件。
- 在重新平衡正在进行时,其中一些数据从一个节点移动到另一个节点(见 第 7 章),节点可能对哪些节点应该持有特定值的 n 个副本有不一致的视图。这可能导致读取和写入仲裁不再重叠。
- 如果读取与写入操作并发,读取可能会或可能不会看到并发写入的值。特别是,一次读取可能看到新值,而后续读取看到旧值,正如我们将在 “线性一致性与仲裁” 中看到的。
- 如果写入在某些副本上成功但在其他副本上失败(例如,因为某些节点上的磁盘已满),并且总体上在少于 w 个副本上成功,它不会在成功的副本上回滚。这意味着如果写入被报告为失败,后续读取可能会或可能不会返回该写入的值 52。
- 如果数据库使用实时时钟的时间戳来确定哪个写入更新(如 Cassandra 和 ScyllaDB 所做的),如果另一个具有更快时钟的节点已写入同一键,写入可能会被静默丢弃——我们之前在 “最后写入胜利(丢弃并发写入)” 中看到的问题。我们将在 “依赖同步时钟” 中更详细地讨论这一点。
- 如果两个写入并发发生,其中一个可能首先在一个副本上处理,另一个可能首先在另一个副本上处理。这导致冲突,类似于我们在多主复制中看到的(见 “处理写入冲突”)。我们将在 “检测并发写入” 中回到这个主题。
因此,尽管仲裁似乎保证读取返回最新写入的值,但实际上并不那么简单。Dynamo 风格的数据库通常针对可以容忍最终一致性的用例进行了优化。参数 w 和 r 允许你调整读取陈旧值的概率 53,但明智的做法是不要将它们视为绝对保证。
监控陈旧性
从操作角度来看,监控你的数据库是否返回最新结果很重要。即使你的应用程序可以容忍陈旧读取,你也需要了解复制的健康状况。如果它明显落后,它应该提醒你,以便你可以调查原因(例如,网络中的问题或过载的节点)。
对于基于领导者的复制,数据库通常公开复制延迟的指标,你可以将其输入到监控系统。这是可能的,因为写入以相同的顺序应用于领导者和追随者,每个节点在复制日志中都有一个位置(它在本地应用的写入数)。通过从领导者的当前位置减去追随者的当前位置,你可以测量复制延迟的量。
然而,在具有无主复制的系统中,没有固定的写入应用顺序,这使得监控更加困难。副本为移交存储的提示数量可以是系统健康的一个度量,但很难有用地解释 54。最终一致性是一个故意模糊的保证,但为了可操作性,能够量化"最终"很重要。
单主与无主复制的性能
基于单个领导者的复制系统可以提供在无主系统中难以或不可能实现的强一致性保证。然而,正如我们在 “复制延迟的问题” 中看到的,如果你在异步更新的追随者上进行读取,基于领导者的复制系统中的读取也可能返回陈旧值。
从领导者读取确保最新响应,但它存在性能问题:
- 读取吞吐量受领导者处理请求能力的限制(与读扩展相反,读扩展将读取分布在可能返回陈旧值的异步更新副本上)。
- 如果领导者失败,你必须等待检测到故障,并在继续处理请求之前完成故障转移。即使故障转移过程非常快,用户也会因为临时增加的响应时间而注意到它;如果故障转移需要很长时间,系统在其持续时间内不可用。
- 系统对领导者上的性能问题非常敏感:如果领导者响应缓慢,例如由于过载或某些资源争用,增加的响应时间也会立即影响用户。
无主架构的一大优势是它对此类问题更有弹性。因为没有故障转移,而且请求本来就是并行发往多个副本,所以某个副本变慢或不可用对响应时间影响较小:客户端只需采用更快副本的响应即可。利用最快响应的做法称为 请求对冲,它可以显著降低尾部延迟 55。
从根本上说,无主系统的弹性来自于它不区分正常情况和故障情况的事实。这在处理所谓的 灰色故障 时特别有用,其中节点没有完全宕机,但以降级状态运行,处理请求异常缓慢 56,或者当节点只是过载时(例如,如果节点已离线一段时间,通过提示移交恢复可能会导致大量额外负载)。基于领导者的系统必须决定情况是否足够糟糕以保证故障转移(这本身可能会导致进一步的中断),而在无主系统中,这个问题甚至不会出现。
也就是说,无主系统也可能有性能问题:
- 即使系统不需要执行故障转移,一个副本确实需要检测另一个副本何时不可用,以便它可以存储有关不可用副本错过的写入的提示。当不可用副本恢复时,移交过程需要向其发送这些提示。这在系统已经处于压力下时给副本带来了额外的负载 54。
- 你拥有的副本越多,你的仲裁就越大,在请求完成之前你必须等待的响应就越多。即使你只等待最快的 r 或 w 个副本响应,即使你并行发出请求,更大的 r 或 w 增加了你遇到慢副本的机会,增加了总体响应时间(见 “响应时间指标的应用”)。
- 大规模网络中断使客户端与大量副本断开连接,可能使形成仲裁变得不可能。一些无主数据库提供了一个配置选项,允许任何可访问的副本接受写入,即使它不是该键的通常副本之一(Riak 和 Dynamo 称之为 宽松仲裁 45;Cassandra 和 ScyllaDB 称之为 一致性级别 ANY)。不能保证后续读取会看到写入的值,但根据应用程序,它可能仍然比写入失败更好。
多主复制可以提供比无主复制更大的网络中断弹性,因为读取和写入只需要与一个领导者通信,该领导者可以与客户端位于同一位置。然而,由于一个领导者上的写入异步传播到其他领导者,读取可能任意过时。仲裁读取和写入提供了一种折衷:良好的容错性,同时也有很高的可能性读取最新数据。
多地区操作
我们之前讨论了跨地区复制作为多主复制的用例(见 “多主复制”)。无主复制也适合多地区操作,因为它被设计为容忍冲突的并发写入、网络中断和延迟峰值。
Cassandra 和 ScyllaDB 在正常的无主模型中实现了它们的多地区支持:客户端直接将其写入发送到所有地区的副本,你可以从各种一致性级别中进行选择,这些级别确定请求成功所需的响应数。例如,你可以请求所有地区中副本的仲裁、每个地区中的单独仲裁,或仅客户端本地地区的仲裁。本地仲裁避免了必须等待到其他地区的缓慢请求,但它也更可能返回陈旧结果。
Riak 将客户端和数据库节点之间的所有通信保持在一个地区本地,因此 n 描述了一个地区内的副本数。数据库集群之间的跨地区复制在后台异步发生,其风格类似于多主复制。
检测并发写入
与多主复制一样,无主数据库允许对同一键进行并发写入,导致需要解决的冲突。此类冲突可能在写入发生时发生,但并非总是如此:它们也可能在读修复、提示移交或反熵期间稍后检测到。
问题在于,由于可变的网络延迟和部分故障,事件可能以不同的顺序到达不同的节点。例如,图 6-14 显示了两个客户端 A 和 B 同时写入三节点数据存储中的键 X:
- 节点 1 接收来自 A 的写入,但由于瞬时中断从未接收来自 B 的写入。
- 节点 2 首先接收来自 A 的写入,然后接收来自 B 的写入。
- 节点 3 首先接收来自 B 的写入,然后接收来自 A 的写入。
如果每个节点在接收到来自客户端的写入请求时只是覆盖键的值,节点将变得永久不一致,如 图 6-14 中的最终 get 请求所示:节点 2 认为 X 的最终值是 B,而其他节点认为值是 A。
为了最终保持一致,副本应该收敛到相同的值。为此,我们可以使用我们之前在 “处理写入冲突” 中讨论的任何冲突解决机制,例如最后写入胜利(由 Cassandra 和 ScyllaDB 使用)、手动解决或 CRDT(在 “CRDT 与操作变换” 中描述,并由 Riak 使用)。
最后写入胜利很容易实现:每个写入都标有时间戳,具有更高时间戳的值总是覆盖具有较低时间戳的值。然而,时间戳不会告诉你两个值是否实际上冲突(即,它们是并发写入的)或不冲突(它们是一个接一个写入的)。如果你想显式解决冲突,系统需要更加小心地检测并发写入。
“先发生"关系与并发
我们如何决定两个操作是否并发?为了培养直觉,让我们看一些例子:
- 在 图 6-8 中,两个写入不是并发的:A 的插入 先发生于 B 的递增,因为 B 递增的值是 A 插入的值。换句话说,B 的操作建立在 A 的操作之上,所以 B 的操作必须稍后发生。我们也说 B 因果依赖 于 A。
- 另一方面,图 6-14 中的两个写入是并发的:当每个客户端开始操作时,它不知道另一个客户端也在对同一键执行操作。因此,操作之间没有因果依赖关系。
如果操作 B 知道 A,或依赖于 A,或以某种方式建立在 A 之上,则操作 A 先发生于 另一个操作 B。一个操作是否先发生于另一个操作是定义并发含义的关键。事实上,我们可以简单地说,如果两个操作都不先发生于另一个(即,两者都不知道另一个),则它们是 并发的 57。
因此,每当你有两个操作 A 和 B 时,有三种可能性:要么 A 先发生于 B,要么 B 先发生于 A,要么 A 和 B 是并发的。我们需要的是一个算法来告诉我们两个操作是否并发。如果一个操作先发生于另一个,后面的操作应该覆盖前面的操作,但如果操作是并发的,我们有一个需要解决的冲突。
并发、时间和相对论
似乎两个操作如果"同时"发生,应该称为并发——但实际上,它们是否真的在时间上重叠并不重要。由于分布式系统中的时钟问题,实际上很难判断两件事是否恰好在同一时间发生——我们将在 第 9 章 中更详细地讨论这个问题。
为了定义并发,确切的时间并不重要:我们只是称两个操作并发,如果它们都不知道对方,无论它们发生的物理时间如何。人们有时将这一原则与物理学中的狭义相对论联系起来 57,它引入了信息不能比光速传播更快的想法。因此,如果两个事件之间的时间短于光在它们之间传播的时间,那么相隔一定距离发生的两个事件不可能相互影响。
在计算机系统中,即使光速原则上允许一个操作影响另一个,两个操作也可能是并发的。例如,如果网络在当时很慢或中断,两个操作可以相隔一段时间发生,仍然是并发的,因为网络问题阻止了一个操作能够知道另一个。
捕获先发生关系
让我们看一个确定两个操作是否并发或一个先发生于另一个的算法。为了简单起见,让我们从只有一个副本的数据库开始。一旦我们弄清楚如何在单个副本上执行此操作,我们就可以将该方法推广到具有多个副本的无主数据库。
图 6-15 显示了两个客户端并发地向同一购物车添加项目。(如果这个例子让你觉得太无聊,想象一下两个空中交通管制员并发地向他们正在跟踪的扇区添加飞机。)最初,购物车是空的。两个客户端总共向数据库发起了五次写入:
- 客户端 1 将
milk添加到购物车。这是对该键的第一次写入,因此服务器成功存储它并为其分配版本 1。服务器还将值连同版本号一起回显给客户端。 - 客户端 2 将
eggs添加到购物车,不知道客户端 1 并发地添加了milk(客户端 2 认为它的eggs是购物车中的唯一项目)。服务器为此写入分配版本 2,并将eggs和milk存储为两个单独的值(兄弟)。然后,它将 两个 值连同版本号 2 一起返回给客户端。 - 客户端 1,不知道客户端 2 的写入,想要将
flour添加到购物车,因此它认为当前购物车内容应该是[milk, flour]。它将此值连同服务器之前给客户端 1 的版本号 1 一起发送到服务器。服务器可以从版本号判断[milk, flour]的写入取代了[milk]的先前值,但它与[eggs]并发。因此,服务器将版本 3 分配给[milk, flour],覆盖版本 1 值[milk],但保留版本 2 值[eggs]并将两个剩余值返回给客户端。 - 同时,客户端 2 想要将
ham添加到购物车,不知道客户端 1 刚刚添加了flour。客户端 2 在上次响应中从服务器接收了两个值[milk]和[eggs],因此客户端现在合并这些值并添加ham以形成新值[eggs, milk, ham]。它将该值连同先前的版本号 2 一起发送到服务器。服务器检测到版本 2 覆盖[eggs]但与[milk, flour]并发,因此两个剩余值是版本 3 的[milk, flour]和版本 4 的[eggs, milk, ham]。 - 最后,客户端 1 想要添加
bacon。它之前从服务器接收了版本 3 的[milk, flour]和[eggs],因此它合并这些,添加bacon,并将最终值[milk, flour, eggs, bacon]连同版本号 3 一起发送到服务器。这覆盖了[milk, flour](注意[eggs]已经在上一步中被覆盖)但与[eggs, milk, ham]并发,因此服务器保留这两个并发值。
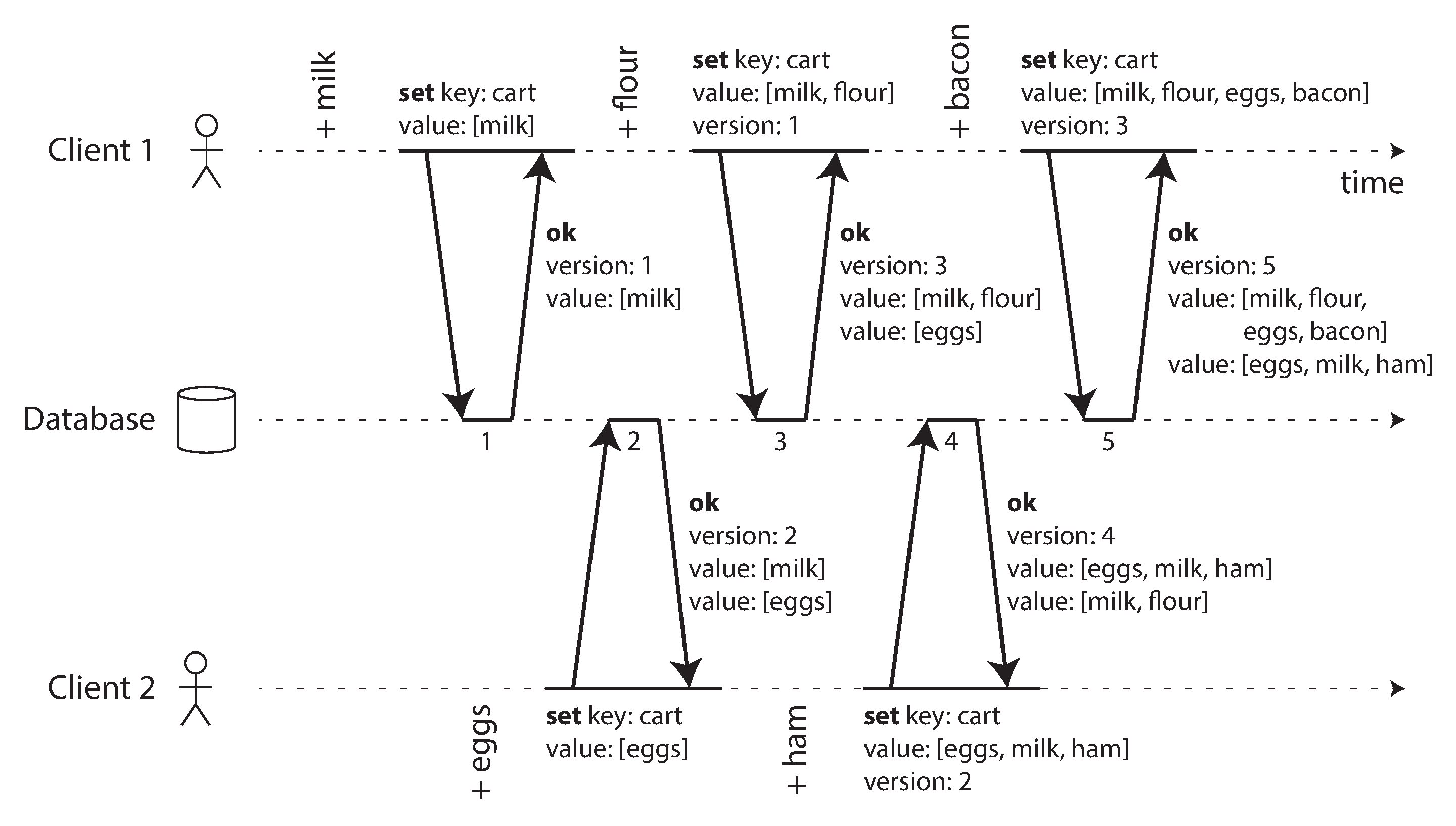
图 6-15 中操作之间的数据流在 图 6-16 中以图形方式说明。箭头指示哪个操作 先发生于 哪个其他操作,即后面的操作 知道 或 依赖于 前面的操作。在这个例子中,客户端从未完全了解服务器上的数据,因为总是有另一个并发进行的操作。但是值的旧版本最终会被覆盖,并且不会丢失任何写入。
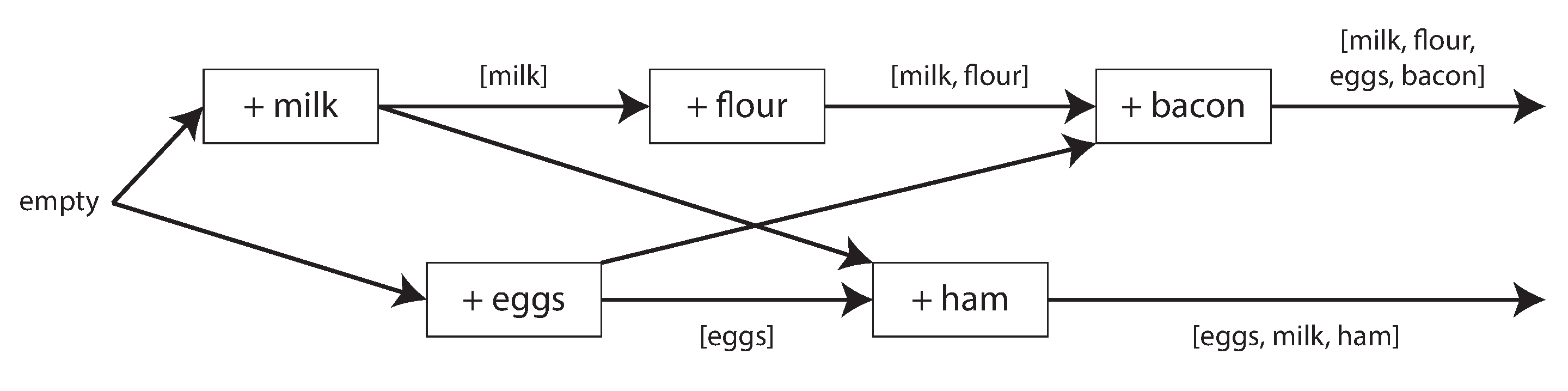
请注意,服务器可以通过查看版本号来确定两个操作是否并发——它不需要解释值本身(因此值可以是任何数据结构)。算法的工作原理如下:
- 服务器为每个键维护一个版本号,每次写入该键时递增版本号,并将新版本号与写入的值一起存储。
- 当客户端读取键时,服务器返回所有兄弟,即所有未被覆盖的值,以及最新的版本号。客户端必须在写入之前读取键。
- 当客户端写入键时,它必须包含来自先前读取的版本号,并且必须合并它在先前读取中收到的所有值,例如使用 CRDT 或通过询问用户。写入请求的响应就像读取一样,返回所有兄弟,这允许我们像购物车示例中那样链接多个写入。
- 当服务器接收到具有特定版本号的写入时,它可以覆盖具有该版本号或更低版本号的所有值(因为它知道它们已合并到新值中),但它必须保留具有更高版本号的所有值(因为这些值与传入写入并发)。
当写入包含来自先前读取的版本号时,这告诉我们写入基于哪个先前状态。如果你在不包含版本号的情况下进行写入,它与所有其他写入并发,因此它不会覆盖任何内容——它只会作为后续读取的值之一返回。
版本向量
图 6-15 中的示例只使用了单个副本。当存在多个副本、且没有领导者时,算法如何变化?
图 6-15 使用单个版本号来捕获操作间依赖关系,但当多个副本并发接受写入时,这还不够。我们需要为 每个副本、每个键分别维护版本号。每个副本在处理写入时递增自己的版本号,并追踪从其他副本看到的版本号。这些信息决定了哪些值该被覆盖,哪些值要作为兄弟保留。
来自所有副本的版本号集合称为 版本向量 58。这一思想有若干变体,其中较有代表性的是 点版本向量 59 60,Riak 2.0 使用了它 61 62。这里不展开细节,它的工作方式与前面的购物车示例非常相似。
和 图 6-15 里的版本号一样,版本向量会在读取时由数据库副本返回给客户端,并在后续写入时再由客户端带回数据库。(Riak 把版本向量编码成一个字符串,称为 因果上下文。)版本向量让数据库能够区分“覆盖写入”和“并发写入”。
版本向量还保证了“从一个副本读取,再写回另一个副本”是安全的。这样做可能会产生兄弟,但只要正确合并兄弟,就不会丢失数据。
总结
在本章中,我们研究了复制问题。复制可以服务于多种目的:
- 高可用性
- 即使一台机器(或几台机器、一个区域,甚至整个地区)宕机,也能保持系统运行
- 断开操作
- 允许应用程序在网络中断时继续工作
- 延迟
- 将数据在地理上放置在靠近用户的位置,以便用户可以更快地与其交互
- 可伸缩性
- 通过在副本上执行读取,能够处理比单台机器能够处理的更高的读取量
尽管目标很简单——在几台机器上保留相同数据的副本——复制却是一个非常棘手的问题。它需要仔细考虑并发性以及所有可能出错的事情,并处理这些故障的后果。至少,我们需要处理不可用的节点和网络中断(这甚至还没有考虑更隐蔽的故障类型,例如由于软件错误或硬件错误导致的静默数据损坏)。
我们讨论了三种主要的复制方法:
- 单主复制
- 客户端将所有写入发送到单个节点(领导者),该节点将数据变更事件流发送到其他副本(追随者)。读取可以在任何副本上执行,但从追随者读取可能是陈旧的。
- 多主复制
- 客户端将每个写入发送到几个领导者之一,任何领导者都可以接受写入。领导者相互发送数据变更事件流,并发送到任何追随者。
- 无主复制
- 客户端将每个写入发送到多个节点,并行从多个节点读取,以检测和纠正具有陈旧数据的节点。
每种方法都有优缺点。单主复制很受欢迎,因为它相当容易理解,并且提供强一致性。多主和无主复制在存在故障节点、网络中断和延迟峰值时可以更加健壮——代价是需要冲突解决并提供较弱的一致性保证。
复制可以是同步的或异步的,这对系统在出现故障时的行为有深远的影响。尽管异步复制在系统平稳运行时可能很快,但重要的是要弄清楚当复制延迟增加和服务器失败时会发生什么。如果领导者失败并且你将异步更新的追随者提升为新的领导者,最近提交的数据可能会丢失。
我们研究了复制延迟可能导致的一些奇怪效果,并讨论了一些有助于决定应用程序在复制延迟下应如何表现的一致性模型:
- 写后读一致性
- 用户应该始终看到他们自己提交的数据。
- 单调读
- 在用户在某个时间点看到数据后,他们不应该稍后从某个较早的时间点看到数据。
- 一致前缀读
- 用户应该看到处于因果意义状态的数据:例如,按正确顺序看到问题及其回复。
最后,我们讨论了多主和无主复制如何确保所有副本最终收敛到一致状态:通过使用版本向量或类似算法来检测哪些写入是并发的,并通过使用冲突解决算法(如 CRDT)来合并并发写入的值。最后写入胜利和手动冲突解决也是可能的。
本章假设每个副本都存储整个数据库的完整副本,这对于大型数据集是不现实的。在下一章中,我们将研究 分片,它允许每台机器只存储数据的子集。
参考
B. G. Lindsay, P. G. Selinger, C. Galtieri, J. N. Gray, R. A. Lorie, T. G. Price, F. Putzolu, I. L. Traiger, and B. W. Wade. Notes on Distributed Databases. IBM Research, Research Report RJ2571(33471), July 1979. Archived at perma.cc/EPZ3-MHDD ↩︎ ↩︎
Kenny Gryp. MySQL Terminology Updates. dev.mysql.com, July 2020. Archived at perma.cc/S62G-6RJ2 ↩︎
Oracle Corporation. Oracle (Active) Data Guard 19c: Real-Time Data Protection and Availability. White Paper, oracle.com, March 2019. Archived at perma.cc/P5ST-RPKE ↩︎
Microsoft. What is an Always On availability group? learn.microsoft.com, September 2024. Archived at perma.cc/ABH6-3MXF ↩︎
Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, and Akshat Vig. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service. At USENIX Annual Technical Conference (ATC), July 2022. ↩︎ ↩︎
Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan VanBenschoten, Jordan Lewis, Tobias Grieger, Kai Niemi, Andy Woods, Anne Birzin, Raphael Poss, Paul Bardea, Amruta Ranade, Ben Darnell, Bram Gruneir, Justin Jaffray, Lucy Zhang, and Peter Mattis. CockroachDB: The Resilient Geo-Distributed SQL Database. At ACM SIGMOD International Conference on Management of Data (SIGMOD), pages 1493–1509, June 2020. doi:10.1145/3318464.3386134 ↩︎
Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, and Xin Tang. TiDB: a Raft-based HTAP database. Proceedings of the VLDB Endowment, volume 13, issue 12, pages 3072–3084. doi:10.14778/3415478.3415535 ↩︎
Mallory Knodel and Niels ten Oever. Terminology, Power, and Inclusive Language in Internet-Drafts and RFCs. IETF Internet-Draft, August 2023. Archived at perma.cc/5ZY9-725E ↩︎
Buck Hodges. Postmortem: VSTS 4 September 2018. devblogs.microsoft.com, September 2018. Archived at perma.cc/ZF5R-DYZS ↩︎
Gunnar Morling. Leader Election With S3 Conditional Writes. www.morling.dev, August 2024. Archived at perma.cc/7V2N-J78Y ↩︎
Vignesh Chandramohan, Rohan Desai, and Chris Riccomini. SlateDB Manifest Design. github.com, May 2024. Archived at perma.cc/8EUY-P32Z ↩︎
Stas Kelvich. Why does Neon use Paxos instead of Raft, and what’s the difference? neon.tech, August 2022. Archived at perma.cc/SEZ4-2GXU ↩︎
Dimitri Fontaine. An introduction to the pg_auto_failover project. tapoueh.org, November 2021. Archived at perma.cc/3WH5-6BAF ↩︎
Jesse Newland. GitHub availability this week. github.blog, September 2012. Archived at perma.cc/3YRF-FTFJ ↩︎
Mark Imbriaco. Downtime last Saturday. github.blog, December 2012. Archived at perma.cc/M7X5-E8SQ ↩︎
John Hugg. ‘All In’ with Determinism for Performance and Testing in Distributed Systems. At Strange Loop, September 2015. ↩︎
Hironobu Suzuki. The Internals of PostgreSQL. interdb.jp, 2017. ↩︎
Amit Kapila. WAL Internals of PostgreSQL. At PostgreSQL Conference (PGCon), May 2012. Archived at perma.cc/6225-3SUX ↩︎
Amit Kapila. Evolution of Logical Replication. amitkapila16.blogspot.com, September 2023. Archived at perma.cc/F9VX-JLER ↩︎
Aru Petchimuthu. Upgrade your Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL database, Part 2: Using the pglogical extension. aws.amazon.com, August 2021. Archived at perma.cc/RXT8-FS2T ↩︎
Yogeshwer Sharma, Philippe Ajoux, Petchean Ang, David Callies, Abhishek Choudhary, Laurent Demailly, Thomas Fersch, Liat Atsmon Guz, Andrzej Kotulski, Sachin Kulkarni, Sanjeev Kumar, Harry Li, Jun Li, Evgeniy Makeev, Kowshik Prakasam, Robbert van Renesse, Sabyasachi Roy, Pratyush Seth, Yee Jiun Song, Benjamin Wester, Kaushik Veeraraghavan, and Peter Xie. Wormhole: Reliable Pub-Sub to Support Geo-Replicated Internet Services. At 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015. ↩︎
Douglas B. Terry. Replicated Data Consistency Explained Through Baseball. Microsoft Research, Technical Report MSR-TR-2011-137, October 2011. Archived at perma.cc/F4KZ-AR38 ↩︎ ↩︎ ↩︎
Douglas B. Terry, Alan J. Demers, Karin Petersen, Mike J. Spreitzer, Marvin M. Theher, and Brent B. Welch. Session Guarantees for Weakly Consistent Replicated Data. At 3rd International Conference on Parallel and Distributed Information Systems (PDIS), September 1994. doi:10.1109/PDIS.1994.331722 ↩︎ ↩︎
Werner Vogels. Eventually Consistent. ACM Queue, volume 6, issue 6, pages 14–19, October 2008. doi:10.1145/1466443.1466448 ↩︎
Simon Willison. Reply to: “My thoughts about Fly.io (so far) and other newish technology I’m getting into”. news.ycombinator.com, May 2022. Archived at perma.cc/ZRV4-WWV8 ↩︎
Nithin Tharakan. Scaling Bitbucket’s Database. atlassian.com, October 2020. Archived at perma.cc/JAB7-9FGX ↩︎
Terry Pratchett. Reaper Man: A Discworld Novel. Victor Gollancz, 1991. ISBN: 978-0-575-04979-6 ↩︎
Peter Bailis, Alan Fekete, Michael J. Franklin, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Coordination Avoidance in Database Systems. Proceedings of the VLDB Endowment, volume 8, issue 3, pages 185–196, November 2014. doi:10.14778/2735508.2735509 ↩︎
Yaser Raja and Peter Celentano. PostgreSQL bi-directional replication using pglogical. aws.amazon.com, January 2022. Archived at https://perma.cc/BUQ2-5QWN ↩︎
Robert Hodges. If You *Must* Deploy Multi-Master Replication, Read This First. scale-out-blog.blogspot.com, April 2012. Archived at perma.cc/C2JN-F6Y8 ↩︎ ↩︎
Lars Hofhansl. HBASE-7709: Infinite Loop Possible in Master/Master Replication. issues.apache.org, January 2013. Archived at perma.cc/24G2-8NLC ↩︎
John Day-Richter. What’s Different About the New Google Docs: Making Collaboration Fast. drive.googleblog.com, September 2010. Archived at perma.cc/5TL8-TSJ2 ↩︎ ↩︎
Evan Wallace. How Figma’s multiplayer technology works. figma.com, October 2019. Archived at perma.cc/L49H-LY4D ↩︎
Tuomas Artman. Scaling the Linear Sync Engine. linear.app, June 2023. ↩︎
Amr Saafan. Why Sync Engines Might Be the Future of Web Applications. nilebits.com, September 2024. Archived at perma.cc/5N73-5M3V ↩︎
Isaac Hagoel. Are Sync Engines The Future of Web Applications? dev.to, July 2024. Archived at perma.cc/R9HF-BKKL ↩︎
Sujay Jayakar. A Map of Sync. stack.convex.dev, October 2024. Archived at perma.cc/82R3-H42A ↩︎
Alex Feyerke. Designing Offline-First Web Apps. alistapart.com, December 2013. Archived at perma.cc/WH7R-S2DS ↩︎
Martin Kleppmann, Adam Wiggins, Peter van Hardenberg, and Mark McGranaghan. Local-first software: You own your data, in spite of the cloud. At ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!), October 2019, pages 154–178. doi:10.1145/3359591.3359737 ↩︎
Martin Kleppmann. The past, present, and future of local-first. At Local-First Conference, May 2024. ↩︎
Conrad Hofmeyr. API Calling is to Sync Engines as jQuery is to React. powersync.com, November 2024. Archived at perma.cc/2FP9-7WJJ ↩︎
Peter van Hardenberg and Martin Kleppmann. PushPin: Towards Production-Quality Peer-to-Peer Collaboration. At 7th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC), April 2020. doi:10.1145/3380787.3393683 ↩︎
Leonard Kawell, Jr., Steven Beckhardt, Timothy Halvorsen, Raymond Ozzie, and Irene Greif. Replicated document management in a group communication system. At ACM Conference on Computer-Supported Cooperative Work (CSCW), September 1988. doi:10.1145/62266.1024798 ↩︎
Ricky Pusch. Explaining how fighting games use delay-based and rollback netcode. words.infil.net and arstechnica.com, October 2019. Archived at perma.cc/DE7W-RDJ8 ↩︎
Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall, and Werner Vogels. Dynamo: Amazon’s Highly Available Key-Value Store. At 21st ACM Symposium on Operating Systems Principles (SOSP), October 2007. doi:10.1145/1323293.1294281 ↩︎ ↩︎ ↩︎ ↩︎
Marc Shapiro, Nuno Preguiça, Carlos Baquero, and Marek Zawirski. A Comprehensive Study of Convergent and Commutative Replicated Data Types. INRIA Research Report no. 7506, January 2011. ↩︎
Chengzheng Sun and Clarence Ellis. Operational Transformation in Real-Time Group Editors: Issues, Algorithms, and Achievements. At ACM Conference on Computer Supported Cooperative Work (CSCW), November 1998. doi:10.1145/289444.289469 ↩︎
Joseph Gentle and Martin Kleppmann. Collaborative Text Editing with Eg-walker: Better, Faster, Smaller. At 20th European Conference on Computer Systems (EuroSys), March 2025. doi:10.1145/3689031.3696076 ↩︎
Dharma Shukla. Azure Cosmos DB: Pushing the frontier of globally distributed databases. azure.microsoft.com, September 2018. Archived at perma.cc/UT3B-HH6R ↩︎
David K. Gifford. Weighted Voting for Replicated Data. At 7th ACM Symposium on Operating Systems Principles (SOSP), December 1979. doi:10.1145/800215.806583 ↩︎ ↩︎
Heidi Howard, Dahlia Malkhi, and Alexander Spiegelman. Flexible Paxos: Quorum Intersection Revisited. At 20th International Conference on Principles of Distributed Systems (OPODIS), December 2016. doi:10.4230/LIPIcs.OPODIS.2016.25 ↩︎
Joseph Blomstedt. Bringing Consistency to Riak. At RICON West, October 2012. ↩︎
Peter Bailis, Shivaram Venkataraman, Michael J. Franklin, Joseph M. Hellerstein, and Ion Stoica. Quantifying eventual consistency with PBS. The VLDB Journal, volume 23, pages 279–302, April 2014. doi:10.1007/s00778-013-0330-1 ↩︎
Colin Breck. Shared-Nothing Architectures for Server Replication and Synchronization. blog.colinbreck.com, December 2019. Archived at perma.cc/48P3-J6CJ ↩︎ ↩︎
Jeffrey Dean and Luiz André Barroso. The Tail at Scale. Communications of the ACM, volume 56, issue 2, pages 74–80, February 2013. doi:10.1145/2408776.2408794 ↩︎
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. At 16th Workshop on Hot Topics in Operating Systems (HotOS), May 2017. doi:10.1145/3102980.3103005 ↩︎
Leslie Lamport. Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, volume 21, issue 7, pages 558–565, July 1978. doi:10.1145/359545.359563 ↩︎ ↩︎
D. Stott Parker Jr., Gerald J. Popek, Gerard Rudisin, Allen Stoughton, Bruce J. Walker, Evelyn Walton, Johanna M. Chow, David Edwards, Stephen Kiser, and Charles Kline. Detection of Mutual Inconsistency in Distributed Systems. IEEE Transactions on Software Engineering, volume SE-9, issue 3, pages 240–247, May 1983. doi:10.1109/TSE.1983.236733 ↩︎
Nuno Preguiça, Carlos Baquero, Paulo Sérgio Almeida, Victor Fonte, and Ricardo Gonçalves. Dotted Version Vectors: Logical Clocks for Optimistic Replication. arXiv:1011.5808, November 2010. ↩︎
Giridhar Manepalli. Clocks and Causality - Ordering Events in Distributed Systems. exhypothesi.com, November 2022. Archived at perma.cc/8REU-KVLQ ↩︎ ↩︎
Sean Cribbs. A Brief History of Time in Riak. At RICON, October 2014. Archived at perma.cc/7U9P-6JFX ↩︎
Russell Brown. Vector Clocks Revisited Part 2: Dotted Version Vectors. riak.com, November 2015. Archived at perma.cc/96QP-W98R ↩︎
Carlos Baquero. Version Vectors Are Not Vector Clocks. haslab.wordpress.com, July 2011. Archived at perma.cc/7PNU-4AMG ↩︎
Reinhard Schwarz and Friedemann Mattern. Detecting Causal Relationships in Distributed Computations: In Search of the Holy Grail. Distributed Computing, volume 7, issue 3, pages 149–174, March 1994. doi:10.1007/BF02277859 ↩︎